Scikit-Learn(sklearn)에서는 GradientBoostingClassifier, GradientBoostingRegressor를 이용하여 Gradient Boosting 예측 모형을 학습할 수 있다. Gradient Boosting은 분류와 회귀 문제 모두 적용할 수 있는데 이에 대해서 각각 알아본다.
1. 분류 문제(GradientBoostingClassifier)
2. 회귀 문제(GradientBoostingRegressor)
Gradient Boosting에 대한 개념과 Scikit-Learn에서 의사결정나무를 학습하는 방법을 아래 포스팅에서 소개해놓았다. 읽고 오면 좋다.
20. Gradient Boosting 알고리즘에 대해서 알아보자 with Python
20. Gradient Boosting 알고리즘에 대해서 알아보자 with Python
이번 포스팅에서는 Gradient Boosting의 개념과 알고리즘을 소개하며 이를 응용한 Gradient Tree Boosting의 개념과 알고리즘도 소개한다. 그리고 Gradient Tree Boosting 알고리즘을 파이썬으로 직접 구현하는
zephyrus1111.tistory.com
[Scikit-Learn] 5. 의사결정나무(Decision Tree) 만들기(feat. DecisionTreeClassifier, DecisionTreeRegressor)
[Scikit-Learn] 5. 의사결정나무(Decision Tree) 만들기(feat. DecisionTreeClassifier, DecisionTreeRegressor)
이번 포스팅에서는 Scikit-Learn(sklearn)을 이용하여 의사결정나무를 학습하고 이를 시각화하는 방법에 대해서 알아본다. 또한 결과를 시각화하는 것뿐만 아니라 노드 정보(샘플 수, 불순도, 예측값)
zephyrus1111.tistory.com
1. 분류 문제(GradientBoostingClassifier)
붓꽃 데이터를 이용하여 Gradient Boosting 알고리즘을 분류 문제에 적용시켜보자. Scikit-Learn에서는 GradientBoostingClassifier 클래스를 이용하여 분류 모델을 학습할 수 있다.
GradientBoostingClassifier 클래스는 loss를 통해 손실 함수를 설정할 수 있고 n_estimators를 통해 반복수(또는 개별 트리의 개수)를 설정할 수 있다. GradientBoostingClassifier 클래스의 base_estimator는 AdaBoost와는 달리 무조건 의사결정나무로 고정되어 있어 base_estimator를 따로 설정할 수 없다. 그 외 나머지 인자에 대한 설명은 주석을 참고하기 바라며 더 자세한 사항은 여기를 보면 된다.
import pandas as pd import numpy as np import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') from sklearn.datasets import load_iris, load_boston from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor from sklearn.tree import plot_tree from sklearn.ensemble import GradientBoostingClassifier, GradientBoostingRegressor iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['species'] = [iris.target_names[x] for x in iris.target] X = df.drop('species', axis=1) y = df['species'] clf = GradientBoostingClassifier( loss='deviance', ## ‘deviance’, ‘exponential’ criterion='squared_error', ## 개별 트리의 불순도 측도 n_estimators=3, ## 반복수 또는 base_estimator 개수 min_samples_leaf=5, ## 개별 트리 최소 끝마디 샘플 수 max_depth=3, ## 개별트리 최대 깊이 learning_rate=1, ## 스텝 사이즈 subsample = 0.8, random_state=100 ).fit(X,y)
학습이 끝나고 예측은 predict 메서드를 통해 수행할 수 있다. 이외에도 변수 중요도, 클래스 인자 정보, 정확도를 뽑을 수 있다.
