이번 포스팅에서는 랜덤 포레스트(Random Forest) 보다 더한층 Randomness를 강화한 Extremely Randomized Tree(ERT)에 대해서 알아보고자 한다.
- 목차 -
1. Extremely Randomized Tree(ERT)이란 무엇인가?
2. Extremely Randomized Tree(ERT) 알고리즘
이번 포스팅은 랜덤 포레스트에 대한 내용을 알면 도움이 된다. 랜덤 포레스트에 대한 개념을 잘 모르는 분들은 아래 포스팅에 잘 정리해 두었으니 참고하면 된다.
24. 랜덤 포레스트(Random Forest)에 대해서 알아보자
24. 랜덤 포레스트(Random Forest)에 대해서 알아보자
이번 포스팅에서는 랜덤 포레스트(Random Forest)에 대해서 알아보고자 한다. 랜덤 포레스트(Random Forest)의 개념, 알고리즘, 여러 고려사항 및 장단점에 대해서 정리해보려고 한다. - 목차 - 1. 랜덤 포
zephyrus1111.tistory.com
1. Extremely Randomized Tree(ERT)이란 무엇인가?
1) 정의
Extremely Randomized Tree(ERT)는 분리 시 변수만을 랜덤하게 선택한 기존 랜덤 포레스트(Random Forest)의 분리 방식에 분리 값 또한 랜덤하게 선택하는 과정을 추가했고 이를 통해 개별 트리 간 상관성을 낮추어 예측력을 높이고자 한 앙상블 모형이다.
2) 파헤치기
위의 정의를 하나씩 파헤쳐보자.
a. ERT는 영역을 분리할 때 변수 뿐만아니라 분리 값 또한 랜덤하게 선택한다.
ERT는 영역 분리 시 변수만 랜덤하게 선택하는 기존 랜덤 포레스트(Random Forest)에 분리값 또한 랜덤하게 선택하는 과정을 추가했다.
랜덤 포레스트와 ERT의 분리 방법의 차이를 알아보자. 먼저 아래 그림은 전체 변수가 10개 있는 경우 랜덤 포레스트의 분리 방식을 나타낸 것이다. 먼저 전체 변수 중에서 2개를 랜덤하게 뽑은 것이 변수 3, 변수 7이다. 선택된 각 변수들이 가질 수 있는 모든 값에 대하여 불순도를 계산하고 최적 변수와 분리값을 선택한다. 예를 들어 변수 3이 가질 수 있는 값이 3, 17, 20, 25, 26 총 5개 있고 이 중에서 불순도를 가장 작게 하는 값을 찾는 것이다. 아래 그림은 이 과정을 변수 7에 대해서도 동일하게 한 다음 불순도를 가장 작게 하는 변수는 변수 3이며 이에 대응하는 분리 값이 20 임을 나타내고 있는 것이다(보라색 박스).

이번엔 ERT의 분리 방식을 살펴보자. 아래 그림은 ERT의 분리 방식을 나타낸 것이다. 분리 시 전체 변수 중에서 랜덤하게 변수를 2개 선택하는 것은 기존 랜덤 포레스트와 동일하다. 하지만 ERT는 변수가 가질 수 있는 모든 값을 고려하지 않고 최소값과 최대값 사이에 하나의 숫자를 랜덤하게(균등 분포에서 난수 하나 생성) 선택하고 이들 중에서 불순도를 가장 작게 하는 조합을 선택한다. 아래 그림에서 변수 3에 대하여 3과 26 사이에 하나의 랜덤 숫자 21.3을 선택했고 변수 7에 대해서는 97과 100 사이에 97.3이라는 숫자를 랜덤하게 뽑은 것을 나타낸 것이다. 이때 변수 3과 이에 대응하는 21.3에 대한 불순도가 작아서 해당 조합(변수 3, 21.3)이 선택되었다.

b. ERT는 랜덤성을 한층 더 강화하여 개별 트리 간 상관성을 낮추고 이를 통해 예측력을 높이고자 한 앙상블 모형이다.
랜덤 포레스트는 매 분리마다 변수를 랜덤하게 선택하고 이를 통해 개별 트리간 상관성을 낮추어 (분산 감소 효과로 인해) 예측력을 향상한다. ERT는 여기에 분리 값마저 랜덤하게 선택함으로써 개별 트리 간 상관성을 더 낮추어 예측력을 높이고자 한 앙상블 모형이다.
