이번 포스팅에서는 분류 모형의 성능을 시각적으로 알아보는 방법인 Gain Chart와 Lift Chart에 대해서 알아본다. 또한 파이썬(Python)을 이용하여 구현하는 방법도 알아보려고 한다.
Gain Chart와 Lift Chart
Gain Chart와 Lift Chart를 알아보기 전에 몇 가지 세팅을 하고 넘어가자. 먼저 데이터 $(x_i, y_i), i=1, \ldots, n$가 있다고 하자. 이때 $x_i \in \mathbb{R}^p$인 $p$ 차원 설명 변수 벡터이고 $y_i \in \{ 0, 1 \}$인 범주형 반응 변수이다. 또한 학습된 분류 모형 $f$는 $f : \mathbb{R}^p \rightarrow [0, 1]$인 함수이다. 이 함수는 주어진 $x\in \mathbb{R}^p$에 대하여 $Y=1$인 조건부 확률을 추정한다. 즉,
$$f(x) = \hat{P}(Y=1|x) $$
이다.
1) Gain Chart
a. 정의
Gain Chart는 분류 모형을 사용하여 때 얻게 되는 이득을 시각적으로 나타낸 그림을 말한다. Gain Chart를 그리는 방법은 다음과 같다.
Gain Chart 그리는 방법
1) 분류 모형 $f$를 이용하여 $x_i$가 주어졌을 때 $Y_i=1$인 확률을 계산하고 이 확률값으로 데이터를 오름차순으로 정렬한다.
2) 데이터를 10 등분한다. 데이터를 다르게 자를 수도 있겠으나 보통은 10 등분을 하는 것 같다.
3) Gain 통계량을 계산한다. 이를 위해 몇가지 통계량을 같이 계산해야 한다. 먼저 $y_i=1$인 데이터 개수를 $N_y$이라하자. $y_i=1$인 데이터 빈도수(개수) $P_k, k=1, \ldots, 10$를 계산한다. 이제 각 구간별 Gain 통계량 $IG_k$를 다음과 같이 계산한다.
$$IG_k = \frac{P_k}{N_y}, k=1, \ldots, K$$
이제 진정한 Gain 통계량 $G_k$을 계산할 수 있다. 상위 랭크에서 부터 구간별 Gain 통계량 $IG_k$를 누적한다.
$$G_k = \sum_{j=1}^kIG_j$$
IG_k와 G_k의 차이점은 전자는 개별값이고 후자는 누적값이다.
4) 이제 구간 $k$에 대한 Gain 통계량 $G_k$를 차트로 표현한다.
Gain 통계량은 해당 구간의 데이터 개수 대비 $y_i=1$인 빈도수의 비를 나타낸다. 상위 랭크에서 이 값이 클수록 그만큼 우리가 찾고 싶은 클래스를 잘 찾았다는 것이 되므로 분류 모형의 성능이 높다는 것을 의미한다. 이를 좀 더 풀어서 얘기하면 우리가 찾고 싶은 클래스를 찾는 데 있어서 분류 모형을 사용하는 것에 대한 이득이 있다는 것을 의미하는 것이다(Gain 통계량으로 부르는 이유이기도 하다).
Gain Chart는 어떤 데이터를 더 관리해야하는지 알려준다. 예를 들어 마케팅에서는 Gain Chart를 이용하여 어떤 고객을 중점적으로 마케팅 작업을 해야 하는지 알아볼 수 있다. 만약 아래 그림과 같은 Gain Chart를 얻었다면 이미 3등급 내에서 Gain을 0.9를 달성하므로 전체 고객을 다 상대할 필요 없이 상위 30%만 타겟으로 하여 마케팅을 한다면 더 효율적인 마케팅 작업을 할 수 있게 된다. 몇 등급까지 봐야하는가는 보통 도메인 전문가와 상의하여 정하거나 분석자가 주관적으로 판단한다.

