오늘은 Scikit-Learn(sklearn)을 이용하여 AdaBoost 알고리즘을 통한 모형 학습 방법을 알아보고자 한다. AdaBoost는 분류와 회귀 문제 모두 적용할 수 있는데 이에 대해서 각각 알아본다.
AdaBoost에 대한 개념과 Scikit-Learn에서 의사결정나무를 학습하는 방법을 아래 포스팅에서 소개했으니 읽고 오면 좋다.
15. AdaBoost(Adaptive Boost) 알고리즘에 대해서 알아보자 with Python
15. AdaBoost(Adaptive Boost) 알고리즘에 대해서 알아보자 with Python
이번 포스팅에서는 부스팅 알고리즘의 하나인 AdaBoost 알고리즘에 대해서 공부한 내용을 정리하고 직접 구현을 해보려고 한다. 또한 sklearn에서 제공하는 AdaBoost 알고리즘과 성능을 비교해보고자
zephyrus1111.tistory.com
[Scikit-Learn] 5. 의사결정나무(Decision Tree) 만들기(feat. DecisionTreeClassifier, DecisionTreeRegressor)
[Scikit-Learn] 5. 의사결정나무(Decision Tree) 만들기(feat. DecisionTreeClassifier, DecisionTreeRegressor)
이번 포스팅에서는 Scikit-Learn(sklearn)을 이용하여 의사결정나무를 학습하고 이를 시각화하는 방법에 대해서 알아본다. 또한 결과를 시각화하는 것뿐만 아니라 노드 정보(샘플 수, 불순도, 예측값)
zephyrus1111.tistory.com
1. 분류 문제(AdaBoostClassifier)
1) 학습
붓꽃 데이터를 이용하여 AdaBoost 알고리즘을 분류문제에 적용해보자. Scikit-Learn에서는 AdaBoostClassifier 클래스를 통해 분류 모델을 학습할 수 있다.
AdaBoostClassifier는 base_learner를 통해 기본 분류기를 지정할 수 있다. 디폴트로는 최대 깊이 1(max_depth=1)을 갖는 분류 나무인 DecisionTreeClassifier 클래스로 지정되어 있다. 그리고 n_estimators를 통해 반복수(또는 분류기 개수)를 지정할 수 있고 learning_rate를 통해 스텝사이즈를 지정할 수 있다. 자세한 설명은 Scikit-Learn 개발 문서를 참고하자.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
from sklearn.datasets import load_iris, load_boston
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
from sklearn.tree import plot_tree
from sklearn.ensemble import AdaBoostClassifier, AdaBoostRegressor
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = [iris.target_names[x] for x in iris.target]
X = df.drop('species', axis=1)
y = df['species']
clf = AdaBoostClassifier(
## base_estimator에는 LogisticRegression() 이런 것도 쓸 수 있어요.
base_estimator=DecisionTreeClassifier(max_depth=2,
min_samples_leaf=10),
n_estimators=5, ## 반복수 또는 base_estimator 개수
learning_rate=0.5, ## 스텝 사이즈
random_state=100
).fit(X,y)
학습이 끝난 뒤에는 여러 가지 결과를 볼 수 있다. 아래 코드는 내가 자주 사용하는 predict(예측), feature_importances_(변수 중요도), get_params(클래스 정보), score(평가 측도) 메서드와 속성들의 사용법을 나타낸 것이다.
## 예측
print(clf.predict(X)[:3])
## 변수 중요도
for i, col in enumerate(X.columns):
print(f'{col} 중요도 : {clf.feature_importances_[i]}')
print(clf.get_params()) ## AdaBoostClassifier 클래스 인자 설정 정보
print('정확도 : ', clf.score(X,y)) ## 성능 평가 점수(정확도 Accuracy)
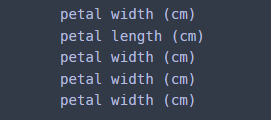
또한 base_learner(base_estimator와 같은 말)가 의사결정나무인 경우 각 나무에서 루트 노드의 분리 변수를 보는 방법도 추가해놓았으니 참고해보기 바란다. n_estimators를 5로 설정했기 때문에 5개의 분리 변수가 출력된다.
