안녕하세요~ 꽁냥이에요!
이번 포스팅에서는 비모수 방법인 Bootstrapping을 이용한 회귀 추정량을 추론하는 방법에 대해서 알아보려고 합니다.
여기서 다루는 내용은 다음과 같습니다.
1. Bootstrapping을 이용한 회귀 추정량 추론 방법
1. Bootstrapping을 이용한 회귀 추정량 추론 방법
- 언제 사용하는가 -
1) 오차의 분포가 정규분포가 아니라고 판단될 때
최소 제곱 회귀 추정량에 대한 추론은 통계학의 관심 분야 중 하나입니다. 추정량에 대한 신뢰성(또는 불확실성)을 신뢰구간 또는 검정을 통하여 확인하고 싶기 때문이지요. 회귀 추정량의 추론을 수행하기 위하여 일반적으로 오차의 분포를 정규분포로 가정합니다(이에 대한 설명은 추후 포스팅하도록 하겠습니다). 하지만 오차의 정규분포 가정이 의심되는 상황에는 제대로 된 추론을 할 수 없게 됩니다. 이때 Bootstrapping을 이용하면 더 정확한 추론이 가능해질 수 있습니다.
2) 반복 가중 최소 제곱법 또는 Robust 회귀 추정법을 이용하여 회귀 추정량을 구했을 때
또한 반복 가중 최소 제곱법(Iteratively Weighted Least Square) 또는 Robust 회귀 추정량에 대한 추론은 샘플 수가 적다면 정확하지 않다고 알려져 있습니다. 이런 경우에도 Bootstrapping을 이용하여 더 정확한 회귀 추정량의 추론이 가능해집니다.
- 방법 -
Bootstrapping을 이용한 추론 방법을 설명하기전에 세팅을 먼저 해두려고 합니다. 먼저 데이터 $(\tilde{x}_i, y_i), \;\; i=1, \ldots, n$ 이 있다고 합시다. 여기서 $\tilde{x}_i = (1, x_{1i}, \ldots, x_{pi})^t$
입니다. 그리고 $\beta = (\beta_0, \ldots, \beta_p)^t$ 라고 할 때 반응 변수 $y_i$와 설명 변수 $\tilde {x}_i$와의 관계가 $E(y_i) = \tilde{x}^t\beta$ 라고 가정합시다.
이때 회귀 추정량을 $\hat{\beta}$, $B$ 를 Bootstrapping 샘플 개수라고 하겠습니다. 이제 Bootstrapping을 통하여 $B$개의 Bootstrap 회귀 추정량을 만들어 줘야 하며 이 과정은 아래의 2가지 경우에 따라서 달라지게 됩니다.
1) 설명 변수 $\tilde{x}_i$가 고정 상수(fixed constant)인 경우
$\hat{y}_i=\tilde{x}_i^t\hat{\beta}$ 라고 할 때 $e_i = y_i - \hat{y}_i$라고 하겠습니다. 즉, $e_i$는 잔차입니다. 이때 Bootstrapping 추론 방법은 다음과 같습니다.
(1) $\{e_i : i = 1, \ldots, n\}$으로부터 $n$개의 새로운 잔차를 복원추출합니다. 이때 새로 뽑힌 잔차를 $e_i^*$라고 하겠습니다.
(2) 새로운 반응 변수 $y_i^*$를 다음과 같이 정의합니다.
$$y_i^* = \hat{y}_i+e_i^*$$
(3) $y_i^*$와 $\tilde{x}_i$를 이용하여 회귀 추정량 $\hat{\beta}_b^*$를 구합니다(설명 변수 $\tilde{x}_i$가 고정 상수이기 때문에 매번 같은 값으로 고정합니다).
(4) (1)~(3) 단계를 $B-1$번 추가로 실행합니다.
2) 설명 변수 $\tilde{x}_i$가 랜덤(Random)인 경우
(1) $\{(\tilde{x}_i, y_i) : i = 1, \ldots, n\}$으로부터 $n$개 복원 추출합니다. 이때 새로 뽑힌 데이터를 $(\tilde{x}_i^*, y_i^*)$라고 하겠습니다.