2. Extremely Randomized Tree(ERT) 알고리즘
1) 나무의 성장
ERT는 매 분리시 랜덤하게 선택된 각 변수에 대하여 분리 값을 랜덤하게 하나 선택하게 된다. 이때 해당 변수가 연속형인 경우와 범주형인 경우의 분리 값 선택 방법에 대해서 알아보자.
a. 연속형 변수
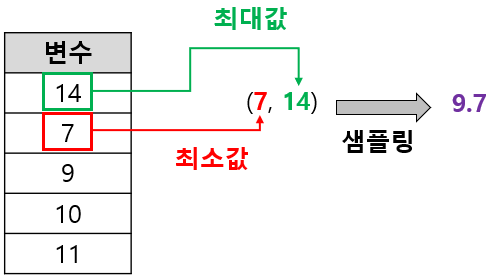
연속형 변수는 학습 데이터에서 그 변수가 취할 수 있는 최소값과 최대값 사이에서 균등 분포 샘플링을 통해 숫자를 하나 선택하게 된다. 아래 그림은 연속형 변수에 대한 분리 값을 선택하는 과정을 나타낸 것이다. 랜덤하게 선택된 변수 중 하나가 아래와 같다면 최소값은 7, 최대값은 14이므로 7과 14 사이에 (균등 분포) 난수 하나를 생성하면 되는 것이다(아래 그림에선 9.7이 나왔다고 가정).
b. 범주형 변수
먼저 해당 범주형 변수의 유니크한 범주를 모두 모은 집합을 $S$라 하고 $S$의 부분 집합 중에서 공집합이 아닌 모든 진 부분집합(Proper Subset)의 집합을 $A_S$라 하자. ERT는 범주형 변수에 대한 분리 값을 선택할 때 $A_S$에 원소$A_1$을 랜덤하게 선택한다. 그러고 나서 $A_1$의 여집합 $S-A_1$의 공집합이 아닌 모든 진 부분 집합에서 샘플링된 집합 $A_2$를 선택하고 $A_1\cup A_2$를 분리 값으로 선택하게 된다.
말이 어려운 것 같지만 아래 예제를 보면 금방 이해할 수 있다. 먼저 선택된 범주형 변수가 취할 수 있는 값이 A, B, C가 있으면 $S$={A, B, C}가 되고 $S$의 공집합이 아닌 모든 진 부분 집합 $A_S$=({A}, {B}, {C}, {A, B}, {A, C}, {B, C})가 된다. $A_S$에서 랜덤하게 선택된 원소 $A_1$={B}라 했을 때 $A_1$의 여집합 {A, C}의 공집합이 아닌 모든 진 부분집합 ({A}, {C})에서 랜덤하게 하나를 뽑은 것을 $A_2$={C}라 하면 최종적으로 분리값을 $A_1\cup A_2$={A, C}로 선택하는 것이다.

c. 변수와 분리 값 선택
매 분리시 전체 변수 중에서 랜덤하게 선택된 $k$개의 변수 $x_1, \ldots, x_k$가 있고 이에 대응하는 분리 값을 $v_1, \ldots, v_k$라 하자. 그렇다면 불순도를 가장 작게 하는 변수 및 분리 값 $(x, v)$를 최종 분리 기준으로 선택하게 된다.
2) 알고리즘
ERT 알고리즘은 다음과 같다.
Algorithm
1 단계) 나무 개수 $m$, 매 분리시 랜덤하게 선택할 변수 개수 $k$, 노드에 들어가는 최소 샘플 수 $n_{\text{min}}$을 선택한다.
$l$ 번째 나무 $T_l(l=1, \ldots, m)$에 대하여 현재 노드에서 다음 중 어느 하나를 만족하는 경우 분류 문제(Classification)에서는 타겟 변수(y)의 가장 높은 빈도를 갖는 라벨을 갖는 터미널 노드, 회귀 문제(Regression)에서는 현재 노드에 포함된 타겟 변수의 평균을 갖는 터미널 노드를 생성한다.
(1) 노드에 포함된 샘플 수 < $n_{\text{min}}$
(2) 랜덤하게 선택된 모든 변수들이 취할 수 있는 값이 하나밖에 없는 경우
(3) 노드에 포함된 타겟 변수들의 값이 하나밖에 없는 경우
만약 (1)~(3) 어느 것도 만족하지 않는다면 2~4 단계)를 반복한다.
