안녕하세요~~ 꽁냥이에요!
선형 회귀 모형에서는 오차의 분포를 정규분포로 가정하는데요. 오차의 정규분포 가정을 시각적으로 테스트할 수 있는 방법은 QQ plot을 그려보는 방법이 있고요. 통계적으로 검정을 수행하여 정규분포 가정의 타당성을 테스트할 수도 있어요.
이번 포스팅에서는 정규분포에 대한 가정을 통계적으로 검정할 수 있는 3가지 방법을 소개합니다.
2. Correlation Test for Normality
5. 그렇다면 정규성 검정을 위해 어떤 테스트를 써야 할까?
1. 데이터 준비
아래 데이터 파일을 다운받아주세요.
먼저 이번 포스팅에서 사용할 모듈을 임포트하고 데이터를 불러옵니다.
import pandas as pd
import numpy as np
from scipy.stats import norm
from scipy import stats
from statsmodels.formula.api import ols
df = pd.read_csv('./toluca_company_dataset.csv') ## 데이터 불러오기

2. Correlation Test for Normality
QQ plot을 이용하여 오차의 정규성을 시각적으로 테스트하고자 할 때
1) 먼저 정규분포를 따를 때의 이론적 잔차값과 관측된 잔차를 이용하여 산포도를 그립니다.
(이론적 잔차 값을 구하는 방법은 여기에서 QQ plot 부분을 참고하세요.)
2) 그러고 나서 각 점들의 분포가 직선에 가까운 경우 정규분포를 따른다고 판단하는데요.
직선에 가깝다는 것은 이론적 잔차값과 관측된 잔차의 상관계수가 1에 가깝다는 말과 동일하고요.
따라서 "이 상관계수 값이 특정 값보다 크다면 오차가 정규분포를 따른다고 볼 수 있지 않을까?" 하는 것이 Correlation Test의 아이디어입니다.
Correlation Test에서 귀무가설과 대립 가설은 다음과 같습니다.
$H_0$ : 오차항은 정규분포를 따른다.
$H_a$ : 오차항은 정규분포가 아니다.
이제 테스트를 수행해볼까요?
## correlation test for normality
## 선형 모형 적합
fit = ols('Work_hours ~ Lot_size',data=df).fit()
## qq plot
sqrt_mse = np.sqrt(fit.mse_resid) ## square root of mse
num_const = 0.375 ## 백분위 분자 수정 계수
denom_const = 0.25 ## 백분위 분모 수정계수
## 오름차순으로 정렬했을 때 잔차의 순위
rank = [sorted(fit.resid).index(x)+1 for x in fit.resid] ## 인덱스가 0부터 시작하므로 1을 더한다.
expected_value = [] ## 이론적 잔차값
for i in range(len(fit.resid)):
p = (rank[i]-num_const)/(len(fit.resid)+denom_const) ## 백분위
expected_value.append(sqrt_mse*norm.ppf(p))
## 상관계수 계산
test_stat = np.corrcoef(fit.resid,expected_value)[0][1]
line 3
먼저 Lot_size를 설명변수로 하고 Work_hours를 반응 변수로 하는 단순선형회귀모형을 적합합니다.
line 5~17
이론상 잔차값을 계산해줍니다.
line 20
검정 통계량을 구해줍니다. 이 값을 이용하여 귀무가설의 채택 또는 거절 여부를 알아내려고 합니다.
꽁냥이는 유의수준 5%에서 검정 통계량을 이용하여 테스트해보고자 합니다. 참고로 양쪽 검정은 의미가 없어요. 정확히 말하면 왼쪽 검정(기각역이 특정 임계치보다 작은 영역인 검정)만을 수행하면 됩니다. 왜냐하면 특정 임계치보다 크다고 해서 기각할 수 있는 게 아니기 때문이지요. 상관계수의 값이 커지면 커질수록 정규분포라 얘기할 수 있기 때문에 특정 임계치보다 크다고 해서 기각할 수 있는 것이 아니기 때문입니다.
따라서 임계치를 구해야 하는데요. Looney와 Gulledge는 데이터 개수에 따른 왼쪽, 오른쪽 꼬리 확률에 대응하는 임계치를 계산해놨어요.
꽁냥이가 왼쪽 꼬리 확률 0.05, 0.01에 대응하는 임계치를 엑셀로 정리하였으니 필요하신 분들은 다운받아주세요.
임계치에 대한 전체 테이블을 확인하고 싶으신 분들은
Looney, S. W., and T. R. Gulledge, Jr. "Use of the Correlation Coefficient with Normal Probability Plots" The American Statistician 39 (1985), pp-75-79
를 참고하세요.
먼저 검정 통계량 값을 확인해보겠습니다.
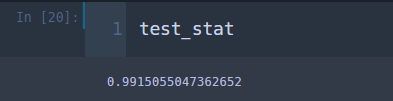
확인해보니 약 0.992이 나왔어요.
자 이제 표를 확인해봅시다!

