이번 포스팅에서는 Scikit-Learn(sklearn)을 이용하여 의사결정나무를 학습하고 이를 시각화하는 방법에 대해서 알아본다. 또한 결과를 시각화하는 것뿐만 아니라 노드 정보(샘플 수, 불순도, 예측값)를 가져오는 방법에 대해서도 소개한다.
여기서는 분류 나무와 회귀 나무를 학습하는 방법을 알아본다.
1. 분류 나무(DecisionTreeClassifier)
2. 회귀 나무(DecisionTreeRegressor)
의사결정나무에 대한 개념은 아래 포스팅을 참고하기 바란다.
9. 의사결정나무(Decision Tree) 에 대해서 알아보자 with Python
9. 의사결정나무(Decision Tree) 에 대해서 알아보자 with Python
이번 포스팅에서는 모형의 해석이 쉽다는 장점을 가진 의사결정나무를 공부한 내용을 포스팅하려고 한다. 의사결정이 무엇인지 알아보고 의사결정나무 모형을 직접 구현하는 방법을 소개하고
zephyrus1111.tistory.com
1. 분류 나무(DecisionTreeClassifier)
1) 학습
여기에서는 붓꽃데이터(Iris Data)를 이용하여 분류 나무를 학습한다.
import pandas as pd import numpy as np import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') from sklearn.datasets import load_iris, load_boston from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor from sklearn.tree import plot_tree iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['species'] = [iris.target_names[x] for x in iris.target]
Scikit-Learn에서는 DecisionTreeClassifier 클래스를 이용하여 분류 나무를 학습할 수 있다. 이 클래스를 생성할 때 몇 가지 인자를 설정할 수 있다. 주로 사용하는 인자는 불순도 측도(criterion), 분리 방법(splitter), 최대 깊이(max_depth), 최소 끝마디 샘플수(min_sample_leaf)이다. 어떤 인자들이 더 있는지 궁금한 분들은 여기를 참고하기 바란다. 이때 분리 방법에는 'best'와 'random' 두가지를 선택할 수 있는데 'best'는 모든 분리 후보들 중에서 최적 분리값을 계산하고 'random'은 임의의 분리 후보를 랜덤 추출하고 추출된 후보 중에서 최적 분리 기준을 뽑아낸다.
X = df.drop('species', axis=1) y = df['species'] clf = DecisionTreeClassifier( criterion='entropy', ## 'gini', 'log_loss' splitter='best', ## 'random' max_depth=3, ## '최대 깊이' min_samples_leaf=5, ## 최소 끝마디 샘플 수 random_state=100 ).fit(X,y)
학습이 끝났을 경우 그 결과를 볼 수 있는 메서드들이 많다.
내가 많이 쓰는 메서드와 속성들은 다음과 같고 각각 예측, 변수 중요도, DecisionTreeClassifier 클래스 인자 정보, 성능 점수를 보여준다
predict, feature_importances_, get_params, score
## 예측 print(clf.predict(X)[:3]) ## 변수 중요도 for i, col in enumerate(X.columns): print(f'{col} 중요도 : {clf.feature_importances_[i]}') print(clf.get_params()) ## DecisionTreeClassifier 클래스 인자 설정 정보 print('정확도 : ', clf.score(X,y)) ## 성능 평가 점수(정확도 Accuracy)
2) 시각화
Scikit-Learn에서 제공하는 plot_tree를 이용하여 나무를 시각화할 수 있다. 이 때 feature_names 인자는 각 노드에 분리되는 변수를 나타내고 class_names는 분류 나무인 경우 해당 노드의 예측 라벨명을 표시해준다. 이외에도 다른 옵션이 있는데 궁금하신 분들은 여기를 참고하기 바란다.
fig = plt.figure(figsize=(15, 10), facecolor='white') plot_tree(clf, feature_names=X.columns, ## 박스에 변수 이름 표시 class_names=clf.classes_, ## 클래스 이름(범주 이름) ) plt.show()

