이번 포스팅에서는 최소 제곱법에 묻혀서 잘 알려지지 않지만 꽤나 유용한 Least Absolute Regression에 대해서 알아보고자 한다. 여기서 다루는 내용은 다음과 같다.
1. Least Absolute Regression이란?
1. Least Absolute Deviation Regression이란?
- 정의 -
먼저 데이터 (˜xi,yi),i=1,…,n 가 있다고 하자. 여기서 ˜xi=(1,xi1,…,xip)t 이다. 이때 Least Absolute Deivation Regression(LADR)은 아래의 손실 함수 L을 최소화하는 b=(b0,…,bp)t를 찾는 추정법이다.
L=n∑i=1|yi−bt˜xi|
식 (1)에서 yi−bt˜xi를 편차(Deviation)이라고 한다. 다시 말하면 LADR은 편차 절대값의 합을 최소화하는 회귀 추정 방법인 것이다.
- 장단점 -
1. 장점
- LADR은 이상치에 Robust한 추정방법이다.
이는 최소 제곱 추정법과 비교한다면 명확해진다. 이상치는 편차가 다른 데이터에 비하여 굉장히 큰 값이다. 최소 제곱법은 편차를 제곱하기 때문에 같은 이상치에 대해서 LADR 보다 더 큰 손실함수를 갖게 된다. 따라서 최소 제곱법은 이상치의 편차 제곱을 줄이는데 꽤 많은 노력을 기울이게 된다. 이는 일반적인 트렌드를 잡아내지 못하고 이상치에 치우쳐진 모형을 얻게 된다.
반대로 LADR은 이상치가 손실 함수에 기여하는 정도가 최소 제곱법보다 작기 때문에 상대적으로 이상치에 덜 민감한 모형을 얻게 된다.
2. 단점
- 계산이 간단하지 않다.
최소 제곱법은 미분을 통하여 추정량을 비교적 쉽게 구할 수 있는데 반해 LADR은 추정량을 계산하기가 쉽지 않다. 이는 아래에서 다룰 모형 적합 알고리즘을 보면 알 수 있다.
- 추정량이 유일하지 않다.
최소 제곱 추정량이 유일하게 존재하는 상황에도 LADR 추정량은 유일하지 않을 때가 있다. 다시 말하면 편차 절대값의 합을 최소화하는 추정량이 여러 개 있다는 뜻이고 이는 어떤 추정량을 선택해야 하는지에 대한 문제가 추가로 발생하게 된다. 이 경우 검증 데이터(Validation Data)를 이용하여 예측 오차를 최소화하는 추정량을 고르는 것이 하나의 해결방안이 될 수 있다.
2. 모형 적합 알고리즘
1. data points
'data points'란 명칭은 내가 임의적으로 지은 명칭이다. 먼저 간단한 경우로 설명변수가 하나일 때부터 확인해보자.
- 설명 변수가 하나인 경우 -
알고리즘을 소개하기에 앞서 알고리즘의 정당성을 보여주는 핵심 정리를 소개한다. 증명은 아래 첨부파일에서 Theorem 4.3. 과 Lemma 4.2. 를 보면된다.
정리 1.
T={(xi,yi)∈R2|i=1,2,…,n},n≥2 여기서 x1≤x2≤…≤xn이고 x1<xn 라 하자. 이때 L을 최소화하는 최적 LAD 직선은 적어도 두 개 이상의 데이터 포인트를 지난다.
정리 2.
(x0,y0)가 있고 이를 지나는 직선 f(x;a)=a(x−x0)+y0이 있다. 이때
L(a)=n∑i=1|yi−a(xi−x0)−y0|
을 최소화하는 a∗가 존재하며 f(x;a∗)는 적어도 xk≠x0인 하나 이상의 (xk,yk)∈T를 지난다.
정리 1.이 의미하는 바는 LADR 모형은 데이터의 두 점을 지나는 직선 중에서 편차 절대값의 합 L을 최소화하는 직선이라는 것이다.
