이번 포스팅에서는 부스팅 알고리즘의 하나인 AdaBoost 알고리즘에 대해서 공부한 내용을 정리하고 직접 구현을 해보려고 한다. 또한 sklearn에서 제공하는 AdaBoost 알고리즘과 성능을 비교해보고자 한다.
이 글을 읽기 전에 의사결정나무에 대한 내용 정도는 알고 오면 좋다. 아래에 포스팅한 것이 있으니 참고하면 좋다.
9. 의사결정나무(Decision Tree) 에 대해서 알아보자 with Python
9. 의사결정나무(Decision Tree) 에 대해서 알아보자 with Python
이 곳은 꽁냥이가 머신러닝을 공부한 내용을 정리하는 곳입니다. 이 포스팅에서는 수식을 포함하고 있습니다. 티스토리 피드에서는 수식이 제대로 표시되지 않을 수 있으니 웹브라우저 또는 모
zephyrus1111.tistory.com
여기서 다루는 내용은 다음과 같다.
1. AdaBoost(Adaptive Boost) 이란?
2. AdaBoost(Adaptive Boost) 알고리즘
3. AdaBoost(Adaptive Boost) 장단점
이 곳은 꽁냥이가 머신러닝을 공부한 내용을 정리하는 곳입니다.
이 포스팅에서는 수식을 포함하고 있습니다. 티스토리 피드에서는 수식이 제대로 표시되지 않을 수 있으니 웹브라우저 또는 모바일 웹브라우저로 보시길 바랍니다.
1. AdaBoost(Adaptive Boost) 이란?
AdaBoost의 정의는 다음과 같다.
AdaBoost은 Adaptive Boost의 준말로 초기 모형을 약한 모형(Weak Learner)으로 설정하며 매 스텝마다 가중치를 이용하여 이전 모형의 약점을 보완하는 새로운 모형을 순차적으로 적합한 뒤 최종적으로 이들을 선형 결합하여 얻어진 모형을 생성시키는 알고리즘이다.
부스팅(Boosting)은 약한 모형(Weak Learner)를 이용하여 강한 모형(Strong Learner)을 만들어내는 것이 특징인 알고리즘이다. AdaBoost는 초기 모형을 아주 약한 모형(Weak Learner)으로 설정한 뒤 매 스텝(Step)마다 이전 모형의 약점을 보완하는 새로운 모형을 순차적으로 적합시킨다.
※참고※
모형의 약점은 예측을 제대로 하지 못한 데이터(어찌보면 비정상적인 데이터)가 존재함을 의미한다. AdaBoost 알고리즘은 이러한 비정상적 데이터에 빠르게 적응하여 예측력이 강한 모델을 실시간으로 학습한다고 하여 Adaptive라는 단어가 붙게 되었다.
AdaBoost은 매 스텝마다 이전 학습데이터에서 오차가 크거나 오분류된 데이터의 가중치를 크게 한다. 반대로 오차가 작거나 정분류된 데이터의 가중치를 낮게 한다. 이러한 가중치에 비례하여 새로운 학습 데이터를 복원 추출하여 새로운 학습 데이터를 만들고 모형을 적합한다.
이는 AdaBoost은 이전 모형이 제대로 예측하지 못한 데이터에 더 집중하여 이들을 더 잘 예측하는 모형을 만들게된다(약점을 보완한다는 것이 이런 의미이다).
이렇게 매 스텝마다 얻어진 모형들을 선형 결합한 것이 AdaBoost알고리즘을 통해 얻게되는 최종 모형이다. 즉, AdaBoost은 약한 모형으로부터 시작하여 이전 모형의 약점을 보완한 새로운 모형들의 선형 결합을 통해 강한 모형을 얻는다는 점에서 AdaBoost은 부스팅(Boosting) 알고리즘인 것이다.
AdaBoost 알고리즘은 분류 문제(Classification), 회귀 문제(Regression)에 모두 적용 가능하며 이에 대한 개념과 알고리즘은 아래에서 자세하게 다룬다.
2. AdaBoost(Adaptive Boost) 알고리즘
AdaBoost 알고리즘은 분류 문제(Classification), 회귀 문제(Regression)에 모두 적용가능하다. 먼저 분류 문제에 대한 내용을 소개한 다음 회귀 문제에 적용하는 방법을 알아본다.