(2) $(\tilde{x}_i^*, y_i^*)$를 이용하여 회귀 추정량 $\hat{\beta}_b^*$을 구합니다.
(3) (1)~(2) 단계를 $B-1$번 추가로 실행합니다.
1) 번 또는 2) 번의 경우에서 계산된 $B$개의 Bootstrap 회귀 추정량 $\{\hat{\beta}_b^* : b = 1, \ldots, B\}$이 있습니다.
이제 $\beta$에 대한 $1-\alpha$ 신뢰 구간을 구해보겠습니다. 설명의 편의를 위해 여기서는 $p=1$인 경우만 다룹니다($p > 1$인 경우는 Eck D.J. 2017을 참고하세요).
$$\hat{\beta}_1 - d_2 \leq \beta_1 \leq \hat{\beta}_1 + d_1$$
여기서 $d_1 = \hat{\beta}_1 - \hat{\beta}^*(\alpha/2)$, $d_2 = \hat{\beta}^*(1-\alpha/2) \hat{\beta}_1$, $\hat{\beta}^*(q)$는 $\{\hat{\beta}_b^* : b = 1, \ldots, B\}$에서 $q\cdot100$ 분위수입니다.
- 장단점 -
1) 장점
오차의 분포를 가정하지 않으므로 정규성에 위배되는지 아닌지 걱정할 필요가 없으며 모수를 이용한 모델링을 하는 모든 분야에서 추정량을 추론할 때 사용할 수 있다는 점에서 굉장히 유연한 추론 방법입니다. 구현 과정 또한 쉽습니다.
2) 단점
정확한 신뢰구간을 구하기 위하여 많은 Bootstrap 샘플 수(최소 500 이상)가 필요한데 이 경우 계산량이 많아질 수 있습니다. 비모수 방법이 모두 그러하듯이 오차의 실제 분포가 정규분포라면 Bootstrapping을 이용한 신뢰구간보다 $t$ 분포를 이용한 신뢰구간을 더 선호하게 됩니다. 또한 이상치가 많은 데이터의 경우 Bootstrapping을 이용한 신뢰구간의 정확성이 떨어지게 됩니다.
2. 실제 데이터 적용 with Python
1) 설명 변수 $\tilde{x}_i$가 고정 상수(fixed constant)인 경우
먼저 데이터를 다운받아주세요.
이 데이터는 Toluca라는 회사에서 생산하는 장비의 사이즈 별로 작업 시간이 얼마나 걸리는지 알아보기 위해 수집된 데이터라고 합니다.
필요한 모듈을 임포트하고 데이터를 불러옵니다.
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
import numpy as np
import random
from random import choices
df = pd.read_csv('./toluca_company_dataset.csv')

정해진 Lot_size에 대해서만 작업시간을 추정한다고 볼 수 있으므로 Lot_size를 고정 상수로 취급할 수 있습니다. 따라서 1)에 해당하는 Bootstrapping 추론 방법을 사용합니다. 다음은 Bootstrapping을 이용한 회귀 추정량의 95% 신뢰 구간을 구하는 코드입니다.
random.seed(1)
num_data = len(df) ## 데이터 개수
num_bootstrap_sample = 500 ## Bootstrap 샘플 수
alpha = 0.05 ## 유의수준
y = df['Work_hours']
X = df['Lot_size']
X = sm.add_constant(X)
fit = sm.OLS(y,X).fit() ## 최소 제곱 회귀 모형 적합
beta1 = fit.params.Lot_size ## 기울기
fitted_values = fit.fittedvalues ## 적합값
origin_residual = fit.resid ## 잔차
b_est_slope = []
for i in range(num_bootstrap_sample):
b_residual = choices(origin_residual,k=num_data) ## bootstrap sample of residual
y = fitted_values + b_residual
b_fit = sm.OLS(y,X).fit()
b_est_slope.append(b_fit.params.Lot_size)
## bootstrap 신뢰 구간
d1 = beta1-np.percentile(b_est_slope,alpha/2*100)
d2 = np.percentile(b_est_slope,(1-alpha/2)*100)-beta1
lower_bound = beta1-d2
upper_bound = beta1+d1
line 12~15
먼저 최소 제곱 회귀 모형을 적합해줍니다(line 12). 기울기 추정량을 beta1에 담았습니다(line 13). 그리고 적합값 $\hat{y}_i$와 잔차 $e_i$를 구해야 합니다. 이는 각각 fittedvalues, resid 필드에 저장되어 있습니다(line 14~15).
