Scikit-Learn(sklearn)에서는 DBSCAN 클래스를 이용하여 DBSCAN 클러스터링을 수행할 수 있다. 이번 포스팅에서는 Scikit-Learn(sklearn)에서 제공하는 DBSCAN의 사용법을 알아보려고 한다.
DBSCAN에 대한 개념은 아래 포스팅을 참고하면 된다.
30. DBSCAN에 대해서 알아보자 with Python
30. DBSCAN에 대해서 알아보자 with Python
이번 포스팅에서는 클러스터링 알고리즘 중 하나인 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)에 대해서 알아보고자 한다. - 목차 - 1. DBSCAN이란 무엇인가? 2. DBSCAN 알고리즘 3. DBSCAN 장단
zephyrus1111.tistory.com
DBSCAN 사용법
코드를 통해 DBSCAN 사용법을 알아보자. 먼저 DBSCAN을 적용할 데이터를 아래에 첨부해 두었으니 다운을 받고 시작하자.
먼저 데이터 분포를 살펴보자. 여기서는 지출 점수(Spending_Score)와 연 수입(Annual_Income)만 고려한다.
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
df = pd.read_excel('../../machine_learning/dbscan_test.xlsx')
fig = plt.figure()
fig.set_facecolor('white')
ax = fig.add_subplot()
ax.scatter(df['Spending_Score'], df['Annual_Income'])
plt.show()
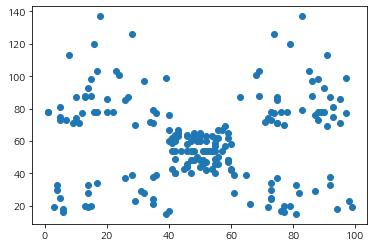
이제 DBSCAN을 적용해보자. DBSCAN은 기본적으로 반경 eps와 반경 내에 들어가야 하는 최소 샘플 수 min_sampes를 인자로 받는다.
DBSCAN(eps = 0.5, min_samples = 5)
그리고 fit 메서드에 데이터를 넘겨줘서 호출하면 클러스터링을 수행한다.
X = df[['Spending_Score', 'Annual_Income']].values
cluster = DBSCAN(eps=10, min_samples=5).fit(X)
먼저 핵심 데이터(Core Point)와 비 핵심 데이터(Non-core Point)의 분포는 어떤지 살펴보자. 핵심 데이터의 인덱스는 core_sample_indices_ 필드에 저장되어 있다. 따라서 전체 인덱스에서 핵심 데이터에 대응하는 인덱스는 1 아니면 0으로 나눈 뒤 시각화해보자.
core_samples_indices = cluster.core_sample_indices_
is_core_samples = [1 if i in core_samples_indices else 0 for i in range(X.shape[0]) ]
fig = plt.figure()
fig.set_facecolor('white')
ax = fig.add_subplot()
ax.scatter(df['Spending_Score'], df['Annual_Income'], c=is_core_samples)
plt.show()
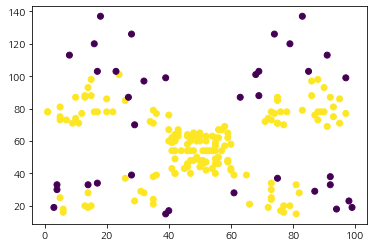
이제 DBSCAN을 통한 클러스터링 결과를 시각화해보자. 클러스터링 결과는 labels_에 저장되어 있다.
cluster_label = cluster.labels_ ## 클러스터링 결과
fig = plt.figure()
fig.set_facecolor('white')
ax = fig.add_subplot()
ax.scatter(df['Spending_Score'], df['Annual_Income'], c=cluster_label)
plt.show()
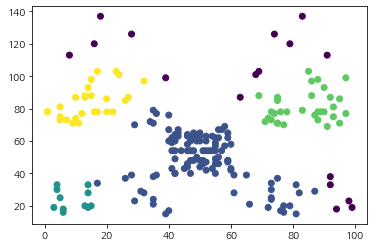
위 그림을 보면 4개의 클러스터가 생성된 것을 알 수 있다.





댓글