2.1 AdaBoost 분류기
AdaBoosting 분류기를 만들어내는 알고리즘은 기존 이진 분류(Binary Class) 문제를 더 일반화한 다중 분류(Muti-Class)에 대한 알고리즘을 소개한다. 이는 Zhu, H. Zou, S. Rosset, T. Hastie의 2009년 논문 "Multi-class AdaBoost"에서 제안된 알고리즘이다.
먼저 데이터 $(x_1, c_1), \ldots, (x_n, c_n)$이 있다고 하자. 이때 $x_i$는 $p$차원 (실수) 벡터이며 $c_i \in \{1, \ldots, K \}$이다.
- 알고리즘 -
다중 분류 문제에서 AdaBoost 알고리즘은 다음과 같다. 가중치를 이용하는 방법은 weighted Gini Index 같은 것을 사용할 수 있는데 나는 가중치를 이용한 리샘플링 방법을 택했다.
Algorithm 1.
1. 초기 가중치를 다음과 같이 세팅한다.
$$w_i = \frac{1}{n}, i=1, \ldots, n$$
2. $m=1 \text{ to } M$에 대하여
(a) 학습 데이터를 이용하여 분류기 $T^{(m)}(x)$를 피팅한다. 이때 분류기 $T$는 특정 모형으로 제한하지 않는다. 즉 어떤 분류기(예: 로지스틱 분류기, 서포트 벡터 머신 분류기, CART 등)든 상관없다. 만약 CART로 의사결정나무를 분류기로 활용한다면 약한 모형을 만들기 위해 깊이는 1을 보통 사용한다.
(b) 다음을 계산한다.
$$err^{(m)} = \sum_{i=1}^nw_i I(c_i \neq T^{(m)}(x_i) )/\sum_{i=1}^nw_i$$
(c) 다음을 계산한다.
$$\alpha^{(m)} = \log \frac{1-err^{(m)} }{err^{(m)} } + \log (K-1)$$
(d) 가중치를 다음과 같이 업데이트한다.
$$w_i \longleftarrow w_i\cdot \exp (\alpha^{(m)} I(c_i \neq T^{(m)}(x_i) ) ), \text{ } i=1, \ldots, n $$
(e) 가중치를 정규화(Normalization)해준다. 이 가중치를 이용하여 이전 학습데이터를 복원 추출하고 이를 다음 스텝에서 학습 데이터로 사용한다. 그리고 $w_i = \frac{1}{n}$으로 리셋한다.
3. 최종 분류기 $f(x)$와 데이터 $x$에 대한 예측값 $C(x)$는 다음과 같다.
$$f(x) = \sum_{m=1}^M\alpha^{(m)}\cdot T^{(m)}(x)$$
$$\DeclareMathOperator*{\argmaxA}{arg\,max} C(x) = \argmaxA_{k}\sum_{m=1}^M\alpha^{(m)}\cdot I(T^{(m)}(x)=k)$$
$K=2$인 경우 위 알고리즘은 기존 2 분류 AdaBoost 알고리즘이 된다.
- 예제 -
위 알고리즘을 예를 들어서 설명하면 다음과 같다. 아래와 같이 8개의 학습데이터가 있고 몸무게를 이용하여 특정 질병 여부를 예측하는 모형을 AdaBoost 알고리즘으로 만들어본다고 해보자. 그리고 분류기는 깊이가 1인 의사결정나무를 사용한다고 하자.
1. 먼저 초기 가중치를 설정한다.
8개의 데이터이므로 $w_i = 1/8, i=1, \ldots, 8$이다.

2. 모형 개수 $M$을 설정한 뒤 학습데이터를 이용해 모형을 적합하고 가중치를 업데이트한다. 이렇게 업데이트된 가중치를 이용해 복원 추출(with replacement)을 통하여 새로운 학습 데이터를 생성한다.
첫 번째 모형 $T^{(1)}(x)$은 처음에 주어진 학습데이터에 대하여 모형을 적합시킨다. 만약 아래 그림의 왼쪽과 같은 의사결정나무를 얻었다면 몸무게가 80보다 작으면 No, 아니라면 Yes로 예측할 것이다.

이제 가중치를 업데이트 하기 위하여 먼저 학습 데이터에 대한 예측을 수행해야 한다. 그리고 오류율 $err^{(1)}$과 $\alpha^{(1)}$을 계산하고 이를 통해 가중치를 업데이트한다.