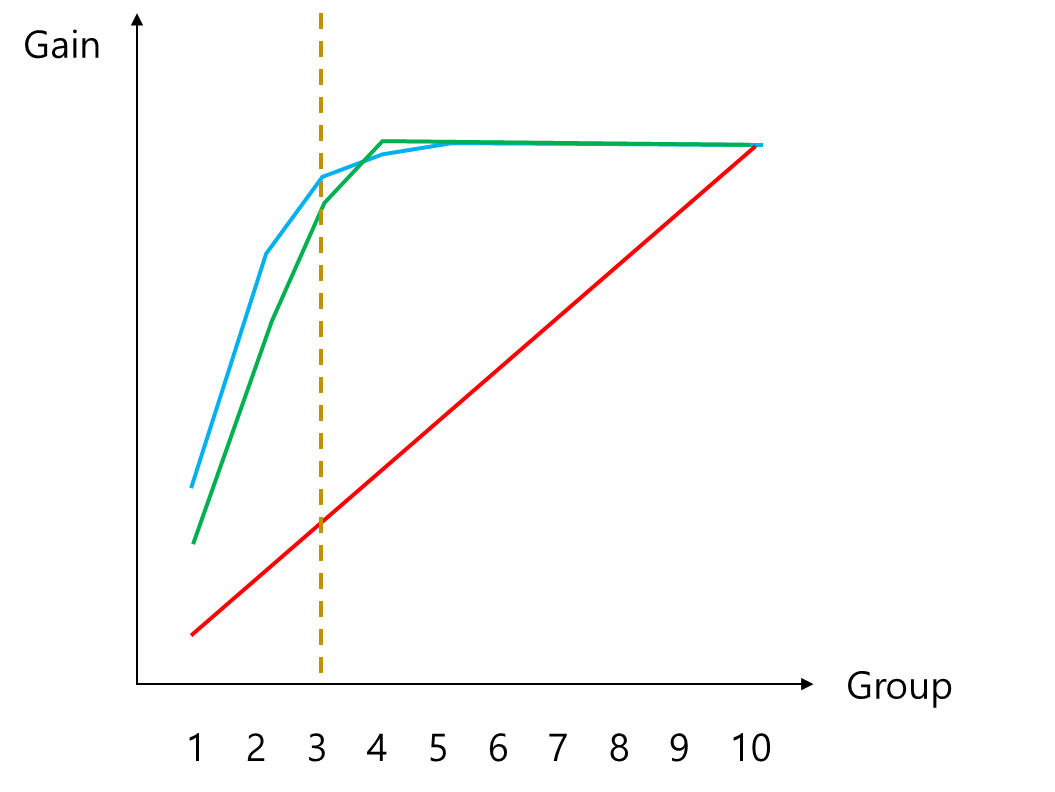
Gain Chart는 그 자체로도 유용하지만 분류 모형 간 성능 비교도 할 수 있다. 여러 분류 모형들에 대하여 Gain Chart를 그려보고 상위 특정 구간까지 Gain이 높은 모형을 좋은 모형이라고 판단하게 된다. 만약 세 개의 분류 모형에 대하여 Gain Chart가 아래와 같고 상위 3개 구간까지만 본다고 한다면 파란색에 대응하는 분류 모형이 좋다고 판단하는 것이다.
b. 파이썬 구현
이제 Gain Chart를 그리는 작업을 파이썬으로 구현해보자. 먼저 Gain Table을 만드는 함수 get_gain_table을 구현했다. 이 함수는 먼저 각 데이터에 대하여 학습된 분류 모형으로 $y_i=1$인 확률을 계산한 뒤 데이터를 이 확률을 이용하여 내림차순으로 정렬한다. 그런 다음 기본적으로 데이터를 10등분한 다음 구간별 $y_i=1$인 데이터 개수, 구간별 데이터 개수, 구간별 Gain 통계량, Gain 통계량을 각각 계산하고 이를 데이터프레임에 정리하여 출력한다. Gain Chart는 Gain Table을 이용하여 쉽게 그릴 수 있다. Gain Table에 구간별 데이터 개수(num_of_data)도 포함시켰다.