## 예측 print(clf.predict(X)[:3]) ## 변수 중요도 for i, col in enumerate(X.columns): print(f'{col} 중요도 : {clf.feature_importances_[i]}') print(clf.get_params()) ## GradientBoostingClassifier 클래스 인자 설정 정보 print('정확도 : ', clf.score(X,y)) ## 성능 평가 점수(Accuracy)

2. 회귀 문제(GradientBoostingRegressor)
1) 학습
보스턴 집값 데이터를 이용하여 Gradient Boosting 알고리즘을 회귀 문제에 적용해보자. Scikit-Learn에서는
GradientBoostingRegressor 클래스를 사용하여 회귀 모델을 만들 수 있다. 사용법은 GradientBoostingClassifier와 흡사하다. 차이점은 손실 함수가 다르다는 것이다.
boston = load_boston() df = pd.DataFrame(boston.data, columns=boston.feature_names) df['MEDV'] = boston.target X = df.drop('MEDV', axis=1) y = df['MEDV'] reg = GradientBoostingRegressor( loss='huber', ## ‘squared_error’, ‘absolute_error’, ‘huber’, ‘quantile’ criterion='squared_error', ## 개별 트리의 불순도 측도 n_estimators=3, ## 반복수 또는 base_estimator 개수 min_samples_leaf=5, ## 개별 트리 최소 끝마디 샘플 수 max_depth=3, ## 개별트리 최대 깊이 learning_rate=1, ## 스텝 사이즈 subsample = 0.8, random_state=100 ).fit(X,y)
분류 모델에서와 마찬가지로 예측과 변수 중요도 R square를 뽑을 수 있다.
## 예측 print(reg.predict(X)[:3]) ## 변수 중요도 for i, col in enumerate(X.columns): print(f'{col} 중요도 : {reg.feature_importances_[i]}') print(reg.get_params()) ## GradientBoostingRegressor 클래스 인자 설정 정보 print('정확도 : ', reg.score(X,y)) ## 성능 평가 점수(R-square)
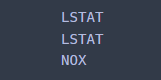
개별 트리의 루트 노드 분리 변수를 뽑고자 한다면 아래와 같이 하면 된다.
for i in range(len(reg.estimators_)): ind_est = reg.estimators_[i][0] col_idx = ind_est.tree_.feature[0] print(X.columns[col_idx]) ## 루트 노드에서의 분리 변수
2) 시각화
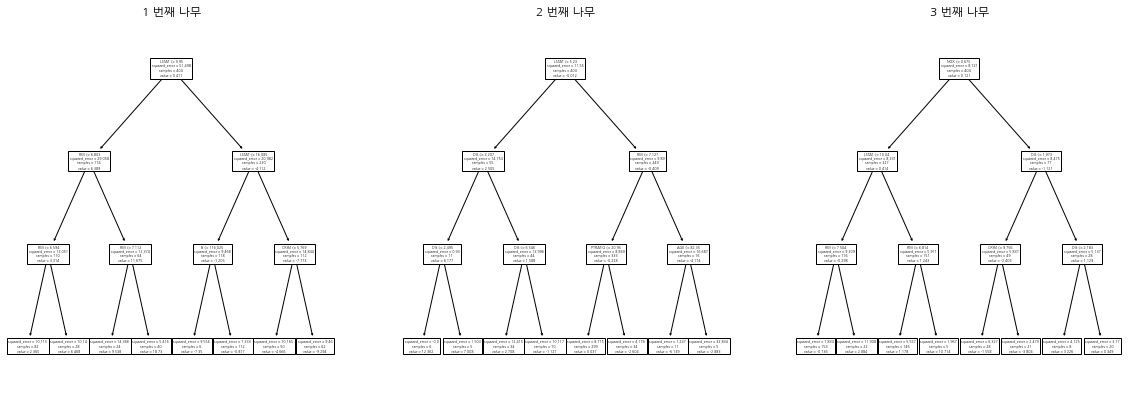
n_estimator의 개수가 작은 경우(5 이하) 시각화를 통해 각 스텝에서 어떤 나무가 생성되었는지 알 수 있다. 분류 문제에서는 2분류 문제가 아닌 3개이상의 라벨을 가진 다중 분류가 되면 의사결정나무가 n_estimator X (클래스 개수) 만큼 생성되어 시각화하기 애매해서 다루지 않았다.
n_estimator = len(reg.estimators_) fig = plt.figure(figsize=(20, 15), facecolor='white') row_num=2 col_num=3 for i in range(n_estimator): ax = fig.add_subplot(row_num, col_num, i+1) plot_tree(reg.estimators_[i][0], feature_names=X.columns, ## 박스에 변수 이름 표시 ax=ax ) ax.set_title(f'{i+1} 번째 나무') plt.show()





댓글