for i in range(len(clf.estimators_)):
ind_est = clf.estimators_[i]
col_idx = ind_est.tree_.feature[0]
print(X.columns[col_idx]) ## 루트 노드에서의 분리 변수
2) 시각화
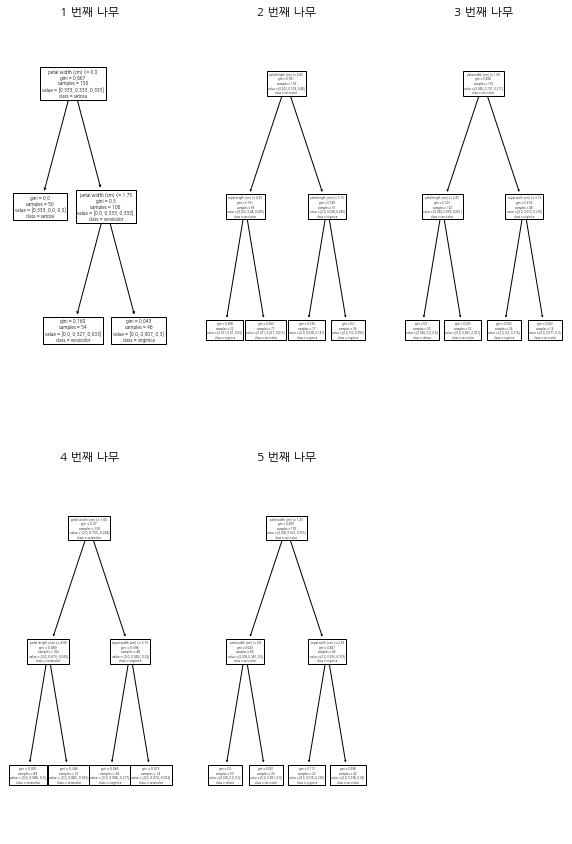
만약 base_estimator가 의사결정나무이고 반복수(또는 분류기 개수)가 적다면(5개 이하) 의사결정나무를 순차적으로 그려볼 수 있다.
n_estimator = len(clf.estimators_)
fig = plt.figure(figsize=(10, 15), facecolor='white')
row_num=2
col_num=3
for i in range(n_estimator):
ax = fig.add_subplot(row_num, col_num, i+1)
plot_tree(clf.estimators_[i],
feature_names=X.columns, ## 박스에 변수 이름 표시
class_names=clf.classes_, ## 클래스 이름(범주 이름)
ax=ax
)
ax.set_title(f'{i+1} 번째 나무')
plt.show()
2. 회귀 문제(AdaBoostRegressor)
보스턴 집값 데이터를 이용하여 AdaBoost 알고리즘을 회귀 문제에 적용해보자. Scikit-Learn에서는 AdaBoostRegressor를 이용하여 회귀 모델을 학습할 수 있다.
사용법은 AdaBoostClassifier와 거의 동일하므로 여기서 자세한 설명은 생략한다.
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df['MEDV'] = boston.target
X = df.drop('MEDV', axis=1)
y = df['MEDV']
reg = AdaBoostRegressor(
base_estimator=DecisionTreeRegressor(
criterion='friedman_mse',
max_depth=2,
min_samples_leaf=10
), ## base_learner
n_estimators=50, ## 분류기 개수
random_state=100
).fit(X,y)
학습이 끝났으면 예측, 변수 중요도 성능 평가 등을 할 수 있다.
## 예측
print(reg.predict(X)[:3])
## 변수 중요도
for i, col in enumerate(X.columns):
print(f'{col} 중요도 : {reg.feature_importances_[i]}')
print(reg.get_params()) ## AdaBoostRegressor 클래스 인자 설정 정보
print('정확도 : ', reg.score(X,y)) ## 성능 평가 점수(R-square)
분류 문제에서 살펴본 각 회귀 나무의 루트 노드 분리 변수도 뽑을 수 있다.
for i in range(len(reg.estimators_)):
ind_est = reg.estimators_[i]
col_idx = ind_est.tree_.feature[0]
print(X.columns[col_idx]) ## 루트 노드에서의 분리 변수





댓글