정리 2.가 의미하는 바는 한 점을 지나는 직선 중에서 L을 최소화하는 기울기를 찾는다면 해당 직선은 반드시 하나 이상의 데이터 포인트를 지난다는 것이다.
그렇다면 당장 떠오르는 알고리즘은 다음과 같을 것이다.
노가다 알고리즘
(1) 데이터에서 임의로 두 개를 선택하여 직선을 만든다.
(2) 선택된 직선에 대하여 편차 절대값의 합 L을 계산한다.
(3) L을 최소화하는 직선을 LADR 모형으로 최종 선택한다.
놀랍게도 이렇게 해서 LADR을 구할 수 있다. 하지만 이 방법은 n개의 데이터 중에서 2개의 데이터를 뽑는 경우의 수 n(n−1)/2만큼의 반복이 필요하다. 이는 데이터가 많아질수록 LADR 모형을 구하는데 걸리는 시간이 늘어난다는 것이다. 따라서 보다 효율적으로 LADR 모형을 구할 수 있는 알고리즘이 필요하다. 이제 주인공을 소개할 시간이다.
two-points 알고리즘
(1) 초기값 (x0,y0)을 설정한다. 데이터의 평균 벡터 (ˉx,ˉy)와 가까운 데이터를 초기값으로 하거나 데이터의 median 벡터 (med(xi),med(yi))과 가까운 데이터를 초기값으로 한다.
(2) f(x;a)=a(x−x0)+y0이라 할 때 L을 최소화하는 a1를 찾는다. 찾는 방법을 알아보자.
(2 - 1) I={i|xi≠x0}라고 하자. 이때 (yi−y0)/(xi−x0),i∈I를 오름차순으로 정렬했을 때의 집합 {(|x′i−x0|,(y′i−y0)/(x′i−x0)):i∈I}을 만들어준다.
(2 - 2) s를 I의 원소 개수라고 하자. 이때 다음의 인덱스 집합을 고려한다. J={j|2j∑i=1|x′i−x0|−s∑i=1|x′i−x0|≤0}
(2 - 3) 만약 J=∅ 라면 a1=(y′1−y0)/(x′1−x0)가 된다. 이때 x1=x′1,y1=y′1로 설정한다. 만약 J≠∅ 인 경우에는 a1=(y′j∗+1−y0)/(x′j∗+1−x0)로 한다. 여기서 j∗는 J의 최대값이다. 이때 x1=x′j∗+1,y1=y′j∗+1로 설정한다.
(2 - 4) G1=∑ni=1|yi−a1(xi−x0)−y0|을 계산한다.
(3) f(x;a)=a(x−x1)+y1이라 할 때 (2)의 방법을 이용하여 L을 최소화하는 a2를 찾는다. 그리고 정리 2.에 의하여 f(x;a2)를 지나는 데이터를 얻을 수 있고 이를 x2,y2라 하자.
G2=∑ni=1|yi−a2(xi−x1)−y1|을 계산한다.
(4) 만약 G2<G1이라면 x1←x2,y1←y2,G1←G2로 설정하고 (3) 단계로 돌아간다. 아니면 종료한다.
위 알고리즘은 유한한 스텝을 거치면 종료하게 된다. 지금까지는 설명 변수가 하나인 경우에 대하여 LADR 모형을 적합하는 방법을 알아보았다. 설명 변수가 여러 개인 경우를 살펴보자.
- 설명 변수가 여러개인 경우 -
설명 변수가 여러개인 경우 Barrodale-Roberts 알고리즘을 기반으로 하여 LADR 모형을 적합한다. 여기서는 n>p+1을 가정한다. 즉, 데이터가 추정해야 할 파라미터 수보다 많아야 한다.
data points 알고리즘
(1) n개 데이터 중에서 임의로 p+1개를 뽑거나 평균 벡터 (ˉx1,…,ˉxp,ˉy)와 가까운 p+1개의 데이터를 뽑아준다. 여기서 ˉxj=∑ixij/n 이다. 해당 데이터 인덱스를 i1,…,ip+1라 하자.