꽁냥이는 유의수준이 5%인 검정을 수행하려고 하므로 꼬리 확률은 0.05이면서 데이터의 개수는 25개에 해당하는 임계치를 확인해야합니다. 표에 따르면 임계치가 0.959라는 것을 확인할 수 있습니다.
따라서 검정 통계량 값 0.992가 임계치 0.959 보다 크므로 우리는 귀무가설을 유의수준 5%에서 채택할 수 있는 것이지요. 다시 말하면 오차의 분포가 정규분포라고 얘기할 수 있다는 뜻이에요.
3. Kolmogorov-Smirnov test
이번엔 Kolmogorov_Smirnov 테스트(K-S 테스트)에 대해서 알아보겠습니다. K-S 테스트는 관측된 데이터가 특정 분포를 따르는지를 검정하는 잘 알려진 테스트입니다.
K-S 테스트를 수행하려면 경험 분포 함수의 정의를 알아야 합니다.
먼저 $X_i$ ($i=1, 2, \cdots, n$)이 서로 독립이고 동일한 분포에서 추출된 샘플이라고 하면 경험 분포 함수 $F_n$를 다음과 같이 정의합니다.
$$F_n(x) = \frac{1}{n}\sum_{i=1}^{n}I_{[-\infty,x]}(X_i)$$
여기서 $I_{[-\infty,x]}(X_i)$는 지표 함수로써 $X_i\leq x$이면 1, 아닌 경우에는 0인 함수입니다.
이때 정규분포를 위한 K-S 검정 통계량은 다음과 같이 정의됩니다.
$$D_n = \sup_{x}\lvert F_n(x)-\Phi(x) \rvert\tag{1}$$
여기서 $\Phi(x)$는 표준 정규분포의 누적 분포 함수입니다. 여기서 $D_n$은 경험분포함수와 정규분포의 누적분포함수 사이의 거리라고 생각할 수 있어요.
"정규분포의 이론적 누적분포함수와 샘플로 구한 경험분함수와의 거리(또는 차이)가 가까우면 이는 추출된 샘플이 정규분포로 부터 나온 것이라고 말할 수 있다"
이것이 K-S 테스트의 아이디어입니다.
따라서 K-S 검정 통계량을 샘플 수와 유의수준에 해당하는 임계치를 찾아 비교하고 이 때 검정통계량 값이 임계치보다 크다면 귀무가설을 기각하게 됩니다. 이는 주어진 샘플이 정규분포를 따르지 않는다고 판단하는 것이지요.
자 이제 K-S 테스트를 수행해볼까요?
## Kolmogorov-Smirnov test
## 선형 모형 적합
fit = ols('Work_hours ~ Lot_size',data=df).fit()
## 이론상 잔차값 계산
sqrt_mse = np.sqrt(fit.mse_resid) ## square root of mse
std_res = fit.resid/sqrt_mse ## studentized residual
def empirical_dist(x,samples):
## x에 대응하는 경험 분포 값을 계산하는 함수
count = 0
for s in samples:
if s <= x:
count += 1
return count/len(samples)
distance = [] ## 경험 분포 함수값과 정규분포의 누적함수 값의 차이를 담는다.
for r in std_res:
diff = abs(empirical_dist(r,std_res)-norm.cdf(r))
distance.append(diff)
## K-S 검정 통계량
ks_stat = max(distance)
line 7
여기서는 표준화된 잔차를 이용합니다.
line 9~15
경험 분포 함수 값을 계산하기 위한 함수를 만들었습니다.
line 17~20
각 샘플에 대하여 경험 분포 함수와 샘플값에 대응하는 정규분포의 누적 분포 함숫값의 차이를 계산합니다.
line 23
검정 통계량 값을 계산합니다.
-- 이 부분은 넘어가셔도 됩니다 --
혹시 궁금한 사람들이 있을 것 같아서 말씀드리면 식 (1)에서 검정 통계량에 supremum(최대값)이 포함되어 있어 이를 어떻게 계산해야 할지 막막할 수 있어요. 왜냐하면 모든 실수 $x$에 대하여 경험 분포 함수와 누적 분포 함수 차이값을 알아야 이에 대한 최대값을 구할 수 있기 때문이지요. 하지만 최대값은 샘플값 중에서 찾을 수 있어요. 즉, $x$를 모든 실수가 아닌 샘플 값들만 고려하면 됩니다(이에 대해서 정확히 이야기하려면 함수의 연속성을 알아야 하므로 패스하겠습니다).
검정 통계량의 값을 확인해볼까요?