2 단계) 전체 변수 중에서 $k$개를 랜덤하게 선택하고 각 변수에 대한 분리 값 $v_i, i=1, \ldots, k$을 랜덤하게 선택한다.
3 단계) 불순도를 최소화하는 변수와 그에 대응하는 분리 값 $x, v$를 선택한다. 만약 $x$가 연속형이라면 $x<v$인 경우 왼쪽 노드, $x\geq v$인 경우 오른쪽 노드로 분리한다. $x$가 범주형이라면 $x\in v$인 경우 왼쪽 노드, $x\in v^c$인 경우 오른쪽 노드로 분리한다.
4 단계) 왼쪽 노드와 오른쪽 노드에 대해서 2~3 단계)를 반복한다.
3) 알고리즘 고찰
a. ERT는 배깅이 아니다.
ERT는 개별 트리를 구성할 때 붓스트랩 샘플을 이용하지 않고 원래의 학습 데이터를 그대로 사용하게 된다. 왜냐하면 붓스트랩을 사용하면 개별 트리 구성할 때 학습 데이터의 일부가 제외될 수 있어서 편의(Bias)가 증가할 수 있기 때문이다. ERT는 이러한 편의(Bias)를 줄이기 위해 붓스트랩 샘플을 이용하지 않는다. 붓스트랩 샘플을 이용하지 않고 개별 트리 간 상관성을 더 낮추는 데 집중하여 전체적인 예측력을 향상하고 싶었던 것이라 생각한다.
b. 랜덤하게 뽑을 변수 개수 : $k$
만약 전체 변수 개수가 $p$라고 한다면 $k$는 1~$p$의 범위를 갖는다. $k$가 작아지면 개별 트리 간 상관성이 낮아지고 $k$가 높아지면 상관성이 어느 정도 증가하게 된다. 극단적으로 $k=p$인 경우 랜덤성은 분리 값을 선택할 때 밖에 생기지 않기 때문이다.
ERT를 소개한 논문에서는 $k$의 기본 선택값을 분류 문제에서는 $k=\sqrt{p}$, 회귀 문제에서는 $k=p$를 제시하였고 기본 선택값으로 설정했을 때 일반적으로 성능이 우수함을 실험적으로 증명하였다.
c. 최소 노드 샘플 수 $n_{\text{min}}$
최소 노드 샘플수 $n_{\text{min}}$이 커지면 개별 나무는 작아져서 높은 편의와 낮은 분산을 갖게 되는 경향이 있고 $n_{\text{min}}$이 작아지면 개별 나무는 커져서 낮은 편의와 높은 분산을 갖게 되는 경향이 있다.
ERT 논문에서는 회귀 문제에서 실험을 통하여 기본 값으로 $n_{\text{min}}=2$로 설정할 것을 제안하였다.
3. 장단점
ERT의 장단점은 다음과 같다.
- 장점 -
a. 분산 감소 효과가 크다.
랜덤하게 변수를 선택하는 것 뿐만 아니라 변수에 대응하는 분리 값을 랜덤하게 선택하므로 개별 트리 간 상관성을 더 낮추어 앙상블 모형의 분산을 최종적으로 더 많이 낮출 수 있다.
b. 변수가 가질 수 있는 모든 값을 고려하지 않으므로 계산량이 적다.
c. 과적합을 피할 수 있다.
- 단점 -
a. 분리값을 랜덤하게 선택하는 과정은 다른 앙상블 기법에 비해 개별 트리의 편의를 증가시킬 수 있다.
b. ERT는 예측력을 극대화하는 대신 해석을 포기하였다.
c. 작은 데이터(Small Data)에 대해서는 과적합이 발생할 수 있다.
- 참고 자료 -
Pierre Geurts, Damien Ernst, Louis Wehenkel - Extremely Randomized Trees
'통계 > 머신러닝' 카테고리의 다른 글
| Bayesian Optimization에 대해서 알아보자! (0) | 2025.10.13 |
|---|---|
| 47. Boruta에 대해서 알아보자. (0) | 2023.05.27 |
| 45. Extended Isolation Forest에 대해서 알아보자. (2) | 2023.05.21 |
| 44. Isolation Forest에 대해서 알아보자. (0) | 2023.05.20 |
| 43. Support Vector Data Description(SVDD)에 대해서 알아보자 with Python (4) | 2023.05.13 |





댓글