이번 포스팅에서는 기존 Isolation Forest의 단점을 극복한 Extended Isolation Forest에 대한 내용을 정리해보고자 한다.
- 목차 -
1. Extended Isolation Forest이란 무엇인가?
2. Extended Isolation Forest 알고리즘
이번 포스팅은 Isolation Forest에 대한 내용을 알아야 하므로 Isolation Forest를 잘 모르는 분들은 아래 포스팅을 참고하기 바란다.
44. Isolation Forest에 대해서 알아보자.
44. Isolation Forest에 대해서 알아보자.
이번 포스팅에서는 모델 기반 이상치 탐지 방법인 Isolation Forest에 대해서 알아보고자 한다. - 목차 - 1. Isolation Forest이란 무엇인가? 2. Isolation Forest 알고리즘 3. 예제 3. 장단점 1. Isolation Forest이란
zephyrus1111.tistory.com
1. Extended Isolation Forest이란 무엇인가?
1) 정의
Extended Isolation Forest는 기존 Isolation Forest를 보완한 알고리즘이며 기존에는 분리를 축에 평행한 방향으로 했다면 Extended Isolation Forest는 임의 방향으로 분리하도록 확장하여 Isolation Forest로는 판별할 수 없었던 이상치를 판별할 수 있게 하였다.
2) 파헤치기
위 정의를 하나씩 살펴보자.
a. Extended Isolation Forest는 기존 Isolation Forest의 단점을 보완했다.
여기서 말하는 Isolation Forest의 단점은 Isolation Forest가 이상치를 잘 구별 못하는 데이터 구조가 있음을 말한다. 다음의 데이터 분포를 살펴보자.
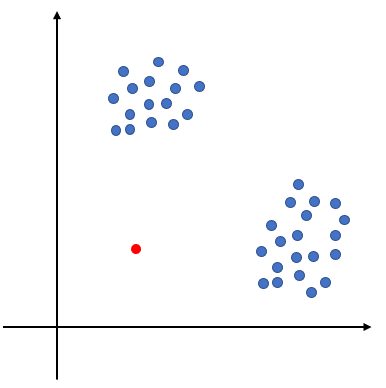
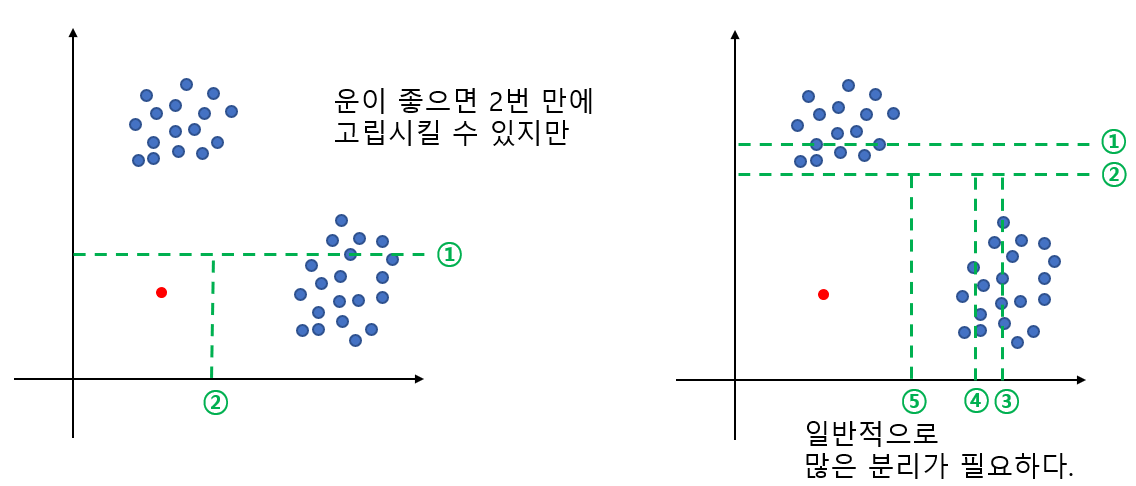
위 그림에서 파란 점은 정상, 빨간 점은 이상치이다. 이때 이상치를 고립시키기 위해 평균적으로 몇 번의 분리가 필요할까? 아래 그림을 보면 왼쪽과 같이 운 좋으면 두 번만에 고립을 시킬 수 있지만 일반적으로는 오른쪽과 같이 많은 분리 작업이 필요하다. 왜냐하면 뭔가 한 축에 대해서 고립시킬 거 같으면 다른 축에 잔챙이(정상 데이터)들이 껴있어서 이를 분리해줘야 하기 때문이다.
