안녕하세요~ 꽁냥이에요!
회귀 분석에서 회귀계수 추정량의 분산이 크다면 모형의 신뢰도가 떨어지게 됩니다. 이때 고려해볼 수 있는 것으로 능형 회귀(Ridge regression) 추정법이 있습니다. 능형 회귀 추정법은 회귀 계수 추정량의 편의가 발생하지만 분산을 줄여주는 방법인데요. 특히 변수들 간에 다중공선성이 존재할 경우 능형 회귀 모형을 사용할 수 있지요.
이번 포스팅에서는 능형 회귀 모형을 적합하는 방법과 파이썬(Python)을 이용한 예제를 알아보겠습니다.
1. 능형 회귀(Ridge Regression) 추정법이란?
2. 능형 회귀(Ridge Regression) 모형 적합하기 with Python
1. 능형 회귀(Ridge Regression) 추정법이란?
능형 회귀 추정법은 기존의 오차제곱합에 $L_2$-벌점항(Penalty term)을 추가한 목적함수를 최소화시켜 회귀계수를 추정하는 방법입니다.
데이터 $(\tilde{x}_i, y_i), \:i=1,\cdots,n$ 이 주어졌다고 해볼게요. 여기서 $\tilde{x}_i = (x_{i1}, \cdots, x_{ip})^t$ 입니다(설명변수가 $p$개 있는 것이지요). 능형 회귀 추정법은 아래의 값을 최소화하는 회귀계수를 찾는 방법입니다.
$$\sum_{i=1}^n(y_i-\beta_0-\beta_1x_{i1}-\cdots-\beta_px_{ip})^2+\lambda\sum_{j=1}^p\beta_j^2, \:\:\lambda>0\tag{1}$$
여기서 $\lambda$는 Hyper parameter로써 미리 지정해줘야 하는 값입니다. 이때 절편항 $\beta_0$은 벌점항에 포함되지 않음을 주목해주세요. 이유는 아래에서 설명합니다.
위 식에서 $\lambda=0$인 경우에는 기존의 선형 회귀 모형을 구하는 문제와 같아집니다. 따라서 능형 회귀 모형은 선형 회귀 모형을 더 일반화한 것이라고 생각할 수 있지요.
$\lambda=\infty$인 경우 $\sum_{j=1}^p\beta_j^2=0$이 되어야 하므로(여기서 $\infty\times 0=0$이라고 정의하고 $\sum_{j=1}^p\beta_j^2$이 0보다 크다면 식 (1)은 무한대가 되어 최적화할 수 없게 됩니다) $\beta_1=\cdots=\beta_p=0$이 되고 이때에는 절편항 $\beta_0$만을 가진 회귀 모형을 구하게 됩니다. 이러한 점 때문에 $\beta_0$항은 벌점항에 포함되지 않습니다(만약 포함시킨다면 $\lambda=\infty$인 경우 회귀계수가 오차제곱항의 포함되지 않으므로 식 (1)의 의미가 없어지게 됩니다).
그리고 모든 $j=1, \cdots, p$ 에 대하여 설명변수 $x_j = (x_{1j}, x_{2j}, \cdots, x_{nj})^t$는 Centering 되어 있다고 가정합시다. 이 경우에는 $\lambda$와 관계없이 $\beta_0$의 추정량은 $\bar{y}=\sum_{i=1}^ny_i/n$이 됩니다.
종합하면 절편항 $\beta_0$가 벌점항에 포함되지 않는 점, Centering 된 설명변수에 대하여 $\beta_0$의 추정량은 $\lambda$에 의존하지 않는 점으로 인하여 능형 회귀 추정량을 이야기할 때에는 절편항을 제외하기도 합니다.
지금부터 설명의 편의를 위하여 절편항이 없는 선형 회귀 모형만을 고려하며 아래와 같이 세팅해두겠습니다.
$$E(y) = X\beta \\ Var(y)=\sigma^2 I_n$$
여기서 $\beta = (\beta_1, \beta_2, \cdots, \beta_p)^t$, $X = (x_{ij})_{i=1,j=1}^{n,p}$는 $n\times p$ 행렬, $y=(y_1, \cdots y_n)^y$, $I_n$은 $n\times n$ Identity 행렬입니다. 그리고 $X$는 full-rank라고 하겠습니다.