def get_gain_table(clf, y, num_group=10):
res_df = pd.DataFrame()
res_df['response'] = y
class_idx = np.where(clf.classes_==1)[0][0]
res_df['prob'] = clf.predict_proba(X)[:, class_idx]
res_df = res_df.sort_values('prob', ascending=False).reset_index(drop=True) ## 확률값으로 내림차순
res_df['temp'] = range(len(res_df))
labels = list(range(1, num_group+1))
res_df['group'] = pd.qcut(res_df['temp'], num_group, labels = labels) ## 데이터 num_group 수만큼 분할
res_df = res_df.groupby('group').agg({'response':['sum', 'count']}).reset_index() ##
res_df.columns = ['group','num_of_response', 'num_of_data']
res_df = res_df.sort_values('group')
res_df['individual_gain'] = res_df['num_of_response']/np.sum(y) ## 구간별 gain
res_df['gain'] = res_df['individual_gain'].cumsum() ## gain
return res_df
이제 실제 데이터를 이용하여 Gain Chart를 그려보자. 여기서는 R에서 제공하는 고객 이탈률 데이터(mlc_churn)를 사용했다. 해당 데이터는 아래에 첨부해 두었다.
위 엑셀 파일에서 description 시트에 칼럼에 대한 정보를 적어놓았다.

우리가 예측해야하는 것은 churn 칼럼이다. 이제 이 데이터를 이용하여 분류 모형을 학습해 보자. 여기서는 랜덤포레스트와 의사결정나무 모형을 이용하여 학습하고 각 모형에 대하여 Gain Chart를 그려보면서 비교하고자 한다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
churn_df = pd.read_excel('./churn.xlsx') ## 데이터 로드
X = churn_df.drop('churn', axis=1)
X = X[X.columns[5:]] ## 5 번째 칼럼부터 사용
y = churn_df['churn'].map(lambda x:1 if x=='yes' else 0) ## churn 칼럼을 0-1로 변환
clf1 = RandomForestClassifier(max_depth=5, random_state=0).fit(X, y) ## 랜덤 포레스트 모형 학습
clf2 = DecisionTreeClassifier(max_depth=5).fit(X, y) ## 의사결정나무 모형 학습
이제 Gain Table을 만들어서 확인해보자.
res_df1 = get_gain_table(clf1, y, num_group=10) ## 랜덤 포레스트 Gain Table
res_df2 = get_gain_table(clf2, y, num_group=10) ## 의사결정나무 Gain Table
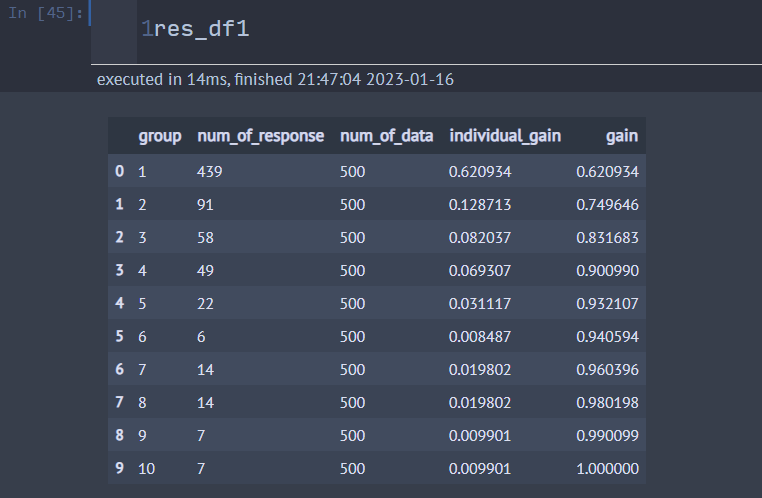
우선 랜덤 포레스트 모형을 이용하여 만든 Gain Table을 확인해 보자.
이제 Gain Chart를 그려보자. Gain Table만 있으면 그리는 건 너무 쉽다.
fig = plt.figure(figsize=(8,8))
fig.set_facecolor('white')
ax = fig.add_subplot()
ax.plot(res_df1['group'], res_df1['gain'], marker='o', label='Random Forest')
ax.plot(res_df2['group'], res_df2['gain'], marker='o', label='Decision Tree')
ax.set_ylim((0,1.1))
ax.set_title('Gain Chart', fontsize=20)
ax.legend()
plt.show()

전 구간에서 Random Forest 모형이 더 좋은 학습 성능을 보이고 있다.