마지막으로 합을 1로 맞춰주기 위하여 업데이트된 가중치에서 가중치 합을 각각 나눠준다. 아래의 경우
$$\sum_{i=1}^8w_i = 1.498$$
이므로 업데이트된 가중치에 각각 1.498로 나누어준다.

이렇게 얻어진 데이터에서 가중치를 이용하여 복원 추출을 수행한다.
그리고 가중치를 다시 1/8로 세팅한다.

이 데이터는 다음 스텝을 위한 새로운 학습 데이터가 되며 두 번째 모형은 이 새로운 학습 데이터를 학습하여 얻어진다. 오분류된 데이터 가중치가 높으므로 두 번째 모형은 오분류 데이터가 상대적으로 많이 포함된 데이터를 학습하게 되어 이전 모형에서 잘못 분류한 것들을 더 잘 분류하는 방향으로 학습하게 된다. 이러한 과정을 $M$번 반복하는 것이다.
3. 최종 분류기의 예측을 수행한다.
예를 들어 $M=2$이라하고 2개의 알파값과 $x$가 주어졌을 때 개별 모형의 예측결과(1: Yes, 0: No)가 다음과 같다고 하자.

이 경우 각 라벨 $k$에 대한 알파값들의 합은 다음과 같다.
$$\begin{cases} \alpha^{(1)}I(T^{(1)}(x) = 0) + \alpha^{(2)}I(T^{(2)}(x) = 0) = \alpha^{(2)} = 2.301 &\text{ if } k =0, \\ \alpha^{(1)}I(T^{(1)}(x) = 1) + \alpha^{(2)}I(T^{(2)}(x) = 1) = \alpha^{(1)} = 1.097 &\text{ if } k =1,\end{cases}$$
즉, $k=0$인 경우의 알파값들의 합이 최대가 되므로 $x$가 주어졌을 때 $k=0$ 다른 말로 질병 여부를 YES로 예측하게 된다.
- 이론적 의미 -
AdaBoost 알고리즘을 이제 알게 되었다. 하지만 궁금증이 남아 있다.
AdaBoost 알고리즘으로 만들어진 모형은 정말 좋은 모형인가?
Zhu, H. Zou, S. Rosset, T. Hastie의 2009년 논문 "Multi-class AdaBoost"에서 AdaBoost 알고리즘은 지수 손실 함수를 최소화하는 Forward Stagewise Additive Model이며 지수 손실 함수의 기대값을 최소화하는 분류기는 (우리가 찾고자 하는 궁극적인 분류기인) 베이즈 분류기임을 밝혔다. 즉, AdaBoost 알고리즘으로 얻은 최종 모형(또는 분류기)은 베이즈 분류기의 근사적인(Approximate) Additive 모형이며 쉽게 말하면 지수 손실 관점에서는 최적의 모형이라는 것이다.
베이즈 분류기에 대한 내용은 아래 포스팅을 참고하기 바란다.
[머신 러닝] 3. 베이즈 분류기(Bayes Classifier)
[머신 러닝] 3. 베이즈 분류기(Bayes Classifier)
본 포스팅에서는 수식을 포함하고 있습니다. 티스토리 피드에서는 수식이 제대로 표시되지 않을 수 있으니 PC 웹 브라우저 또는 모바일 웹 브라우저에서 보시기 바랍니다. 이번 포스팅에서는 베
zephyrus1111.tistory.com
2.2 AdaBoost 회귀 모형
AdaBoost 모형은 다음과 같이 회귀 문제(Regression)에도 적용이 가능하다.
먼저 데이터 $(x_1, y_1), \ldots, (x_n, y_n)$이 있다고 하자. 이때 $x_i$는 $p$차원 (실수) 벡터이며 $y_i$는 실수이다.
- 알고리즘 -
Algorithm 2.
1. 초기 가중치를 다음과 같이 세팅한다.
$$w_i = \frac{1}{n}, i=1, \ldots, n$$
2. $m=1 \text{ to } M$에 대하여
(a) 학습 데이터를 이용하여 회귀 모형 $R^{(m)}(x)$를 피팅한다. 이때 기본 모형 $R$는 특정 모형으로 제한하지 않는다. 즉 어떤 회귀 모형(예: 선형 회귀, 서포트 벡터 머신 회귀, 의사결정나무 회귀 모형 등)든 상관없다. Scikit-Learn에서는 의사결정나무를 기본 모형으로 활용한다면 깊이 3을 디폴트로 한다.