- 능형 회귀(Ridge Regression) 추정량 -
능형 회귀 추정량은 식 (1)을 $\beta$에 대하여 미분한 후 0으로 놓고 풀면 다음과 같이 얻을 수 있습니다.
$$\hat{\beta}_{\lambda} = (X^tX+\lambda I_p)^{-1}X^ty$$
여기서 $I_p$은 $p\times p$ Identity 행렬입니다.
- 능형 회귀(Ridge Regression) 추정량의 성질 -
$\hat{\beta}_{\lambda}$의 편의(Bias)를 구해보겠습니다.
$$\begin{split}
E(\hat{\beta}_{\lambda}) &=(X^tX+\lambda I_p)^{-1}X^tE(y) \\ &= (X^tX+\lambda I_p)^{-1}X^tX\beta\end{split}$$
따라서 편의는 $E(\hat{\beta}_{\lambda})-\beta = (X^tX+\lambda I_p)^{-1}X^tX\beta - \beta$ 가 되며 이는 0이 아니므로 능형 회귀 추정량은 편의가 있는 추정량(Biased Estimator)가 됩니다.
분산을 구해보겠습니다.
$$\begin{split}
Var(\hat{\beta}_{\lambda})) &= (X^tX+\lambda I_p)^{-1}X^tVar(y)X(X^tX+\lambda I_p)^{-1} \\ &= \sigma^2(X^tX+\lambda I_p)^{-1}X^tX(X^tX+\lambda I_p)^{-1}
\end{split}$$
최소제곱회귀추정량을 $\hat{\beta}_{\text{OLS}}$라 하면 다음과 같은 사실이 알려져 있습니다.
$$Var(\hat{\beta}_{\text{OLS},j}) \geq Var(\hat{\beta}_{\lambda ,j}), \:\:j=1,\cdots, p\tag{2}$$
즉 능형 회귀 추정량의 분산이 최소 제곱 회귀 추정량의 분산보다 작다는 것이지요.
다음으로 평균 제곱 오차(Mean Square Error)를 구해보겠습니다.
$$\begin{split}
MSE(\hat{\beta}_{\lambda}) &= E(\lVert\hat{\beta}_{\lambda}-\beta\rVert_2^2) \\ &= \text{trace}\left(Var(\hat{\beta}_{\lambda})\right) + \lVert E(\hat{\beta}_{\lambda})-\beta \rVert_2^2
\end{split}$$
최소 제곱 회귀 추정량의 평균 제곱 오차를 $MSE(\hat{\beta}_{\text{OLS}})$라 한다면
$$\begin{split}
MSE(\hat{\beta}_{\text{OLS}}) - MSE(\hat{\beta}_{\lambda}) &= \underbrace{\text{trace}\left(Var(\hat{\beta}_{\text{OLS}})-Var(\hat{\beta}_{\lambda})\right)}_{\text{(3)}}-\underbrace{\lVert E(\hat{\beta}_{\lambda})-\beta \rVert_2^2}_{\text{(4)}}
\end{split}$$
식 (2)에 의하여 (3)은 항상 양수입니다. 하지만 (4)가 음수가 되어 전체적으로 평균 제곱 오차의 차이((3) - (4)) 는 양수가 될 수도 있고 음수가 될 수도 있습니다.
- 능형 회귀(Ridge Regression) 추정법을 쓰는 이유 -
일반적으로 평균 제곱 오차가 작은 추정량을 좋은 추정량이라고 합니다. 그런데 앞서 살펴보았듯이 능형 회귀 추정량의 평균 제곱 오차는 최소 제곱 회귀 추정량의 평균 제곱 오차보다 클 수 있지요. 다시 말해 능형 회귀 추정량이 최소 제곱 회귀 추정량보다 안 좋을 수 있다는 것입니다.