c. 장단점
Gain Chart는 목표 마케팅에서 마케팅 작업을 적용할 집중 타겟을 시각적으로 파악할 수 있다는 점에서 그 자체로도 유용하며 분류 모형별로 Gain Chart를 그려서 어떤 분류 모형이 좋은지 시각적으로 파악할 수 있다. 또한 Gain Chart는 그리는 과정이 간단하여 (코딩을 할 줄 아는) 누구나 쉽게 그릴 수 있다. 하지만 어느 등급까지를 봐야 하는가에 대한 구체적인 기준이 없어 주관적 판단이 필요하다. 또한 특정 등급 내에서 두 Gain 직선 간 크로스가 된다면 어떤 분류 모형을 선택해야 하는지 어려울 수 있다. 예를 들어 3 등급 내에서 아래와 같이 두 분류 모형의 Gain 직선이 크로스 되는 경우처럼 말이다. 이때에는 대안으로 3 등급 내 직선 아래 면적의 크기가 큰 것을 좋은 모형으로 판단하는 것도 고려해 볼 만하다.

2) Lift Chart
a. 정의
Lift Chart는 분류 모형을 사용하지 않았을 때보다 사용한 경우 얼마나 더 이익이 되는지를 시각적으로 나타낸 그림을 말한다. Lift Chart를 그리는 방법은 다음과 같다.
Lift Chart 그리는 방법
1) 분류 모형 $f$를 이용하여 $x_i$가 주어졌을 때 $Y_i=1$인 확률을 계산하고 이 확률값으로 데이터를 오름차순으로 정렬한다.
2) 데이터를 10 등분한다. 데이터를 다르게 자를 수도 있겠으나 보통은 10 등분을 하는 것 같다.
3) Lift 통계량을 계산한다. 이를 위해 몇 가지 통계량을 같이 계산해야 한다. 먼저 각 구간별 데이터 수 $N_k$와 $y_i=1$인 데이터 빈도수(개수) $P_k, k=1, \ldots, 10$를 계산한다. 이제 각 구간별 반응율(Response) $R_k$를 계산한다(Gain 통계량 $IG_k$와 같다).
$$R_k = \frac{P_k}{N_k}, k=1, \ldots, K$$
다음으로 Baseline Lift 통계량을 $BL$ 계산한다.
$$BL = \frac{| \{ i : y_i = 1 \} |}{n}$$
여기서 $|A|$는 집합 $A$의 원소 개수를 말한다.
이제 Lift 통계량 $L_k$을 계산할 수 있다.
$$L_k = \frac{R_k}{BL}$$
4) 이제 구간 $k$에 대한 Lift 통계량 $L_k$를 차트로 표현한다.
$BL$은 모형을 사용하지 않았을 때 $x_i$가 주어진 경우 $y_i=1$인 조건부 확률이 된다. 이는 $x_i$가 주어진 경우 0과 1 사이에서 난수를 생성하여 그 값이 $BL$보다 작은 경우 $y_i=1$ 큰 경우 $y_i=0$으로 예측하겠다는 것이다(이를 Random Model이라고도 한다). Lift 통계량은 해당 구간에서 모형을 사용하지 않았을 경우보다 모형을 사용했을 때 얻을 수 있는 정분류율의 증가분을 의미한다. 따라서 해당 구간에서 Lift 통계량이 1보다 커야 의미가 있고 그 값이 많이 클수록 분류 모형으로 얻는 이득이 크다는 것을 의미한다.