검정 통계량 값은 0.09664 임을 알 수 있습니다.
이제 유의수준 5%에서의 임계치를 알면 됩니다. 임계치 테이블은 여기를 참고하세요.

샘플 수는 25개이고 유의수준 5%에서 검정을 수행할 것이므로 이에 해당하는 테이블 값을 찾아보면 임계치는 0.26404 임을 알 수 있습니다.
우리가 구한 검정 통계량 값은 0.09664이고 이는 임계치보다 작으므로 귀무가설을 채택하게 됩니다. 다시 말하면 잔차의 분포가 정규분포라고 판단할 수 있는 것이지요.
4. Shapiro-Wilks Test
Shapiro-Wilks 테스트 또한 오차의 정규성을 테스트할 수 있어요.
Shapiro-Wilks는 샘플을 오름차순으로 정렬합니다. 그리고 표준 정규분포에 추출된 순서 통계량의 이론적 기대값을 구합니다. 이렇게 구한 기대값과 오름차순으로 정렬된 샘플과의 상관계수를 계산합니다. 이때 상관계수가 1에 가까울수록 추출된 샘플은 정규분포의 가깝다고 할 수 있겠지요. 이것이 Shapiro-Wilks 테스트의 아이디어입니다.
하지만 이 상관계수를 구할 때 순서 통계량이 분산이 들어가는데요. 분산을 구하려면 이중 적분을 계산해야 돼서 정확한 값을 구하기보다는 근사값으로 대체해야 된다고 합니다.
따라서 꽁냥이는 이를 직접 구현하기보다는 scipy에서 제공하는 함수를 통하여 Shapiro-Wilks 테스트를 수행하려고 합니다. Shapiro-Wilks 테스트의 자세한 내용은 위키를 참고하세요.
아래 코드를 살펴볼게요.
## Shapiro-Wilks test
## 선형 모형 적합
fit = ols('Work_hours ~ Lot_size',data=df).fit()
## 이론상 잔차값 계산
sqrt_mse = np.sqrt(fit.mse_resid) ## square root of mse
std_res = fit.resid/sqrt_mse ## studentized residual
## Shapiro-Wilks 테스트의 검정통계량과 p-value를 계산한다.
shapiro_test = stats.shapiro(std_res)
sw_stat = shapiro_test[0] ## S-W 검정 통계량
p_value = shapiro_test[1] ## p_value
line 10
stats.shapiro 함수에 잔차를 넘겨줍니다. 이 함수는 인자로 받은 샘플에 대해서 Shapiro-Wilks 테스트의 검정 통계량과 p-value를 계산해줍니다.
검정통계량 값을 확인해봅시다~

검정통계량 값은 약 0.9789입니다. 1에 매우 가까운 값입니다.
이제 p-value를 확인해봅시다~

p-value를 확인해보니 약 0.8626입니다. 이는 귀무가설을 강하게 채택한다고 볼 수 있지요. 다시 말하면 오차의 정규성을 만족한다고 할 수 있어요.
5. 그렇다면 정규성 검정을 위해 어떤 테스트를 써야 할까?
위 세 개 중에서 Shapiro-Wilks 테스트가 가장 검정력이 좋다고 알려져 있어요. 따라서 Shapiro-Wilks 테스트를 이용하시고요. 하지만 나머지 테스트도 그 아이디어 정도는 기억해두시기 바랍니다.
'데이터 분석 > 데이터 분석' 카테고리의 다른 글
| [회귀 분석] 5. 최적 모형 선택(All possible search 또는 Best subsets algorithm) with Python (7) | 2020.09.26 |
|---|---|
| [회귀 분석] 4. 오차의 등분산성 검정(테스트)하기 with Python (4) | 2020.09.22 |
| [회귀 분석] 2. 잔차도(Residual plot)와 QQ plot 그리기 (0) | 2020.09.18 |
| [회귀 분석] 1. Python을 이용하여 단순 선형 회귀 모형 적합해보기! (0) | 2020.09.14 |
| [A/B 테스트] 2. A/B 테스트 사례에 대하여 알아볼까요?! (0) | 2020.08.09 |





댓글