이번 포스팅에서는 Scikit-Learn(sklearn)을 이용하여 데이터 칼럼을 표준화하는 방법을 알아보려고 한다. 표준화는 데이터를 주어진 평균과 표준편차를 갖도록 변환하는 것이다. Scikit-Learn에서는 StandardScaler를 통해 데이터를 표준화할 수 있다.
StandardScaler를 이용한 표준화 변환 과정은 지난 포스팅에서 다룬 MinMaxScaler를 이용한 Min Max 변환 과정과 동일하므로 아래 포스팅을 참고하면 좋다.
[Scikit-Learn] 2. Min Max 변환하기 feat. MinMaxScaler
[Scikit-Learn] 2. Min Max 변환하기 feat. MinMaxScaler
예측 모델링을 할 때 학습 데이터에 대하여 변환하는 경우가 굉장히 많다. 그중에서 각 데이터를 특정 범위로 제한시키는 Min Max 변환을 많이 사용한다. Min Max 변환은 원 데이터를 우리가 지정한
zephyrus1111.tistory.com
Scikit-Learn(sklearn) StandardScaler 사용법
이번에도 보스턴 집값 데이터를 이용하여 표준화하려고 한다.
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_boston
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
X = df[['B', 'LSTAT']]
print(X.values)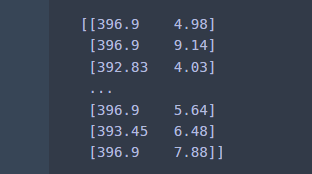
이제 표준화를 시켜보자.
먼저 StandardScaler 클래스를 생성하고 fit을 이용하여 표준화 함수를 생성한 뒤 transform을 통하여 표준화를 수행한다.
scaler = StandardScaler() # StandardScaler 클래스 생성
scaler.fit(X) # 표준화를 수행 함수 생성
transformed_X = scaler.transform(X) # 표준화 수행
print(transformed_X)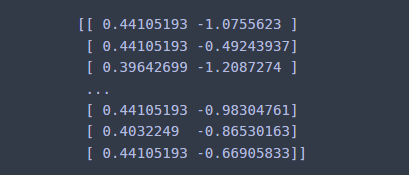
표준화된 데이터를 원래대로 되돌리고 싶다면 다음과 같이 inverse_transform을 이용하면 된다.
inverse_transformed_X = scaler.inverse_transform(transformed_X)
print(inverse_transformed_X)

'프로그래밍 > Scikit-Learn' 카테고리의 다른 글
| [Scikit-Learn] 6. AdaBoost 모형 만들기(feat. AdaBoostClassifier, AdaBoostRegressor) (403) | 2022.06.18 |
|---|---|
| [Scikit-Learn] 5. 의사결정나무(Decision Tree) 만들기(feat. DecisionTreeClassifier, DecisionTreeRegressor) (410) | 2022.06.18 |
| [Scikit-Learn] 4. 서포트 벡터 머신 모형 만들기. feat SVC, SVR (402) | 2022.05.27 |
| [Scikit-Learn] 2. 최대 최소(Min Max) 변환하기 feat. MinMaxScaler (400) | 2022.05.27 |
| [Scikit-Learn] 1. sklearn을 이용하여 선형 회귀 모형(Linear Regression) 적합하기 (392) | 2022.05.07 |





댓글