그렇다면 능형 회귀 추정량을 쓰는 이유가 무엇일까요? 그것은 바로 능형 회귀 추정량의 평균 제곱 오차를 최소 제곱 회귀 추정량의 평균 제곱 오차보다 더 작게 만드는 $\lambda$를 찾을 수 있기 때문입니다. 이러한 $\lambda$를 찾는다면 능형 회귀 추정량이 더 좋게 되지요(즉, 능형 회귀 추정량이 $\beta$이 편향된 추정량 임을 염두해둔다면 불편추정량인 최소 제곱 회귀 추정량보다 더 좋은 편향된 추정량을 찾을 수 있다고 생각할 수 있습니다).
그리고 이전 포스팅에서 다중공선성이 존재하는 경우 최소제곱회귀추정량의 분산이 커질 수 있다고 했는데요. 능형 회귀 추정량의 분산은 더 작으므로 능형 회귀가 다중공선성이 존재할 때 대체 가능한 회귀 모형이라고 할 수 있습니다.
- $\lambda$는 어떻게 찾을까? -
1. 교차검증을 이용하는 방법
$\lambda$의 범위를 설정한 후 Leave-one-out 교차 검증(Cross Validation)을 이용합니다. 구체적으로 살펴볼게요. 먼저 $\lambda$가 가질 수 있는 값을 $\lambda_1, \lambda_2, \cdots, \lambda_K$라 하면 각 $\lambda_k\;(k=1, \cdots, K)$에 대하여 다음의 평균 예측 오차 $MSE_{\lambda_k}$를 구합니다.
$$MSE_{\lambda_k} = \frac{1}{n}\sum_{i=1}^n(y_i-\hat{y}_{-i}^{\lambda_k})^2$$
여기서 $\hat{y}_{-i}^{\lambda_k}$은 $\lambda_k$에 대하여 $i$번째 데이터를 제외한 능형 회귀 모형을 적합한 값입니다. 그리고 평균 예측 오차를 최소화하는 $\hat{\lambda}$을 찾습니다.
$$\DeclareMathOperator*{\argmin}{argmin} \hat{\lambda}=\argmin\limits_{\lambda_1,\cdots,\lambda_K}MSE_{\lambda_k}$$
참고로 $MSE_{\lambda_k}$는 다음과 같이 쓸 수 있습니다.
$$MSE_{\lambda_k} = \frac{1}{n}\sum_{i=1}^n\left[\frac{y_i-\hat{y}_i^{\lambda_k}}{1-S_{ii}}\right]^2$$
여기서 $\hat{y}_i^{\lambda_k}=\tilde{x}_i^t(X^tX+\lambda_k I_p)^{-1}X^ty$, $S_{ii}$는 $S=X(X^tX+\lambda_k)^{-1}X^t$의 $i$번째 대각 원소입니다. 즉, 위의 식은 $n$번의 적합 없이 단 한방에 $MSE_{\lambda_k}$를 구할 수 있음을 의미하며 계산량을 줄여주는 역할을 합니다.
이제 남은 것은 $\lambda$의 범위는 정해야 하는데요. 최적의 $\lambda$는 주어진 데이터에 따라서 달라지기 때문에 $\lambda$의 범위는 이론적으로 정해진 규칙이나 경험적인 가이드라인이 없습니다. 처음에 넉넉하게 넓은 범위 예를 들면 0~10,000으로 잡아서 $\lambda$ vs $MSE_{\lambda}$ 그래프를 그려보고 최소값이 0~20 구간에 존재할 것으로 판단되면 다시 범위를 0~20으로 줄여나가는 방식으로 찾아야 합니다(일종의 노가다인 셈이죠 ㅠ.ㅠ).
2. Ridge Trace와 분산 팽창 인자(Variance Inflation Factor)를 이용하는 방법
최적 $\lambda$를 선택하는 방법에는 Ridge Trace와 분산 팽창 인자를 동시에 이용하는 방법이 있습니다. Ridge Trace는 $\lambda$값에 대한 능형 회귀 추정량 $\hat{\beta}_{\lambda}$의 그래프를 말합니다. 분산 팽창 인자에 대한 설명은 여기를 참고하세요. 설명변수 간 다중공선성이 존재하고 이에 따라 능형 회귀 모형을 사용하는 경우에 Ridge Trace와 분산 팽창 인자를 사용하여 최적 $\lambda$를 구합니다.