(2) 다음과 같이 A,c를 만들어준다.
A=(˜xi1˜xi2⋮˜xip+1),c=(yi1yi2⋮yip+1)
그리고 b=A−1c라 하자.
(3) A−1의 열벡터를 d1,…,dp+1, zi=yi−bt˜xi라 하자. 그리고 다음의 열벡터 집합 D={±d1,…,±dp+1}을 만들어주자. D는 2(p+1)개의 원소가 있다.
(4) d∈D에 대하여 wi=dt˜xi라 하고 wi≠0에 대하여 W=W−+W0−W+을 계산한다. 여기서 W−는 zi/wi<0인 |wi|들의 합, W0는 zi=0인 |wi|들의 합 그리고 W+는 zi/wi>0인 |wi|들의 합이다. 이때 모든 d에 대하여 W>0이면 알고리즘을 종료하고 b=A−1c를 LADR 추정량으로 한다. 아니라면 W<0인 것 중에서 가장 작게 하는 dk를 찾는다. 이때 k∈{1,2,…,p+1}이다.
(5) zi=yi−bt˜xi, wi=dtk˜xi 그리고 T=∑ni=1|wi|라 하자. wi=0은 제외하고 zi/wi를 오름차순으로 새롭게 정렬하자. 이때 다음을 만족하는 j를 찾는다.
|w1|+|w2|+…+|wj−1|<0.5T|w1|+|w2|+…+|wj−1|+|wj|≥0.5T
(6) wj에 해당하는 ˜xj,yj에 대하여 A의 k 번째 행을 ˜xj, c의 k 번째 원소를 yj로 바꾸어준다.
(7) (3)으로 돌아간다.
위 알고리즘도 유한한 횟수 내로 종료하게 된다. 앞서 얘기했던 LADR의 단점이 기억나는가? LADR의 모형을 적합시키는 과정은 이렇게나 복잡하다.
two point, data point 알고리즘 모두 파라미터의 개수만큼 데이터를 뽑는 것에서부터 시작한다. 그러고 나서 데이터를 하나씩 교체해준다. 여기서 교체할 데이터를 임의로 찾는 것이 아니라.L을 가장 많이 감소시키는 데이터로 교체한다는 것이 이 알고리즘의 핵심이다.
2. subgradient method
편차 절대값의 합 L은 Convex 함수이므로 subgradient ∂L은 항상 존재한다. 따라서 gradient decent method와 같은 알고리즘을 생각할 수 있다.
subgradient method 알고리즘
(1) 스텝 사이즈 α, 최대 반복 횟수 m, tolerance ϵ을 지정하고 초기값 b(0)=(b(0)0,b(0)1,…,b(0)p)을 설정한다.
(2) 스텝 t(1,…,m)에 대하여 파라미터를 다음과 같이 업데이트한다.
b(t+1)=b(t)−α∂L(t)
여기서 ∂L(t)는 b(t)에서 계산된 L의 subgradient이다.
(3) 만약 ‖b(t+1)−b(t)‖2<ϵ이면 종료하고 아니면 (2)로 넘어간다.
subgradient를 이용한 방법은 파라미터를 업데이트를 할 때 반드시 목적함수를 감소시키진 않는다. 따라서 각 스텝마다 L값을 계산해놓고 가장 작은 값에 대응하는 파라미터 b를 최종 LADR의 추정값으로 한다.
이 방법은 수렴 속도가 느리고 local minima에 쉽게 빠지기도 초기값에 따라 파라미터가 업데이트 잘 안되기도 한다. 따라서 이 방법은 LADR 모형을 구할 때 추천하지 않는다. 그냥 쓰지 말자.
3. lterative Reweighted Least Square
이 방법은 MM 알고리즘을 이용한 것이다. 목적 함수인 편차 절대값의 합 L을 최소화하는 문제이므로 Majorize-Minimization 알고리즘이다. MM 알고리즘에 대한 설명은 여기를 참고하자. 여기서는 다음의 부등식을 이용할 것이다.