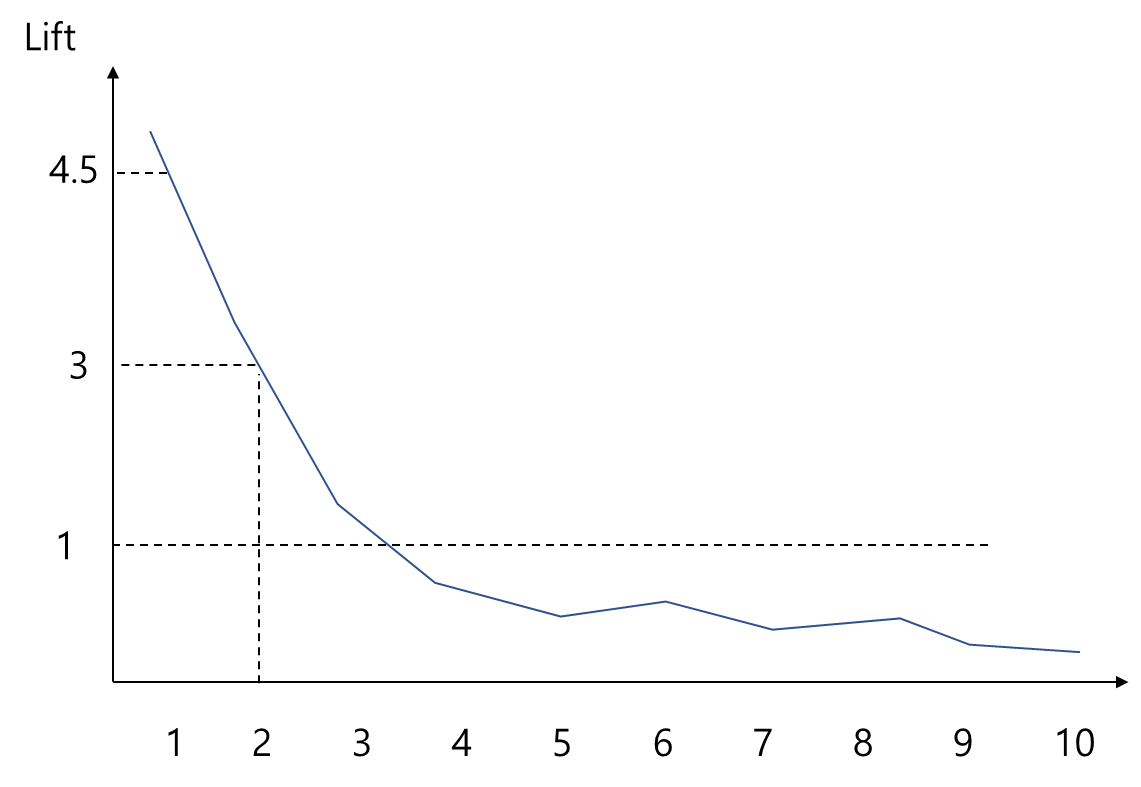
Lift Chart는 Gain Chart와 마찬가지로 어떤 데이터를 더 집중적으로 관리해야 하는지 알려준다. 예를 들어 마케팅에서는 Lift Chart를 이용하여 어떤 고객을 중점적으로 마케팅 작업을 해야하는지 알아볼 수 있는데 아래 그래프에서 1보다 큰 등급은 상대적으로 높은 등급이라고 한다면 1, 2 등급에 대응하는 고객을 대상으로 마케팅을 수행하게 된다.
Lift Chart도 분류 모형 간 성능 비교도 할 수 있다. 여러 분류 모형들에 대하여 Lift Chart를 그려보고 상위 특정 구간까지 Lift 값이 높은 곳에서 빠르게 감소할수록 상위 구간에서 중요 클래스($y_i=1$)를 정확하게 예측했다는 것이므로 좋은 모형이라고 판단하게 된다. 만약 세 개의 분류 모형에 대하여 Lift Chart가 아래와 같고 상위 3개 구간까지만 본다고 한다면 초록색에 대응하는 분류 모형이 좋다고 판단하는 것이다.

b. 파이썬 구현
이제 Lift Chart를 파이썬으로 그려보자. 먼저 Lift Table을 만드는 함수 get_lift_table을 구현했다. 이 함수는 먼저 각 데이터에 대하여 학습된 분류 모형으로 $y_i=1$인 확률을 계산한 뒤 데이터를 이 확률을 이용하여 내림차순으로 정렬한다. 그런 다음 기본적으로 데이터를 10 등분한 다음 각 구간별로 $P_k, N_k, R_k, L_k$를 계산하고 이를 데이터프레임에 정리하여 출력한다. Lift Chart는 Lift Table을 이용하여 쉽게 그릴 수 있다.