최적 $\lambda$는 다음의 두 가지를 모두 만족하는 가장 작은 값으로 선택합니다.
(1) Ridge Trace를 확인하여 능형 회귀 추정량의 값이 안정적(Stable)인 지점
(2) 분산 팽창 인자가 충분히 작아지는 지점
교차검증을 통한 최적 $\lambda$를 선택하는 것과 마찬가지로 여기서도 분석자의 주관적인 판단이 필요합니다.
- 설명변수는 모두 표준화(Standardization) 해주기 -
일반적으로 설명변수의 단위는 회귀계수 단위에 영향을 미치게 됩니다. 따라서 설명변수 단위에 따라 벌점항에 기여하는 정도가 달라지게 되지요. 즉, 단위에 따라서 특정 변수의 회귀계수가 벌점항에 비정상적으로 크게(또는 작게) 영향을 미칠 수 있습니다. 이러한 문제를 예방하기 위하여 설명변수를 모두 표준화합니다.
- 능형 회귀(Ridge Regression) 추정량의 기하학적 의미 -
식 (1)을 최소화하는 문제는 아래의 제약식이 있는 식을 최소화하는 문제와 같습니다(절편항 제외).
$$\sum_{i=1}^n(y_i-\beta_1x_{i1}-\cdots-\beta_px_{ip})^2, \text{Subject to} \sum_{j=1}^p\beta_j^2<=t, t>0$$
다음은 $p=2$인 경우의 능형 회귀 추정법 원리를 나타낸 것입니다.
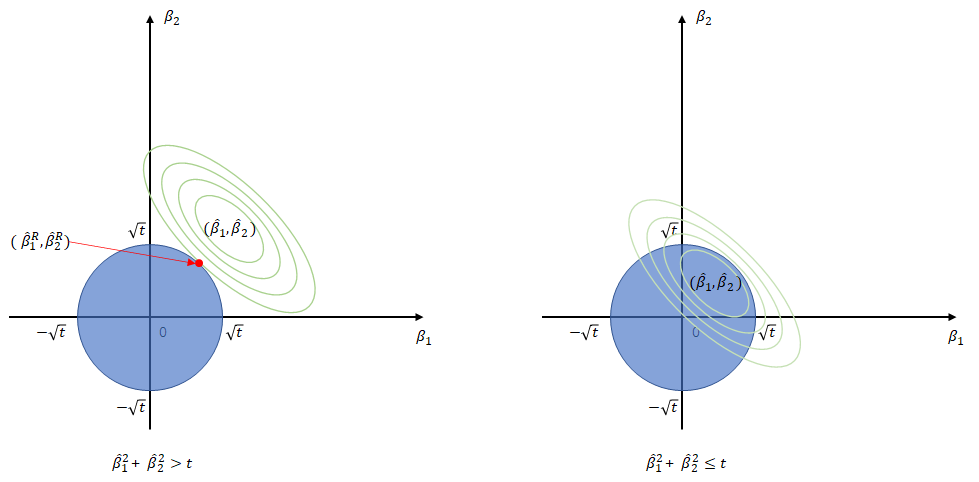
위 그림에서 연두색 등고선은 $f(\beta_1,\beta_2)=\sum_{i=1}^n(y_i-\beta_1x_{i1}-\beta_2x_{i2})^2$의 그래프를 나타낸 것이며 파란색 영역은 양수인 $t$에 대하여 $\{(\beta_1,\beta_2) : \beta_1^2+\beta_2^2\leq t\}$를 나타낸 것입니다. 그리고 $(\hat{\beta}_1, \hat{\beta}_2)$는 최소 제곱 회귀 추정량, $(\hat{\beta}_1^R, \hat{\beta}_2^R)$은 능형 회귀 추정량입니다. 먼저 오른쪽 그림을 보면 최소 제곱 회귀 추정량이 파란색 영역 안에 있는 상황이며 이때에는 능형 회귀 추정량과 최소제곱추정량은 일치하게 됩니다. 왼쪽 그림은 최소제곱회귀추정량이 파란색 영역 밖에 있는 상황이며 이 때에는 연두색 등고선이 파란색원과 접하는 지점의 좌표가 능형 회귀 추정량이 됩니다. 왜냐하면 $f(\beta_1,\beta_2)$ 값은 $(\hat{\beta_1}, \hat{\beta_2})$에서 멀어질수록 커지기 때문입니다.