line 16~21
위에서 구한 적합값과 잔차를 이용하여 Bootstrapping 샘플을 구합니다. 먼저 위에서 구한 잔차의 집합에서 복원 추출하고(line 18) 위에서 구한 적합값과 복원 추출된 잔차를 더해 새로운 반응 변수를 만들어줍니다(line 19). 이 반응 변수와 Lot_size를 이용하여 다시 회귀 모형을 적합합니다(line 20).
line 24~27
앞에서 구한 Bootstrapping 샘플을 이용하여 신뢰구간의 하한과 상한은 계산합니다.
신뢰구간을 구하기 전에 먼저 Bootstrapping 샘플의 분포를 시각화하여 확인해보겠습니다.
## bootstrap 추정량의 분포
fig = plt.figure(figsize=(8,8))
fig.set_facecolor('white')
plt.hist(b_est_slope, edgecolor='k')
plt.show()
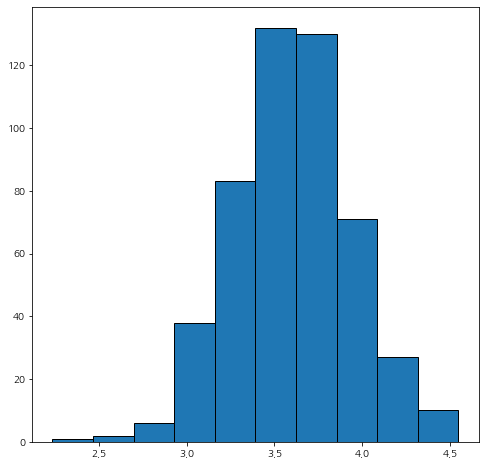
Bootstrapping 샘플의 분포가 평균을 중심으로 대칭을 이루는 것을 알 수 있습니다. 이제 95% 신뢰 구간을 확인해보겠습니다.

신뢰 구간이 0을 포함하지 않으므로 기울기 추정량은 유의미한 것으로 판단할 수 있습니다. 이것이 Bootstrapping을 이용한 추정량의 추론입니다.
2) 설명 변수 $\tilde{x}_i$가 랜덤(Random)인 경우
필요한 데이터를 다운받아주세요.
필요한 모듈을 임포트하고 데이터를 불러옵니다.
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
import numpy as np
import random
from random import choices
## random bootstrapping
df = pd.read_csv('./blood_pressure.csv')

여기서 설명 변수는 연령(Age)이 됩니다. 연령의 경우 관측 때마다 달라지는 변수이므로 연령을 랜덤으로 간주해야 합니다. 따라서 2)에 해당하는 Bootstrapping 추론 방법을 사용합니다.
또한 이전 포스팅에서 이 데이터는 최소 제곱 선형 회귀 모형을 적합하는 경우 오차의 등분산성이 만족되지 않고 그에 따라 가중 최소 제곱 회귀 모형이 더 적합하다는 것을 보였습니다.
random.seed(2)
num_data = len(df) ## 데이터 개수
num_bootstrap_sample = 500 ## bootstrapping 샘플 수
y = df['DBP']
X = df['Age']
X = sm.add_constant(X) ## 1로 이루어진 열을 추가한다.