(b) 모형으로부터 예측값 $\hat{y}_i^{(m)}$를 계산한다.
(c) 다음을 계산한다.
$$D = \sup_i | \hat{y}_i^{(m)}-y_i|$$
그리고 $L_i$는 아래와 같이 셋 중에 하나를 선택하여 계산한다.
$$L_i = \begin{cases} \frac{|\hat{y}_i^{(m)}-y_i|}{D} & \text{ if } \text{Linear}, \\ \frac{|\hat{y}_i^{(m)}-y_i|^2}{D^2} & \text{ if } \text{Square}, \\ 1- \exp \left [-\frac{|\hat{y}_i^{(m)}-y_i|}{D} \right ] & \text{ if } \text{Exponential} \end{cases}$$
$$\bar{L} = \sum_{i}^nw_iL_i$$
(d) 다음을 계산한다.
$$\beta^{(m)} = \frac{1-\bar{L} }{\bar{L} }$$
(e) 가중치를 다음과 같이 업데이트한다.
$$w_i \longleftarrow w_i(\beta^{(m)})^{(1-L_i)} \text{ } i=1, \ldots, n $$
(f) 가중치를 정규화(Normalization)해준다. 이 가중치를 이용하여 이전 학습 데이터를 복원 추출하고 이를 다음 스텝에서 학습 데이터로 사용한다. 만약 $\bar{L} < 0.5$라면 알고리즘을 종료한다.
3. 최종 모형에 대하여 예측값은 다음과 같이 구한다.
주어진 $x$에 대하여 예측값은 다음과 같이 계산한다. $T(\leq M)$ 스텝에서 얻어진 개별 모형과 $\beta^{(m)}$을 이용하여 최종 예측값 $\hat{y}$를 계산한다.
$$\DeclareMathOperator*{\argmaxA}{arg\,max} \hat{y} = \inf \left\{ y : \sum_{t: \hat{y}^{(t)} \leq y}\log (1/\beta^{(t)}) \geq \frac{1}{2}\sum_{t=1}^T\log (1/\beta^{(t)}) \right \} $$
결국 최종 예측값을 $\hat{y}^{(t)}$들의 가중 중앙값(Weighted Median)이 되는 것이다.
3. AdaBoosting(Adaptive Boosting) 장단점
- 장점 -
1. AdaBoost 은 과적합의 영향을 덜 받는다.
결합하는 모형 개수 $M$이 증가함에 따라 테스트 에러가 잘 증가하지 않는 장점이 있다. 따라서 AdaBoost 은 과적합(Overfitting)의 영향을 덜 받는다. 물론 $M$이 아주 크면 과적합이 발생하지만 상대적으로 늦게 발생한다는 것이다.
2. 구현이 쉽다.
알고리즘 자체가 어렵지 않아 기본 학습기(Base Learner)가 잘 구현되어 있다면 AdaBoost 알고리즘 구현은 쉬워진다.
3. 유연하다.
손실 함수를 여러가지 사용할 수 있으며 기본 학습기에 제한이 없다. 즉, 기본 학습기를 의사결정나무 뿐만아니라 다른 학습기(로지스틱 회귀 모형, 선형 회귀 모형 등)도 사용할 수 있다.
- 단점 -
1. AdaBoost 알고리즘은 이상치에 민감하다고 한다.
2. 해석이 어렵다.
모든 앙상블 계열이 그렇듯이 한 입력 변수와 출력 변수간의 관계를 해석하기가 어렵다. 따라서 출력 변수를 조절하기 위해 입력 변수를 어떻게 변화시켜야되는가에 대한 해답을 제대로 제시할 수 없다.
4. 파이썬 구현
1. 직접 구현
직접 구현하기에 앞서 지난 포스팅에서 소개한 의사결정나무 코드가 필요하다. 파일은 아래 첨부파일을 참고하고 의사결정나무 관련 내용은 여기를 참고하기 바란다.
