이번 포스팅에서는 이전 포스팅에서 다룬 Grouped Binary 데이터의 특수한 케이스인 Ungrouped Binary 데이터에 대하여 GLM을 적합시키는 방법에 대해 알아보려고 한다. 먼저 우도 방정식과 모형 적합에 관한 내용을 여기에 다루었으니 반드시 읽어보자.
여기서 다루는 내용은 다음과 같다.
1. Ungrouped Binary 데이터란?
Ungrouped Binary 데이터란 데이터 하나에 대하여 2개의 범주를 갖는 반응 변수가 하나 있는 것이다. 말을 어렵게 했는데 지도학습(Supervised Learning)에서 2진(Binary) 분류 모형을 만들기 위해 사용하는 학습 데이터라고 생각하면 쉽다. Ungrouped Binary 데이터는 아마도 Grouped Binary 데이터와 구별하기 위해 이런 이름이 붙여진 것 같다.
예를 들어 아래의 표를 보자.

관심의 대상이 되는 변수(반응 변수)는 심장병 발생 여부이며 이는 2개의 범주(유, 무)를 갖고 있다. 따라서 Binary 데이터이며 그룹화되어 있지 않다. 따라서 이 데이터는 Ungrouped Binary 데이터이다.
2. 모형 적합 알고리즘 유도
먼저 i 번째 반응 변수를 yi(i=1,…,n), 설명 변수 벡터를 ˜xi=(1,x1i,x2i,…,xpi)t라 하자.
이제 Fisher Scoring 알고리즘을 유도할 것이다.
1. 모형 설정
반응 변수의 특정 범주(예 : 남자, 가짜 지폐 등)가 나타날 사건을 성공으로 본다면 yi는 성공의 확률이 pi인 베르누이 분포를 따른다고 볼 수 있다. 여기서 데이터를 통해서 추정해야 할 부분은 pi이고 연결 함수 g를 이용하여 다음과 같이 모형을 설정한다.
g(pi)=βt˜xi
2. 우도 함수(Likelihood Function)
f(yi|pi)=pyii(1−pi)1−yi=exp[yilogpi+(1−yi)log(1−pi)]=exp[yilog(pi1−pi)+log(1−pi)]=exp{[yiθi−b(θi)]/a(ϕ)+c(yi,ϕ)}
여기서 θi=log[pi/(1−pi)], b(θi)=log[1+exp(θi)], a(ϕ)=1, c(yi,ϕ)=0이다. 따라서 yi의 확률분포는 exponential dispersion family가 된다. Ungrouped Binary 데이터는 Grouped Data 데이터에서 ni=1인 경우이다.
3. 연결 함수(Link Function)
이제 연결 함수 g를 정해야 한다. yi의 확률분포가 exponential dispersion family이므로 canonical 연결 함수를 쓰면 된다. canonical 연결 함수의 정의는 여기에 정리해놓았다.
θi=ηi=g(μi)=g(pi)=log(pi1−pi)
여기서 μi=E(yi)=pi이다. 이는 Grouped Binary 데이터에서의 연결 함수와 동일하다.
4. 알고리즘
Grouped Binary 데이터에서 유도한 알고리즘과 정확히 일치한다. 이에 대한 내용은 여기를 참고하자.
3. 실제 데이터 적용
Ungrouped Binary 데이터에 GLM 모형을 적합해보자. 사실 우리가 잘 알고 있는 로지스틱 회귀 모형을 적합하는 것이다. 이번 포스팅에서 사용할 데이터를 다운받자.
필요한 모듈을 임포트 하고 데이터를 불러오자.
import pandas as pd import numpy as np import statsmodels.api as sm import matplotlib.pyplot as plt from scipy.stats import norm df = pd.read_csv('./disease_outbreak.csv')
간단한 데이터 전처리가 필요하다. 데이터에 범주형 변수가 있기때문이다. 이를 더미 변수로 바꾸어주어야 한다. Pandas에서 제공하는 get_dummies를 이용하여 범주형 변수를 더미 변수로 바꿀 수 있다. 더미 변수에 접두어는 prefix 인자로 지정할 수 있고 참조 범주(Reference class)는 drop_first를 통해 제거해주었다.
