이번 포스팅에서는 Scikit-Learn(sklearn)을 이용하여 K-근접 이웃(K-nearest neighbor) 분류 및 회귀 모형을 학습하고 예측하는 방법 그리고 Scikit-Learn에서 제공하는 관련 기능에 대해서 알아보고자 한다. K-근접 이웃(K-nearest neighbor)을 이용한 예측은 분류 및 회귀 문제에 모두 적용할 수 있으므로 이에 대해서 각각 알아본다.
1. 분류 문제(KNeighborsClassifier)
K-근접 분류 및 회귀에 대한 개념은 아래 포스팅을 참고하기 바란다.
[머신 러닝] 2. K-최근접 이웃 분류기(K-Nearest Neighbor Classifier)에 대하여 알아보자 with Python
[머신 러닝] 2. K-최근접 이웃 분류기(K-Nearest Neighbor Classifier)에 대하여 알아보자 with Python
이번 포스팅에서는 k-근접 이웃 분류기에 대해서 알아보고자 한다. k-근접 이웃 분류기는 실제로 잘 활용되지는 않지만 데이터를 이용하여 분류하는 기본적인 과정을 이해하는데 유용하며 때에
zephyrus1111.tistory.com
1. 분류 문제(KNeighborsClassifier)
1) 학습
K-최근접 이웃 분류기를 만들기 위한 데이터로 붓꽃 데이터(Iris Data)를 사용한다. 먼저 필요한 모듈을 임포트하고 데이터를 불러온다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
from sklearn.datasets import load_iris, load_boston
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressor
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = [iris.target_names[x] for x in iris.target]
Scikit-Learn(sklearn)에서는 KNeighborsClassifier 클래스를 이용하여 분류기를 학습할 수 있다. 이때 근접 데이터 수 $k$를 n_neighbors 인자를 통하여 설정할 수 있다. 그리고 KNeighborsClassifier 클래스의 fit 메서드를 이용하여 분류기를 학습한다(사실 학습이라기 보단 학습 데이터를 저장한다고 보는 것이 맞다). 이때 설계 행렬 $X$와 반응 변수 벡터 $y$를 fit 메서드 인자로 넘겨준다.
X = df.drop('species', axis=1)
y = df['species']
clf = KNeighborsClassifier(n_neighbors=5).fit(X, y) ## k 개수 설정2) 예측
학습이 완료되면 predict 메서드와 score 메서드를 이용하여 각각 예측 라벨과 성능을 살펴볼 수 있다. 특히 KNeighborsClassifier 클래스는 kneigbors 메서드를 이용하여 주어진 데이터와 근접한 데이터 인덱스를 n_neighbors에 지정한 수만큼 알아낼 수 있다.
## 예측
print(clf.predict(X.values[:1])) ## 첫 번째 학습 데이터의 예측 결과
print(clf.kneighbors(X.values[:1])[1]) ## 주어진 데이터에 5개의 근접 데이터 인덱스
print('정확도 : ', clf.score(X, y)) ## 학습 정확도
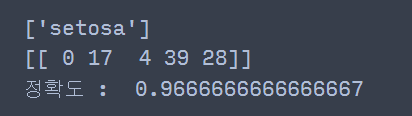
위 코드에서 세 번째 줄에서 주어진 데이터와 근접한 5개의 인덱스는 각각 0, 17, 4, 39, 28인 것을 알 수 있다.
2. 회귀 문제(KNeighborsRegressor)
1) 학습
여기서는 보스턴 집값 데이터를 사용하여 K-최근접 이웃 방법을 회귀 문제에 적용해보고자 한다.
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df['MEDV'] = boston.target
KNeighborsRegressor 클래스를 이용하면 K-최근접 이웃 방법을 이용한 회귀 모형을 학습할 수 있다. 사용 방법은 분류 문제에서 살펴본 것과 동일하므로 설명은 생략한다.
X = df.drop('MEDV', axis=1)
y = df['MEDV']
reg = KNeighborsRegressor(n_neighbors=5).fit(X, y) ## k 개수 설정2) 예측
학습이 완료된 후 predict 메서드와 score 메서드를 이용하여 각각 예측값과 성능을 알아볼 수 있다. 또한 KNeighborsRegressor 클래스도 kneigbors 메서드를 이용하여 주어진 데이터와 근접한 데이터 인덱스를 n_neighbors에 지정한 수만큼 알아낼 수 있다.
## 예측
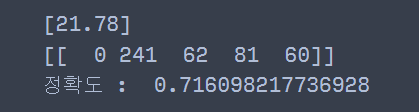
print(reg.predict(X.values[:1])) ## 첫 번째 학습 데이터의 예측 결과
print(reg.kneighbors(X.values[:1])[1]) ## 주어진 데이터에 5개의 근접 데이터 인덱스
print('정확도 : ', reg.score(X, y)) ## 학습 정확도





댓글