먼저 필요한 모듈을 임포트하자.
import numpy as np
import pandas as pd
import random
import warnings
warnings.filterwarnings('ignore')
from decision_tree_tool import DecisionTree
이제 구현을 시작해보자. 나는 AdaBoostModel명으로 클래스를 하나 정의했고 필요한 변수들을 초기화해주었다. 설명은 주석을 참고하자.
class AdaBoostModel():
def __init__(self, model_type='classification'):
model_types = ['classification','regression']
assert model_type in model_types, f'model_type must be the one of the {model_types}'
self.model_type = model_type # 문제 타입
self.fitting_models = None # 개별 모형 리스트
self.coef_list = None # 분류 문제에서는 알파, 회귀 문제에서는 베타 계수
self.weight_lists = None # 매 스텝에서의 업데이트된 가중치
self.selected_idx_lists = None # 샘플링된 인덱스
self.err_lists = None # 개별 모형의 에러
self.estimator_predicts = None # 개별 모형의 예측 결과
self.uniq_labels = None # 클래스 라벨
self.num_class = None # 클래스 개수
self.num_data = None # 데이터 개수
self.loss = None # 회귀 문제에서의 로스 타입
다음으로 회귀 문제에서 필요한 함수를 구현하였다. $\bar{L}, L = (L_1, \ldots, L_n)$을 계산하는 함수와 가중 중앙값(weighted median)을 계산한다.
class AdaBoostModel():
'''중략'''
def get_loss(self, y1, y2, sample_weights, loss):
'''
L_bar와 L_array를 계산한다.
'''
D = np.max(np.abs(y1-y2))
if loss == 'linear':
L_array = np.abs(y1-y2)/D
elif loss == 'square':
L_array = np.square(y1-y2)/(D**2)
else:
L_array = 1-np.exp(-np.abs(y1-y2)/D)
L_bar = np.dot(L_array, sample_weights)
return L_bar, L_array
def get_weighted_median(self, x, weights):
'''
가중 중앙값을 계산한다.
'''
sum_val = 0.5*np.sum(weights)
cum_sum = weights[0]
i = 0
while cum_sum < sum_val:
i+=1
cum_sum += weights[i]
return x[i]
이제 주인공이라 할 수 있는 AdaBoosting 알고리즘을 구현한 fit 함수이다. 이 함수는 설계 행렬(Design Matrix) X와 반응 변수 벡터 y를 입력값으로 하며 설명 변수의 각 타입을 지정한다. 타입은 continuous 또는 categorical 두 개만 가질 수 있다. 그리고 모형 개수 $M$을 n_estimators로 설정하고 결과 재생산성을 위한 랜덤 시드 random_state와 회귀 문제인 경우의 로스 종류를 추가 입력값으로 받는 함수이다. 이 함수는 분류 문제(classification)인 경우와 회귀 문제(regression)인 경우를 나누어 AdaBoosting 알고리즘을 수행한다.
그리고 분류 문제인 경우 의사결정나무의 깊이는 2(1로 하니까 성능이 너무 안 나왔다 ㅠㅠ), 회귀 문제인 경우에는 3으로 설정했다.
class AdaBoostModel():
'''중략'''
def fit(self, X, y, type_of_col,
n_estimators=10, random_state=100, loss='linear'
):
self.uniq_labels = np.unique(y)
fitting_models = []
coef_list = [] ## 분류인 경우 alpha, 회귀인 경우 beta
weight_lists = []
selected_idx_lists = []
err_lists = []
estimator_predicts = []
n = X.shape[0]
self.num_data = n
w = np.array([1/n]*len(y))
col_name = X.columns
epsilon = 1e-10
random.seed(random_state)
if self.model_type == 'classification':
K = len(self.uniq_labels) ## 클래스 개수
self.num_class = K
# 초기 가중치
for ne in range(n_estimators):
# 분류나무 적합
clf = DecisionTree(tree_type=self.model_type)
clf.fit(X, y, max_depth=2, type_of_col=type_of_col,
auto_determine_type_of_col=False)
# 개별 모형의 예측값과 오류율 계산
y_predict = np.array(clf.predict(X))
incorrect = y != y_predict
err = np.sum(w[incorrect])/np.sum(w)
if err == 0: ## 오류율이 0이면 early stop
break
estimator_predicts.append(y_predict)
err_lists.append(err)
# alpha 계산
alpha = np.log((1-err)/(err+epsilon))+np.log(K-1)
fitting_models.append(clf)
coef_list.append(alpha)
if ne == n_estimators-1:
break
else:
# 가중치 업데이트 및 새로운 학습데이터 복원 추출
new_w = w.copy()