## 가변수로 변환하기 ss_dummy = pd.get_dummies(df['Social_Status'], drop_first=True, prefix='SS') ss_sector = pd.get_dummies(df['Sector'], drop_first=True, prefix='Sector') df = pd.concat([df[['Age']], ss_dummy, ss_sector, df[['Disease_Status']]],axis=1)
이제 모형을 적합해볼 시간이다. 먼저 시그모이드 함수와 로짓 함수를 정의했다. 왜냐하면 필요하니까..
## 필요 함수 def get_pi(x,b): return np.exp(np.inner(x,b))/(1+np.exp(np.inner(x,b))) def logit(x): return np.log(x/(1-x))
다음으로 반응 변수와 모형 행렬(Model Matrix)를 정해준다.
## 기본 세팅 X = df[['Age','SS_2','SS_3','Sector_2']] X = sm.add_constant(X) X = np.array(X) X_t = X.transpose() y = df['Disease_Status']
이제 초기값을 설정해준다. 반응 변수에 0이 포함되어 있어서 로짓함수를 계산할 수 없다. 이때에는 반응 변수의 평균 벡터를 이용했다. 초기값에 대한 부분은 여기를 참고하자.
# 초기값 설정 X_tX_inv = np.linalg.inv(np.matmul(X_t,X)) y_mean = y.mean()*np.ones(len(y)) beta = np.matmul(X_tX_inv,np.matmul(X_t,logit(y_mean)))
다음은 모형 적합 과정을 코드로 구현한 것이다. 코드 설명은 이전 포스팅과 동일하므로 생략한다.
## 모델 적합 max_iter = 100 tolerance = 0.0001 num_iter = 0 betas = [] ## 스텝별로 베타 값을 저장 betas.append(beta) ## 초기값 저장 while num_iter <= max_iter: num_iter += 1 W_element = [] ## W의 대각원소 D_element = [] ## D의 대각 원소 pis = [] for i in range(len(df)): pi = get_pi(X[i],beta) W_element.append(pi*(1-pi)) D_element.append(pi*(1-pi)) pis.append(pi) pis = np.array(pis) W = np.diag(W_element) ## W D = np.diag(D_element) ## D X_tWX = np.matmul(np.matmul(X_t,W),X) X_tWX_inv = np.linalg.inv(X_tWX) mu = pis ## mu z = np.matmul(X,beta)+np.matmul(np.linalg.inv(D),y-mu) ## z X_tWz = np.matmul(X_t,np.matmul(W,z)) next_beta = np.matmul(X_tWX_inv,X_tWz) ## next beta diff = np.linalg.norm(next_beta-beta) if diff < tolerance: beta = next_beta betas.append(beta) print('tolerance acheived') break else: beta = next_beta betas.append(beta)
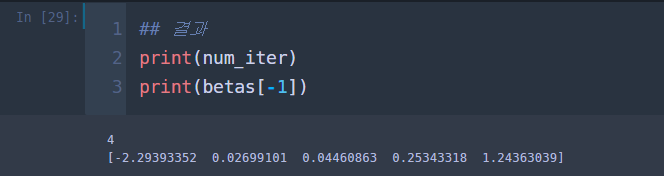
총 4번의 스텝이 걸렸으며 절편항 포함 5개 회귀 추정량이 구해졌다. 이번엔 초기값을 모두 0으로 놓고 모형을 적합해보았다.
## 초기값 설정 num_parameter = X.shape[1] beta = np.zeros(num_parameter)
초기값만 바꾸고 모형 적합 코드를 실행해보자.
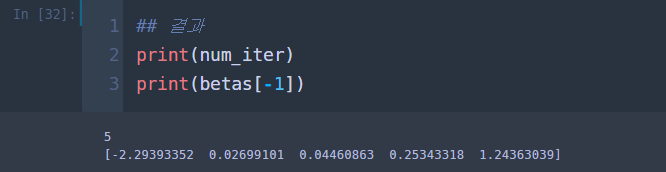
스텝이 1번더 늘어났다. 추정량은 모두 동일하다. 처음에 설정한 초기값이 좋긴한데 그냥 모두 0으로 초기화해도 상관없을 것 같다. 초기값에 따른 Age 회귀 추정량의 변화를 시각화해보았다.