2. 능형 회귀 모형(Ridge Regression) 적합하기 with Python
이제 실제 데이터를 통하여 능형 회귀 모형을 적합해보도록 하겠습니다. 이번 포스팅에서 사용할 데이터를 다운받아주세요.
이제 필요한 모듈과 데이터를 불러옵시다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.formula.api import ols
df = pd.read_csv('./body_fat_data.csv') ## 데이터 불러오기
반응 변수 Body_fat과 설명변수들을 표준화시켰다고 가정합시다. 그러면 $X^tX$는 설명변수의 3×3 상관계수행렬이 되며 $X^tY$는 반응 변수와 설명변수간의 3×1 상관계수행렬(정확히 말하면 벡터)이 됩니다. 다음은 $X^tX$와 $X^ty$를 구하는 코드입니다.
variables = ['Tricep_ST', 'Thigh_C', 'Midarm_C']
r_xx = df.corr().loc[variables,variables]
r_xx = np.array(r_xx)
r_yx = df.corr().loc['Body_fat',variables]
r_yx = np.array(r_yx)
r_yx = np.expand_dims(r_yx, axis=1)
line 2
pandas.DataFrame 클래스에 내장된 corr를 이용하여 변수간 상관계수행렬을 구할 수 있습니다.
꽁냥이는 $\lambda$값을 Ridge Trace와 분산 팽창 인자를 이용하여 구해보려고 합니다. 다음은 각 $\lambda$값에 따른 회귀계수와 분산팽창인자 그리고 모형의 설명력을 확인하기 위해 결정계수를 구하는 코드입니다.
c = np.array([0, 0.002, 0.004, 0.006, 0.008, 0.01,\ ## 람다값
0.02, 0.03, 0.04, 0.05, 0.1, 0.5, 1])
p = len(variables) ## 변수의 개수
vif_variables = ['VIF_'+v for v in variables]
columns=['c']+variables+vif_variables+['R_squared']
res = pd.DataFrame([],columns=columns) ## 결과를 담을 데이터프레임
for val in c:
inv = np.linalg.inv(r_xx+val*np.identity(p))
ridge_coef = np.matmul(inv,r_yx) ## 능형 회귀 추정량 구하기
row = dict()
row['c'] = val
for j in range(p):
row[variables[j]] = ridge_coef[j][0]
## 분산팽창인자 구하기
vif_mat = np.matmul(np.matmul(inv, r_xx), inv)
for j in range(p):
row[vif_variables[j]] = vif_mat[j][j]
## 결정계수 구하기
fitted_values = []
for i in range(len(sdf)):
fv = np.inner(ridge_coef.flatten(), sdf.iloc[i,:-1])
fitted_values.append(fv)
sse = np.sum(np.square(sdf['Body_fat']-fitted_values))
r_squared = 1-sse
row['R_squared'] = r_squared
res = res.append(row, ignore_index=True)
위 결과를 이용하여 먼저 Ridge Trace를 그려보겠습니다. 다음은 Ridge Trace를 그리는 코드입니다.
## Ridge trace 그리기
fig = plt.figure(figsize=(8,8))
fig.set_facecolor('white')
ax = fig.add_subplot()
for v in variables:
ax.plot(res['c'],res[v],label=v)
plt.axhline(0,color='red')
plt.xlim([0,0.1])
plt.legend()
plt.show()
위 코드를 실행하면 아래와 같이 Ridge Trace를 확인할 수 있습니다. 꽁냥이는 x축의 범위를 0~0.1로 설정했습니다.