new_w = new_w*np.exp(alpha*incorrect)
new_w = new_w/np.sum(new_w)
weight_lists.append(new_w)
sampling_idx = random.choices(range(n), weights=new_w, k=n)
selected_idx_lists.append(sampling_idx)
X = X.iloc[sampling_idx, :].reset_index(drop=True)
y = y[sampling_idx]
w = np.array([1/n]*len(y))
else:
assert loss in ['linear', 'square', 'exponential']
self.loss = loss
for ne in range(n_estimators):
# 회귀 나무 적합
reg = DecisionTree(tree_type=self.model_type)
reg.fit(X, y, max_depth=3,impurity_measure='mse', type_of_col=type_of_col,
auto_determine_type_of_col=False)
# 개별 모형의 예측값과 오류율 계산
y_predict = np.array(reg.predict(X))
L_bar, L_array = self.get_loss(y, y_predict, w, loss=self.loss)
beta = L_bar/(1-L_bar)
fitting_models.append(reg)
estimator_predicts.append(y_predict)
coef_list.append(beta)
err_lists.append(L_bar)
if L_bar < 0.5:
break
if ne == n_estimators-1:
break
else:
# 가중치 업데이트 및 새로운 학습데이터 복원 추출
new_w = w.copy()
new_w =new_w**(1-L_array)
sampling_idx = random.choices(range(n), weights=new_w, k=n)
selected_idx_lists.append(sampling_idx)
X = X.iloc[sampling_idx, :].reset_index(drop=True)
y = y[sampling_idx]
w = np.array([1/n]*len(y))
self.fitting_models = fitting_models
self.coef_list = np.array(coef_list)
self.weight_lists = weight_lists
self.selected_idx_lists = selected_idx_lists
self.err_lists = np.array(err_lists)
self.estimator_predicts = estimator_predicts
마지막으로 예측을 수행하는 함수이다. 데이터 행렬 X를 받아 예측값 배열을 리턴한다.
class AdaBoostModel():
'''중략'''
def predict(self, X):
n = self.num_data
pred = []
temp_pred_list = [model.predict(X) for model in self.fitting_models]
temp_pred_tuple = tuple(zip(*temp_pred_list))
if self.model_type == 'classification':
alpha_list = self.coef_list
K = self.num_class
for i in range(n):
temp_labels = [0]*K
temp_pred = np.array(temp_pred_tuple[i])
for k in range(K):
temp_labels[k] = np.sum(alpha_list[temp_pred == k])
pred.append(np.argmax(temp_labels))
else:
beta_list = self.coef_list
weights = np.array([np.log(1/(x+1e-10)) for x in beta_list])
for i in range(n):
temp_pred = np.array(temp_pred_tuple[i])
pred.append(self.get_weighted_median(temp_pred, weights))
return pred2. Scikit-Learn 사용
Scikit-Learn에서도 AdaBoosting 알고리즘을 구현한 클래스가 있다. 분류 문제는 AdaBoostClassifier, 회귀 문제는 AdaBoostRegressor을 사용한다. 사용방법은 아래 예제에서 살펴보자.
5. 예제
1. 분류 문제
- 직접 구현 모형 적용 -
먼저 붓꽃 데이터(Iris Data)에 직접 구현한 AdaBoosting 모형을 적합시켜보자. 먼저 데이터를 불러오자. 이때 라벨을 숫자로 코딩해주었다.
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = [iris.target_names[x] for x in iris.target]
species_to_labels = dict(zip(df['species'].unique(), range(len(df['species'].unique()))))
df['label'] = df['species'].map(species_to_labels)
이제 모형을 적합시키려고 한다. $M=10$으로 설정하였다.
X, y = df.iloc[:,:4], df['label'].values
clf = AdaBoostModel(model_type='classification')
clf.fit(X, y, type_of_col=['continuous']*4, n_estimators=10)
그리고 학습 데이터에 대한 정확도를 계산해보자.
np.mean(y==clf.predict(X))

95.3%가 나왔다. 실제로 적합된 모형이 몇개나 되었는지 살펴보았다.
len(clf.fitting_models)
$M=10$으로 지정했는데 6개의 의사결정나무만 있는 것을 보니 7번째에서 오분류율이 0이 되어 조기 종료(early stop)이 되었다.