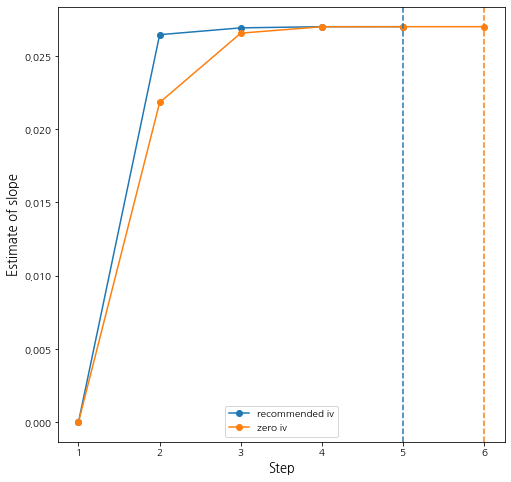
수직 점선은 마지막 스텝을 나타내며 스텝이 1단계 늘어난 것은 초기화 단계도 포함되었기 때문이다. 다음으로 추정량의 95% 신뢰구간을 구해보자. 신뢰구간은 추정량의 점근 분포가 정규 분포를 따른다는 사실에 기반해서 구할 수 있다.
ˆβ∼N(β,(XtWX)−1)
## 신뢰구간 alpha = 0.05 for i in range(X_tWX_inv.shape[0]): upper_limit = beta[i] + norm.ppf(1-alpha/2)*np.sqrt(X_tWX_inv[i][i]) lower_limit = beta[i] - norm.ppf(1-alpha/2)*np.sqrt(X_tWX_inv[i][i]) print(df.columns[i], lower_limit, upper_limit)

Social_Status Middel, Social_Status Lower 에 대한 신뢰구간이 0을 포함하므로 통계적으로 유의하지 않다.
이번엔 statsmodels에서 제공하는 Logit을 이용하여 GLM 모형을 적합해보자. 모형 행렬과 반응 변수를 정해주고 Logit 클래스의 fit 메서드를 이용하여 모형을 적합할 수 있다.
X = df[['Age','SS_2','SS_3','Sector_2']] X = sm.add_constant(X) ## 절편항 추가 y = df['Disease_Status'] fit = sm.Logit(y,X).fit()
모형 적합 결과는 summary를 이용하여 볼 수 있다.
fit.summary()
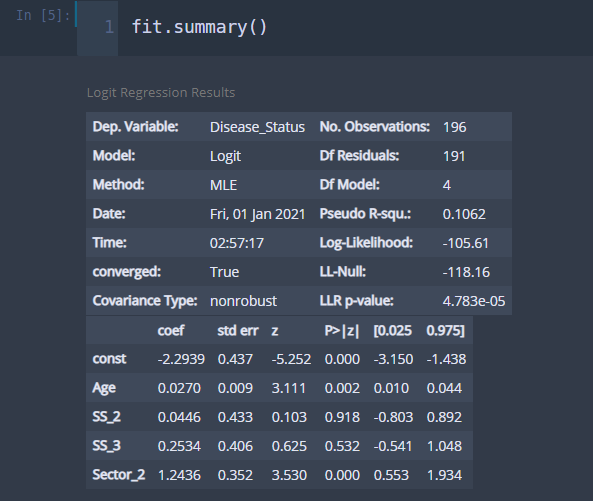
결과가 앞서 직접 구현했던 것과 동일하다. Logit을 통한 적합 결과가 더 많은 정보를 제공해주니 Logit을 잘 사용하는 것을 추천한다. Logit 함수를 이용한 모형 적합은 추후 기회가 된다면 자세하게 다루어보려고 한다.
참고자료
Kutner 외 2명 - Applied Linear Regression Models
Alen Agresti - Foundations of Linear and Generalized Linear Models






댓글