$\lambda$ 값이 0.02인 지점부터 능형 회귀 추정량의 값이 변동성이 약한 상태 즉, 안정적인 상태인 것으로 판단됩니다. 이제 분산팽창인자를 확인해봅시다. 아래 코드를 실행해주세요.
res[['c', 'VIF_Tricep_ST', 'VIF_Thigh_C', 'VIF_Midarm_C']]
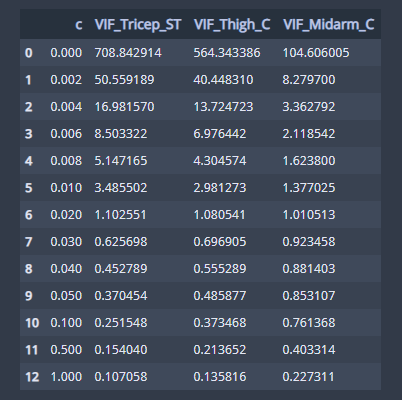
위 그림은 $\lambda$ 값에 따른 분산 팽창 인자입니다. $\lambda$=0.02인 경우 세 변수의 분산 팽창 인자는 각각 1.1026, 1.0801, 1.0105로 이는 $\lambda$=0인 경우(708.8429. 564.3434, 104.6060) 보다 충분히 작으므로 최적 $\lambda$값을 0.02로 정했습니다.
res 변수에 담겨진 값을 확인해 보면 $\lambda$가 0.02인 경우의 능형 회귀 추정량을 확인할 수 있습니다.

표준화된 Body_fat, Tricep_ST, Thigh_C, Midarm_C을 각각 $\hat{Y}^*, X_1^*, X_2^*, X_3^*$라고 하면 능형 회귀 모형은 다음과 같습니다.
$$\hat{Y}^* = .5463X_1^*+.3774X_2^*-.1369X_3^*$$
위 모형은 표준화된 변수들의 모형이며 각 변수의 표준편차와 평균값을 이용하여 다시 원래의 변수로 표현하면 다음과 같습니다.
$$\hat{Y} = -7.3978+.5553X_1+.3681X_2-.1917X_3$$
또한 최소 제곱 회귀 모형의 결정계수는 0.8014이고 능형 회귀 모형의 결정계수는 0.7818로 조금 줄어들었지만 큰 차이는 아니라고 판단됩니다.
이번 포스팅에서 사용한 데이터는 설명변수간 다중공선성이 존재하여 최소 제곱 회귀모형은 적절하지 않았는데요. 따라서 회귀계수의 정확성(작은 분산)이 높다는 점, 최소 제곱 회귀 모형과 (비록 조금 작지만)유사한 설명력을 가진다는 점이 있기에 능형 회귀모형을 최소 제곱 회귀모형의 적절한 대체 모형이라 할 수 있습니다.
이번 포스팅에서는 능형 회귀 추정법이 무엇인지 그리고 실제 데이터를 통하여 능형 회귀 모형을 적합하는 방법에 대해서도 살펴보았습니다. 궁금하신 점은 댓글로 남겨주세요.
지금까지 꽁냥이의 글 읽어주셔서 감사합니다. 안녕히 계세요~
참고자료
Kutner, Nachtsheim, Neter - Applied Linear Regression Models 4ed
Ridge regression - www.statlect.com/fundamentals-of-statistics/ridge-regression
Modern regression - www.stat.cmu.edu/~ryantibs/datamining/lectures/16-modr1.pdf
'데이터 분석 > 데이터 분석' 카테고리의 다른 글
| [회귀 분석] 11. Bootstrapping을 이용한 회귀추정량 추론하기 with Python (0) | 2020.12.16 |
|---|---|
| [회귀 분석] 10. 가중 최소 제곱법(Weigted Least Square)으로 회귀 모형 적합하기 with Python (5) | 2020.12.04 |
| [회귀 분석] 8. 이상치(Outlier), 영향점(Influential Point) 탐지 with Python (0) | 2020.11.02 |
| [회귀 분석] 7. 다중공선성 확인하기 - 분산 팽창 인자 with Python (10) | 2020.10.05 |
| [회귀 분석] 6. 변수 선택법(Variable Selection) with Python (10) | 2020.10.01 |





댓글