이번 포스팅에서는 Scikit-Learn(sklearn)에서 서포트 벡터 머신을 학습하는 방법에 대해서 알아본다. 여기서는 분류 서포트 벡터 머신과 회귀 서포트 벡터 머신을 나누어 살펴보겠다.
1. Scikit-Learn 분류 서포트 벡터 머신(SVC)
2. Scikit-Learn 회귀 서포트 벡터 머신(SVR)
서포트 벡터 머신에 대한 개념은 아래를 참고하기 바란다.
19. 서포트 벡터 머신(Support Vector Machine)에 대해서 알아보자 with Python
19. 서포트 벡터 머신(Support Vector Machine)에 대해서 알아보자 with Python
딥러닝이 나타나기 전에 전성기를 구가했던 서포트 벡터 머신(Support Vector Machine)에 대해서 공부한 내용을 포스팅하려고 한다. 서포트 벡터 머신에 대한 개념과 종류 그리고 파이썬으로 구현하는
zephyrus1111.tistory.com
1. Scikit-Learn 분류 서포트 벡터 머신(SVC)
붓꽃 데이터(iris)를 이용하여 분류 서포트 벡터 머신을 학습해보자. 붓꽃 데이터를 임포트하고 X, y 데이터를 만들어준다.
import pandas as pd
import numpy as np
from sklearn.svm import SVC, SVR
from sklearn.datasets import load_iris, load_boston
# 분류
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = [iris.target_names[x] for x in iris.target]
species_to_labels = dict(zip(df['species'].unique(), range(len(df['species'].unique()))))
df['species'] = df['species'].map(species_to_labels) # 라벨을 숫자로 변환
X = df.drop('species', axis=1)
y = df['species']
Scikit-Learn에서는 SVC를 이용하여 분류 서포트 벡터 머신을 만들 수 있다.
먼저 기본적인 Soft-Margin Linear 서포트 벡터 머신을 학습해보자. 먼저 SVC 클래스를 생성해야 한다. 이때 정규화를 위한 상수(Hyper Parameter) $C$는 10으로 설정했다. Soft-Margin Linear 모형을 위해 kernel은 반드시 linear로 설정해야 한다.
fit을 통하여 학습한 뒤 결과를 출력한다. 예측을 위해 predict를 사용했다.
이때 중요한 것은 가중치의 경우 kernel이 linear인 경우에만 출력할 수 있다는 것이다.
clf = SVC(C=10, kernel='linear', random_state=100) # SVC 클래스 생성
clf.fit(X, y) ## 모형 학습
## 파라미터 추정치
print('가중치 :', clf.coef_) # 가중치는 kernel = 'linear'인 경우만 존재
print('절편항 :', clf.intercept_)
print('학습 정확도 :', np.mean(y==clf.predict(X)))

가중치가 3x4 행렬로 나왔는데 4의 의미는 X의 변수 개수이고 3은 이진 서포트 벡터 머신을 3개 사용했다는 것이다. 붓꽃 데이터는 3개의 라벨을 갖고 있는데 이를 One vs Rest 방법을 이용하면 총 3개의 이진 서포트 벡터 머신이 필요하기 때문이다.
마찬가지로 절편항도 3개가 나왔으며 학습 정확도는 98%를 나타내었다.
이번엔 linear 커널 외 Scikit-Learn에서 제공하는 커널을 모두 사용한 결과를 알아보자.
kernel_list = ['rbf', 'poly', 'sigmoid']
for kernel in kernel_list:
clf = SVC(C=10, kernel=kernel, random_state=100) # SVC 클래스 생성
clf.fit(X, y) ## 모형 학습
## 파라미터 추정치
print('커널 :', kernel)
print('절편항 :', clf.intercept_)
print('학습 정확도 :', np.mean(y==clf.predict(X)))

rbf 커널을 사용했을 때 가장 좋은 학습 정확도를 보여주었다.
2. Scikit-Learn 회귀 서포트 벡터 머신(SVR)
이번엔 보스턴 집값 데이터를 이용하여 회귀 서포트 벡터 머신을 학습해보자.
먼저 보스턴 집값 데이터를 임포트 하고 X, y 데이터를 만들어준다.
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
X = df[['LSTAT']].values
y = boston.target
Scikit-Learn에서는 SVR를 이용하여 회귀 서포트 벡터 머신을 만들 수 있다.
먼저 기본적인 Soft-Margin Linear 서포트 벡터 머신을 학습해보자. 먼저 SVR 클래스를 생성해야 한다. 회귀에서는 분류와 다르게 $\epsilon$을 추가적으로 설정해야 한다. 난 0.2로 설정했으며 오류에 대한 벌점항에 대응하는 상수(Hyper Parameter) $C$는 10으로 설정했다. kernel은 linear로 설정한다.
reg = SVR(C=10, epsilon=0.2, kernel='linear') # SVR 생성
reg.fit(X, y) # 모형 적합
## 파라미터 추정치
print('가중치 :', reg.coef_) # 가중치는 kernel = 'linear'인 경우만 존재
print('절편항 :', reg.intercept_)
print('평균 잔차 제곱 :', np.mean(np.square(y-reg.predict(X))))
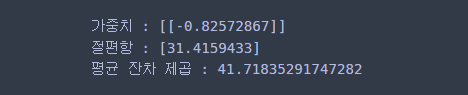
회귀는 분류와 다르게 가중치가 1x1 행렬이다. 앞의 1은 서포트 벡터 머신 모형은 하나이고 뒤의 1은 변수 개수이다. 가중치는 kernel이 linear인 경우만 출력할 수 있다.
여러가지 커널에 대해서 모형을 학습하고 결과를 출력해보자.
kernel_list = ['rbf', 'poly', 'sigmoid']
for kernel in kernel_list:
reg = SVR(C=10, epsilon=0.2, kernel=kernel) # SVR 생성
reg.fit(X, y) # 모형 적합
## 파라미터 추정치
print('커널 :', kernel)
print('절편항 :', reg.intercept_)
print('평균 잔차 제곱 :', np.mean(np.square(y-reg.predict(X))))
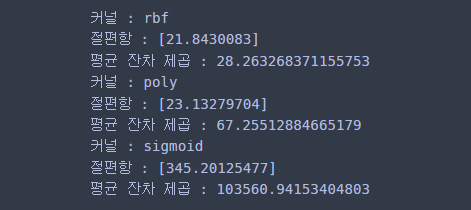
회귀에서도 rbf 커널인 경우의 성능이 가장 좋았다.

'프로그래밍 > Scikit-Learn' 카테고리의 다른 글
| [Scikit-Learn] 6. AdaBoost 모형 만들기(feat. AdaBoostClassifier, AdaBoostRegressor) (403) | 2022.06.18 |
|---|---|
| [Scikit-Learn] 5. 의사결정나무(Decision Tree) 만들기(feat. DecisionTreeClassifier, DecisionTreeRegressor) (410) | 2022.06.18 |
| [Scikit-Learn] 3. 데이터 칼럼 표준화하기 feat. StandardScaler (380) | 2022.05.27 |
| [Scikit-Learn] 2. 최대 최소(Min Max) 변환하기 feat. MinMaxScaler (400) | 2022.05.27 |
| [Scikit-Learn] 1. sklearn을 이용하여 선형 회귀 모형(Linear Regression) 적합하기 (392) | 2022.05.07 |





댓글