def get_lift_table(clf, y, num_group=10):
res_df = pd.DataFrame()
res_df['response'] = y
class_idx = np.where(clf.classes_==1)[0][0]
res_df['prob'] = clf.predict_proba(X)[:, class_idx]
res_df = res_df.sort_values('prob', ascending=False).reset_index(drop=True) ## 확률값으로 내림차순
res_df['temp'] = range(len(res_df))
labels = list(range(1, num_group+1))
res_df['group'] = pd.qcut(res_df['temp'], num_group, labels = labels) ## 데이터 num_group 수만큼 분할
res_df = res_df.groupby('group').agg({'response':['sum', 'count', 'mean']}).reset_index() ##
res_df.columns = ['group','num_of_response', 'num_of_data', 'response_rate']
res_df = res_df.sort_values('group')
baseline_lift = np.sum(y)/len(y)
res_df['lift'] = res_df['response_rate']/baseline_lift ## 구간별 gain
return res_df
Gain Chart에서 사용했던 고객 이탈 데이터를 이용하여 랜덤 포레스트와 의사결정나무 모형을 학습했다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
churn_df = pd.read_excel('./churn.xlsx') ## 데이터 로드
X = churn_df.drop('churn', axis=1)
X = X[X.columns[5:]] ## 5 번째 칼럼부터 사용
y = churn_df['churn'].map(lambda x:1 if x=='yes' else 0) ## churn 칼럼을 0-1로 변환
clf1 = RandomForestClassifier(max_depth=5, random_state=0).fit(X, y) ## 랜덤 포레스트 모형 학습
clf2 = DecisionTreeClassifier(max_depth=5).fit(X, y) ## 의사결정나무 모형 학습
이제 각 모형에 대한 Lift Table을 만들어보자.
res_df1 = get_lift_table(clf1, y, num_group=10) ## 랜덤 포레스트 Lift Table
res_df2 = get_lift_table(clf2, y, num_group=10) ## 의사결정나무 Lift Table
랜덤 포레스트 모형에 대한 Lift Table을 출력하면 다음과 같다.
res_df1

이제 Lift Chart를 그려보자. 여기서 1에 대한 수평선을 그어서 1보다 큰 구간이 어디인지 확인해 보았다.
fig = plt.figure(figsize=(8,8))
fig.set_facecolor('white')
ax = fig.add_subplot()
ax.plot(res_df1['group'], res_df1['lift'], marker='o', label='Random Forest')
ax.plot(res_df2['group'], res_df2['lift'], marker='o', label='Decision Tree')
ax.set_title('Lift Chart', fontsize=20)
ax.axhline(1, linestyle='--', color='r')
ax.legend()
plt.show()
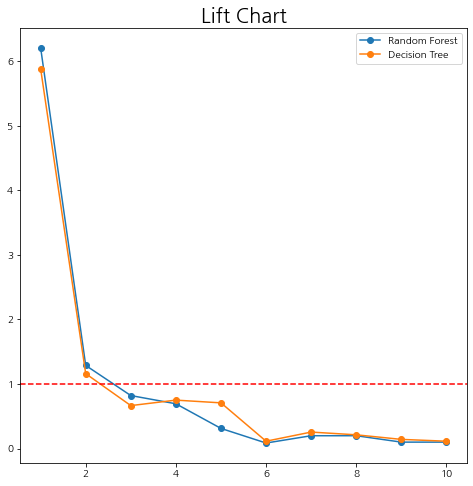
1보다 큰 구간은 두 모형 모두 2 구간까지이며 이때 랜덤 포레스트 모형의 감소분이 더 크므로 랜덤 포레스트가 더 좋다고 할 수 있다.
c. 장단점
Lift Chart는 Gain Chart와 마찬가지로 마케팅 집중 대상을 시각적으로 파악할 수 있다는 점에서 그 자체로도 유용하다. 또한 분류 모형별로 Lift Chart를 그려서 어떤 분류 모형이 좋은지 시각적으로 파악할 수 있다. 또한 Lift Chart는 그리는 과정이 매우 쉬워서 (코딩을 할 줄 아는) 누구나 쉽게 그릴 수 있다. 하지만 Gain Chart와 마찬가지로 봐야 할 등급을 선정하는 구체적인 기준이 없으므로 분석가나 도메인 전문가의 주관적 판단이 필요하다. 또한 특정 구간 내에서 두 직선 간 크로스가 된다면 어떤 분류 모형을 선택해야 하는지 어려울 수 있다.





댓글