original_sample = [(row.Age, row.DBP) for _, row in df.iterrows()] ## 절편을 제외한 원 데이터
fit = sm.OLS(y, X).fit() ## 최소 제곱 모형 적합
abs_resid = abs(fit.resid) ## 잔차 절대값
res_fit = sm.OLS(abs_resid,X).fit() ## 잔차 절대값, 설명변수 회귀 모형 적합
weights = 1/res_fit.fittedvalues**2 ## 가중치 계산
fit = sm.WLS(y, X, weights=weights).fit() ## 가중 최소 제곱 모형 적합
w_beta1 = fit.params.Age ## 가중 최소 제곱 기울기 추정량
wb_est_slope = []
for i in range(num_bootstrap_sample):
b_sample = choices(original_sample,k=num_data)
b_df = pd.DataFrame()
b_df['Age'] = [x[0] for x in b_sample]
b_df['DBP'] = [x[1] for x in b_sample]
b_X = b_df['Age']
b_X = sm.add_constant(b_X)
b_y = b_df['DBP']
fit = sm.OLS(b_y,b_X).fit()
abs_resid = abs(fit.resid)
res_fit = sm.OLS(abs_resid, b_X).fit()
weights = 1/res_fit.fittedvalues**2
weight_fit = sm.WLS(y, X, weights=weights).fit()
wb_est_slope.append(weight_fit.params.Age)
# bootstrap 신뢰 구간
d1 = w_beta1-np.percentile(wb_est_slope,alpha/2*100)
d2 = np.percentile(wb_est_slope,(1-alpha/2)*100)-w_beta1
lower_bound = w_beta1-d2
upper_bound = w_beta1+d1
line 3~20
가중 최소 제곱 모형을 적합하고 기울기 추정량을 가져옵니다. 이에 대한 설명은 여기에 자세히 다루었습니다.
line 22~37
가중 최소 제곱 추정량의 Bootstrapping 샘플을 구합니다. 먼저 원 데이터에서 복원 추출합니다(line 24). 복원 추출된 데이터를 이용하여 가중 최소 제곱 모형을 새로 적합하고 기울기 추정량을 구합니다(line 25~37).
line 40~43
기울기 추정량의 Bootstrapping 신뢰 구간을 계산합니다.
Bootstrapping 샘플의 분포를 확인해보겠습니다.
## bootstrap 추정량의 분포
fig = plt.figure(figsize=(8,8))
fig.set_facecolor('white')
plt.hist(wb_est_slope, edgecolor='k')
plt.show()

다음으로 신뢰구간을 확인해보겠습니다.

신뢰구간이 0을 포함하지 않으므로 가중 최소 제곱 기울기 추정량은 유의미한 것으로 판단할 수 있습니다.
이번 포스팅에서는 Bootstrapping을 이용한 회귀 추정량의 추론 방법에 대해서 알아보았습니다. Bootstrapping은 여기서 다룬 회귀 추정량 뿐만 아니라 관심의 대상이 되는 모수에 대해서도 추론할 수 있습니다. 기회가 되면 Bootstrapping 샘플링에 대한 성질과 응용분야에 대해서 포스팅하도록 하겠습니다.
지금까지 꽁냥이의 글 읽어주셔서 감사합니다. 안녕히 계세요.
참고 자료
Kutner 외 2명 - Applied Linear Regression Models 4th edition.
Eck D.J. 2017 - Bootstrapping for Multivariate Linear Regression Models.
'데이터 분석 > 데이터 분석' 카테고리의 다른 글
| [회귀 분석] 10. 가중 최소 제곱법(Weigted Least Square)으로 회귀 모형 적합하기 with Python (5) | 2020.12.04 |
|---|---|
| [회귀 분석] 9. 능형 회귀(Ridge regression) 모형 적합하기 with Python (2) | 2020.12.01 |
| [회귀 분석] 8. 이상치(Outlier), 영향점(Influential Point) 탐지 with Python (0) | 2020.11.02 |
| [회귀 분석] 7. 다중공선성 확인하기 - 분산 팽창 인자 with Python (10) | 2020.10.05 |
| [회귀 분석] 6. 변수 선택법(Variable Selection) with Python (10) | 2020.10.01 |





댓글