Extended Isolation Forest 논문에서 이를 실험적으로 증명했다. 아래 그림에서 왼쪽 그림이 위와 같은 데이터 분포를 갖고 있다. 그리고 오른쪽 그림은 기존 Isolation Forest로 계산된 이상치 점수를 히트맵 형태로 나타낸 것이며 밝을수록 정상 데이터에 가깝고 빨개질수록 이상치인 것이다.
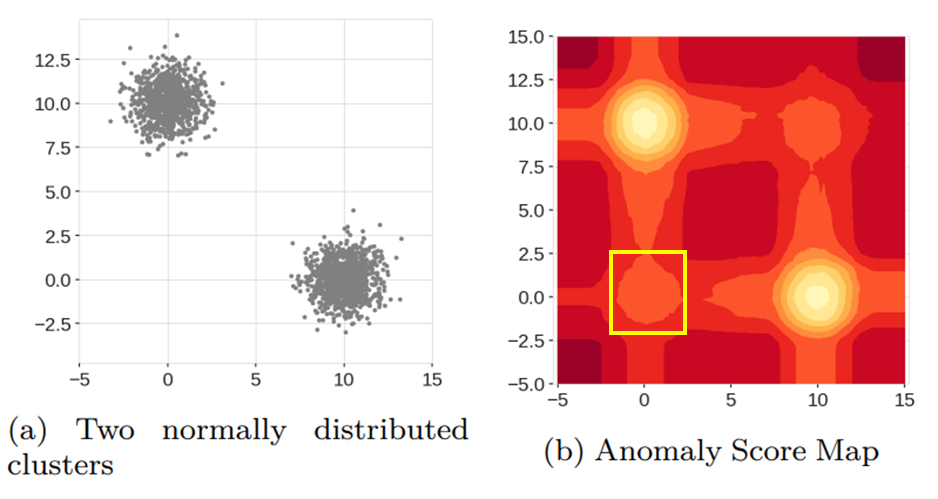
히트맵을 보면 좌하단(노란색 박스)은 데이터 분포로 봤을 때에는 이상치가 되어야 하지만 히트맵상으로는 어느 정도 밝은 영역으로 표시되어 있어 이상치인지 정상인지 구분하기가 애매할 수 있다.
Extended Isolation Forest 논문에서는 기존 Isolation Forest가 이상치를 제대로 판별하지 못하는 데이터 구조의 예시를 하나 제시했다. 아래 그림과 같이 변수들의 관계가 Sine(또는 Cosine)인 것이다. 이런 데이터 분포를 가진 상황에서 Isolation Forest 알고리즘으로 이상치(빨간 점)를 적은 분리 횟수로 고립시키는 게 매우 어렵다.

Extended Isolation Forest 논문에서는 이런 데이터 분포에서도 기존 Isolation Forest로 이상치와 정상을 구별하기 어렵다는 것을 실험적으로 증명하였다.

히트맵에서 파란 사각형 영역은 데이터 분포상 이상치가 되어야 하지만 기존 Isolation Forest로는 이 영역을 (히트맵에서 색이 밝으므로) 정상 데이터로 판단할 가능성이 높게 된다.
기존 Isolation Forest로는 이상치를 제대로 구분하지 못하는 데이터 구조를 Extended Isolation Forest에서는 구분할 수 있도록 보완하였다.
b. Extended Isolation Forest는 임의의 방향으로 분리한다.
임의의 방향이란 랜덤 기울기(Random Slope)와 랜덤 절편(Random Intercept)을 이용하여 영역을 분리한다는 뜻이다. 기존 Isolation Forest는 축의 평행하거나 수직인 방향으로 분리를 진행했다면 Extended Isolation Forest는 이러한 평행 또는 수직이라는 제약 없이 어떤 방향으로든 분리한다(즉, 분리 방향을 확장했다는 점에서 Extended가 붙은 것이다).
아래 그림은 Isolation Forest와 Extended Isolation Forest의 분리 방식을 나타낸 것이다.