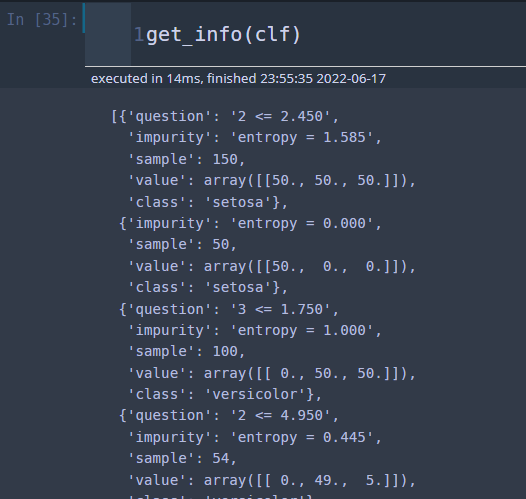
여기에서 각 노드에 있는 정보(질문, 불순도, 샘플 수 등)를 가져오는 함수도 유용하다. 설명은 주석으로 대체한다.
def get_info(dt_model, tree_type='clf'): tree = dt_model.tree_ criterion = dt_model.get_params()['criterion'] assert tree_type in ['clf', 'reg'] num_node = tree.node_count info = [] for i in range(num_node): temp_dict = dict() ## 각 정보들은 preorder 순서로 배열에 저장되어 있음. if tree.threshold[i] != -2: ## -2인 경우 끝마디이므로 질문이 없음 split_feature = tree.feature[i] split_thres = tree.threshold[i] temp_dict['question'] = f'{split_feature} <= {split_thres:.3f}' impurity = tree.impurity[i] ## 불순도 값 sample = tree.n_node_samples[i] ## 노드에 포함된 데이터 샘플 수 value = tree.value[i] temp_dict['impurity'] = f'{criterion} = {impurity:.3f}' ## 불순도 측도, 불순도 값 temp_dict['sample'] = sample temp_dict['value'] = value if tree_type == 'clf': classes = dt_model.classes_ ## 클래스 라벨 idx = np.argmax(value) ## 예측라벨 temp_dict['class'] = classes[idx] info.append(temp_dict) return info
get_info(clf)
2. 회귀 나무(DecisionTreeRegressor)
1) 학습
여기서는 보스턴 집값데이터를 사용한다.
boston = load_boston() df = pd.DataFrame(boston.data, columns=boston.feature_names) df['MEDV'] = boston.target
학습 방법은 분류 나무에서와 거의 비슷하다. 차이점은 DecisionTreeRegressor 클래스를 사용한다는 것과 criterion이 달라진다는 것이다.
X = df.drop('MEDV', axis=1) y = df['MEDV'] reg = DecisionTreeRegressor( criterion = 'squared_error', ## “squared_error”, “friedman_mse”, “absolute_error”, “poisson” splitter='best', ## 'random' max_depth=3, ## '최대 깊이' min_samples_leaf=10, ## 최소 끝마디 샘플 수 random_state=100 ).fit(X,y)
학습하고 나서 여러가지 결과를 볼 수 있다.
## 예측 print(reg.predict(X)[:3]) ## 변수 중요도 for i, col in enumerate(X.columns): print(f'{col} 중요도 : {reg.feature_importances_[i]}') print(reg.get_params()) ## DecisionTreeRegressor 클래스 인자 설정 정보 print('정확도 : ', reg.score(X,y)) ## 성능 평가 점수(R-square)
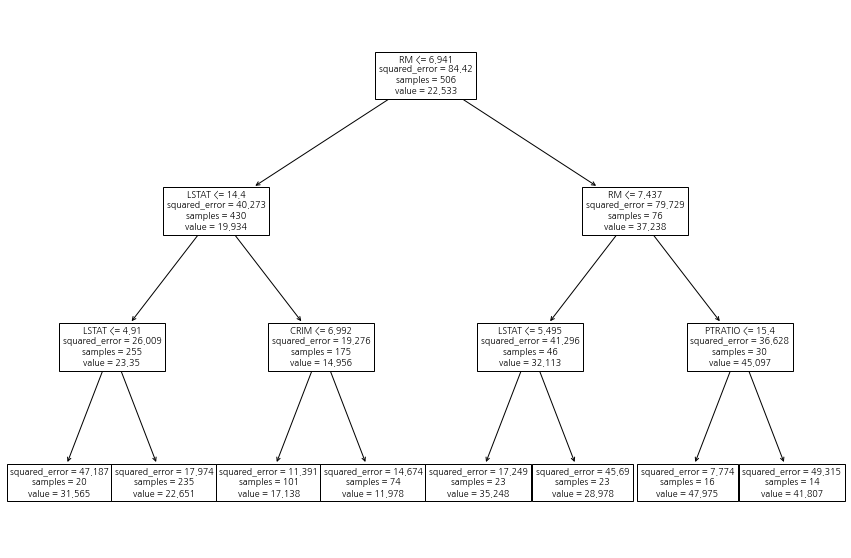
2) 시각화
시각화 방법도 분류 나무에서와 같다. 다만 class_names는 작동하지 않는다. 당연하다.
fig = plt.figure(figsize=(15, 10), facecolor='white') plot_tree(reg, feature_names=X.columns, ## 박스에 변수 이름 표시 ) plt.show()
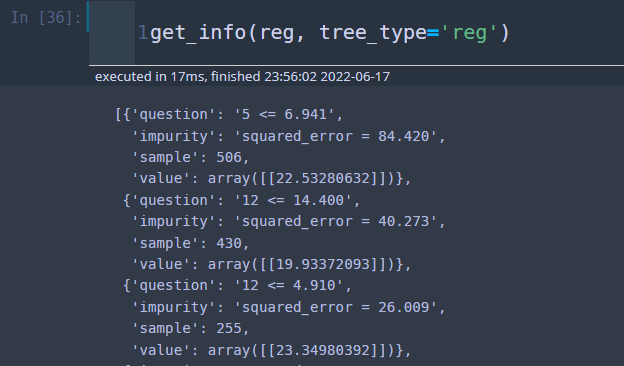
각 노드의 정보를 빼내오자.
get_info(reg, tree_type='reg')
의사결정나무는 정말 많이 활용되므로 이번 포스팅에서 다룬 내용이 많은 도움이 될 것 같다.

'프로그래밍 > Scikit-Learn' 카테고리의 다른 글
| [Scikit-Learn] 7. Gradient Boosting 모형 만들기(feat. GradientBoostingClassifier, GradientBoostingRegressor) (381) | 2022.06.18 |
|---|---|
| [Scikit-Learn] 6. AdaBoost 모형 만들기(feat. AdaBoostClassifier, AdaBoostRegressor) (403) | 2022.06.18 |
| [Scikit-Learn] 4. 서포트 벡터 머신 모형 만들기. feat SVC, SVR (401) | 2022.05.27 |
| [Scikit-Learn] 3. 데이터 칼럼 표준화하기 feat. StandardScaler (380) | 2022.05.27 |
| [Scikit-Learn] 2. 최대 최소(Min Max) 변환하기 feat. MinMaxScaler (400) | 2022.05.27 |





댓글