- Scikit-Learn 이용 -
이번엔 Scikit-Learn을 이용하여 AdaBoosting 모형을 만들어보자. 직접 구현한 것과 성능 비교를 위해 똑같이 $M=10$(n_estimators)으로 설정하였다.
clf2 = AdaBoostClassifier(n_estimators=10, random_state=100).fit(X, y)
학습 정확도를 알아보자.
np.mean(y==clf2.predict(X))

96%로 직접 구현한 것보다 Scikit-Learn을 이용한 AdaBoost가 좀 더 좋은 학습 성능을 보였다. 이는 Scikit-Learn에서는 리샘플링이 아닌 가중 지니 계수나 엔트로피를 계산하는 방법 차이로 인하여 성능에서 차이가 있었던 것으로보인다. 물론 테스트 데이터로 했다면 달라질 수 있다. ㅠㅠ
Scikit-Learn에서 사용된 모형 개수를 살펴보니 10개를 썼다.
len(clf2.estimators_)
# 10
2. 회귀 문제
이번엔 보스턴 집값(boston data) 데이터를 이용하여 회귀 문제에 AdaBoosting 알고리즘을 적용해보자.
- 직접 구현 모형 적용 -
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df['y'] = boston.target
AdaBoosting 모형을 만들어보자.
X = df[['RM', 'LSTAT']]
y = df['y'].values
reg = AdaBoostModel(model_type='regression')
reg.fit(X, y, type_of_col=['continuous']*2, n_estimators=10)
학습 데이터에 대한 잔차 평균을 계산해 보았다.
np.mean(np.linalg.norm(y-reg.predict(X)))

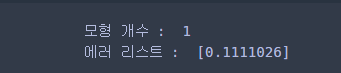
96.22 정도가 나왔다. 사용된 모형을 보니 의사결정나무가 하나 있었고 이는 에러가 0.11이었는데 이것이 0.5보다 작아 조기 종료(early stop)된 것이다.
print('모형 개수 : ', len(reg.fitting_models))
print('에러 리스트 : ', reg.err_lists)
- Scikit-Learn 이용 -
Scikit-Learn에서는 AdaBoostRegressor를 이용하여 회귀 모형을 적합할 수 있다.
reg2 = AdaBoostRegressor(n_estimators=10, random_state=100).fit(X, y)
학습 데이터에 대한 정확도를 계산해보자.
np.mean(np.linalg.norm(y-reg2.predict(X)))

97.66으로 학습데이터에 대한 성능은 오히려 내가 직접 구현한 것이 더 좋았다. 물론 테스트 데이터로 했으면 결과가 어땠을지 모른다.
이번 포스팅을 하면서 AdaBoost 알고리즘을 직접 구현할 수 있었던 좋은 시간이었다. 직접 구현해보니 Scikit-Learn의 AdaBoost 알고리즘 적합 과정 코드도 더 심도 있게 이해할 수 있었다. 구현을 해봐야 알고리즘에 대한 이해와 기존 패키지에서 제공하는 AdaBoost 알고리즘도 더 잘 활용할 수 있다.
AdaBoost 알고리즘의 비교 과정에서 속도는 확실히 Scikit-Learn이 우수하고 데이터에 따라서 직접 구현한 AdaBoost의 학습 데이터 정확도 차이가 크게 난 경우도 있었다. 즉, Scikit-Learn을 쓰면 된다.
이번 포스팅에서의 주된 목표는 AdaBoost의 구현이어서 테스트 데이터를 분할한 검증은 귀찮아서 하지 않았다. 원래는 해야 된다.
그래도 앞에서도 얘기했지만 AdaBoost 알고리즘을 직접 구현할 수 있어서 재밌었다.
참고자료
Zhu, H. Zou, S. Rosset, T. Hastie - Multi-class AdaBoost
H. Drucker - Improving Regresors using Boosting Techniques
StatQuest - AdaBoost, Clearly Explaind
sklearn AdaBoostClassifier - 개발 문서

'통계 > 머신러닝' 카테고리의 다른 글
| 17. Dunn Index와 실루엣(Silhouette) 계수를 이용하여 최적 클러스터(군집, Cluster)개수 정하기 with Python (388) | 2022.05.07 |
|---|---|
| 16. 선형 회귀(Linear Regression) 모형에 대해서 알아보자 with Python (416) | 2022.05.06 |
| 14. 클러스터링(군집화) 평가지표 Silhouette(실루엣) 지수(계수)에 대해서 알아보자 with Python (410) | 2022.05.01 |
| 13. Box-Cox Transformation(변환)에 대해서 알아보자 with Python (385) | 2022.05.01 |
| 12. Gaussian Mixture Model(가우시안 혼합 모형) 클러스터링(군집 분석)에 대해서 알아보자 with Python (408) | 2022.04.25 |





댓글