임의의 방향으로 분리를 진행하면 기존 Isolation Forest로 잘 잡는 이상치뿐만 아니라 잘 못 잡는 이상치까지도 적은 분리만으로도 고립시킬 수 있는 것이다.
2. Extended Isolation Forest 알고리즘
Extended Isolation Forest 알고리즘에서도 Isolation Forest처럼 나무 개수를 제한하고 데이터가 많은 경우 샘플링을 하기도 한다. 또한 이상치 점수를 계산하는 방법도 Isolation Forest와 같다. 여기서는 기존 Isolation Forest와는 차별화된 Extended Isolation Forest 알고리즘의 핵심 구성요소인 임의 방향 분리에 대해서 알아보고자 한다.
1) 임의 방향 분리
여기서는 임의 방향 분리 방법을 알아보고자 한다. 먼저 $p$차원 데이터 $x_1, x_2, \ldots, x_n, x_i\in \mathbb{R}^p$이 있다고 해보자. 아래 그림은 $p=2$, $n=8$인 상황이다.
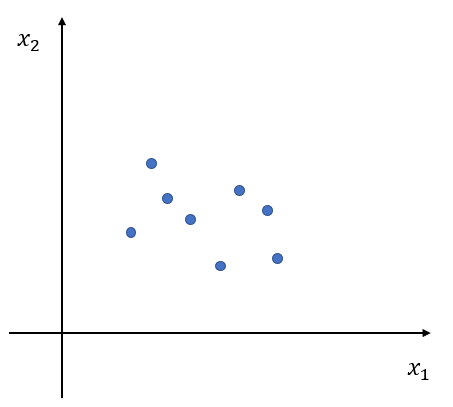
이제 $p$차원 벡터 $v$를 생성한다. 생성하는 방법은 다음과 같다. 1) 각 좌표(Coordinate)에 대해서 표준 정규 분포 $N(0, 1)$에서 난수를 하나 생성한다. $i$번째 좌표에 대해서 생성된 난수값을 $v_i$라 하자. 이제 2) $v = (v_1, v_2, \ldots, v_p)$의 크기가 1이 되도록 한다. 이는 $v$의 $l_2$-norm 값으로 나누어주면 된다.
아래 그림은 샘플링을 통해 $v_1=0.3, v_2 = 0.6$을 만들고 크기가 1이 되도록 한 것이다.
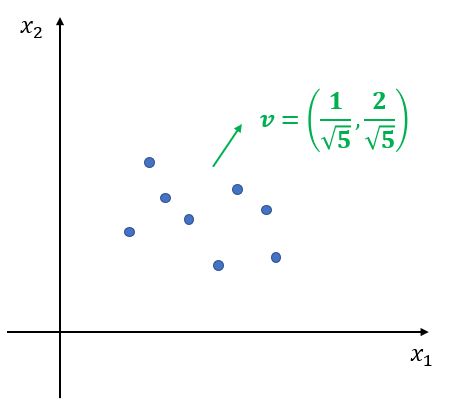
이제 $v$를 법선 벡터로 하는 평면을 찾은 것이며 이 과정이 랜덤 기울기(Random Slope)를 찾은 것이다. 이제 랜덤 절편(Random Intercept) $b$를 찾아야 한다.
랜덤 절편은 주어진 데이터를 이용한 절편 범위 내에서 하나의 숫자를 샘플링한다. 절편 범위는 먼저 $j \in \{ 1, \ldots, p\}$를 고정시킨다. $i=1, \ldots, n$에 대하여 평면 방정식 $(x-x_i)^tv = 0$을 구한다. 이제 $b' = (0, \ldots, 0, b'_j, \ldots, 0)$을 평면 방정식에 넣고 $b'_j$에 대해서 풀면 다음과 같다.
$$b'_{i, j} = \frac{x_i^tv}{v_j} \tag{1}$$
여기서 $v_j$는 $v$의 $j$ 번째 원소이다. 이때 $v_j=0$이 되는 것을 걱정할 수 있겠지만 0과 1 사이에서 샘플링된 것이므로 0이 나올 일은 없다고 보면 된다. 만약 걱정된다면 $v_j\neq 0$인 $j$를 고르면 된다. 또한 (1)은 $i$에 의존하므로 이를 반영하기 위해 $b'_{i, j}$라 표현한 것이다. 이제 $b'_{i, j}$의 최소값과 최대값을 계산한다.
$$ \begin{align} b'_{j, \text{min}} &= \min_{i \in \{ 1, \ldots, n\}} b'_{i, j} \\ b'_{j, \text{max}} &= \max_{i \in \{ 1, \ldots, n\}} b'_{i, j} \end{align} \tag{2}$$
이제 (2)를 통하여 절편 범위 $(b'_{j, \text{min}}, b'_{j, \text{max}})$ 에서 실수 한 개를 샘플링한다. 이를 $b_j$라 하자. 그리고 $b = (0, \ldots, 0, b_j, 0, \ldots, 0)$로 설정한다($b$의 $j$번째를 $b_j$로 채우고 나머지는 0으로 한다는 것이다).
아래 그림은 앞에서 설명한 과정을 통해 랜덤 절편 $b=(0, 3.9)$를 구한 것이다.
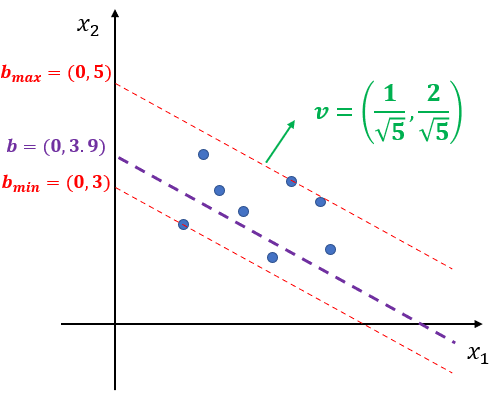
주어진 데이터에 대해서 $x$에 대하여 $(x-b)^tv \leq 0$이면 왼쪽 노드, $(x-b)^tv > 0$이면 오른쪽 노드로 분리하게 된다.

2) 알고리즘
Extended Isolation Forest의 알고리즘은 다음과 같다.
Algorithm
1 단계) 이진 탐색 나무 개수 $t$와 샘플링 데이터 개수 $\psi$를 설정한다. 이때 최대 깊이는 자동적으로 $\log_2\psi$을 올림한 정수값으로 설정된다(평균 나무 깊이의 근사값이라고 한다). 그리고 $F = \phi$로 설정한다.
$i=1, 2, \ldots, t$에 대하여 2~3 단계)를 반복한다.
2 단계) 데이터 X를 $\psi$개만큼 비복원 추출한다. 이를 $X'_i$라 하자. $X'_i$에 대하여 임의 방향 분리 방법을 이용하여 데이터를 고립시킬 때까지 이진 탐색 나무 $T_i$를 성장시킨다.
3 단계) $F= F \cup T_i$로 설정한다.
Extended Isolation Forest 알고리즘으로 완성된 Forest를 이용하여 이상치 점수를 계산하게 된다.
3. 장단점
Extended Isolation Forest의 장단점은 다음과 같다.
- 장점 -
a. 기존 Isolation Forest가 이상치를 잘 잡지 못하는 데이터 분포에 대해서도 이상치를 잘 판별할 수 있다.
b. Isolation Forest와 마찬가지로 샘플링을 통해 결과의 일치성을 유지하면서 계산량을 줄일 수 있다.
- 단점 -
a. Forest 또는 나무의 해석이 어렵다.
임의 방향으로 분리가 진행되기 때문에 축에 수평 또는 수직인 분리에 비해서 해석하기가 어렵다.
b. Isolation Forest와 마찬가지로 나무의 개수, 샘플링 사이즈에 따라서 결과가 달라질 수 있다.
- 참고 자료 -
Sahand Hariri, Matias Carrasco Kind, Robert J. Brunner - Extended Isolation Forest
'통계 > 머신러닝' 카테고리의 다른 글
| 47. Boruta에 대해서 알아보자. (0) | 2023.05.27 |
|---|---|
| 46. Extremely Randomized Tree(ERT)에 대해서 알아보자. (2) | 2023.05.26 |
| 44. Isolation Forest에 대해서 알아보자. (0) | 2023.05.20 |
| 43. Support Vector Data Description(SVDD)에 대해서 알아보자 with Python (4) | 2023.05.13 |
| 42. Local Outlier Factor(LOF)에 대해서 알아보자 with Python (0) | 2023.05.13 |





댓글