주어진 x0>0에 대하여
√x≤√x0+x−x02√x0,∀x≥0
MM 알고리즘을 적용하기 위하여 L에 대하여 현재 추정값 b(m)에서의 Majorize 함수를 찾아야 한다. 위 부등식을 이용하면 쉽게 찾을 수 있다.
L=n∑i=1|yi−bt˜xi|=n∑i=1|ri(b)|=n∑i=1√ri(b)2≤n∑i=1{√ri(b(m))2+ri(b)2−ri(b(m))22√ri(b(m))2}:=g(b|b(m))
이제 우리는 L을 최소화하는 문제를 g를 최소화하는 문제로 바꿔 생각한다. 여기서 g의 구조를 살펴보자.
g(b|b(m))=n∑i=1ri(b)22√ri(b(m))2+const. not depend on b
여기서 분모에 있는 숫자 2는 최소화하는 문제에선 필요 없으므로 생략해보자. 그러면 g를 최소화하는 문제는 다음을 최소화하는 문제와 같아진다.
n∑i=1ri(b)2√ri(b(m))2=n∑i=1wi(b(m))(yi−bt˜xi)
여기서 wi(b(m))=|ri(b(m))|−1이다.
위 식을 보면 뭔가 우리에게 친숙하다. 맞다. 바로 가중 최소 제곱합이다. 즉, MM 알고리즘을 이용하면 LADR 모형을 구하는 문제를 가중 최소 제곱 모형을 구하는 문제가 된다. 따라서 LADR 모형 적합 알고리즘은 다음과 같다.
Iterative Reweighted Least Square 알고리즘
(1) 최대 반복 횟수 m, tolerance ϵ, 초기값 b(0)을 정한다. 마땅한 값이 생각나지 않는다면 최소 제곱 추정량을 써도 좋다. 즉, b(0)=(XtX)−1Xty을 초기값으로 한다. 여기서 X=(xij)n,pi=1,j=1,y=(y1,y2,…,yn)t 이다.
(2) t(=1,…,m)번째 스텝에서 다음과 같이 업데이트한다.
b(m+1)=(XtW(b(m))X)−1XtW(b(m))y
여기서 W(b^{(m)})은 i 번째 대각 원소가 wi(b(m))인 대각 행렬이다.
(3) ‖b(m+1)−b(m)‖2<ϵ이면 종료하고 아니면 (2)로 넘어간다.
언뜻 보면 알고리즘이 잘 동작할 것 같다. 하지만 찝찝한 게 남아있다. 그건 바로 ri(b(m))=0이 되어 가중치 wi(b(m))를 구할 수 없는 문제가 있기 때문이다. 따라서 문제를 조금 바꿔야 한다. 편차 절대값의 합 L을 다음과 같이 L′로 바꾼다.
L′=n∑i=1{(yi−bt˜xi)2+ϵ}1/2
앞에서 말한 부등식을 이용하면 L′의 Majorize 함수를 최대화하는 문제는 다음과 같다는 것을 보일 수 있다.
n∑i=1w∗i(b(m))(yi−bt˜xi)2
여기서 w∗i(b(m))=1/(|ri(b(m))|+ϵ)이다. 따라서 위 알고리즘에서 (2) 단계를 아래와 같이 수정한다.
(2)' t(=1,…,m)번째 스텝에서 다음과 같이 업데이트한다.
b(m+1)=(XtW∗(b(m))X)−1XtW∗(b(m))y
여기서 W∗(b(m))은 i 번째 대각 원소가 w∗i(b(m))인 대각 행렬이다.
이 방법은 비록 L의 근사(approximation) 버전인 L′을 최소화한다고 하더라도 실제 L의 최소값에 근접한다. 하지만 회귀 추정치에 차이가 발생할 수 있다.
4. linear programming
L을 최소화하는 b를 찾는 문제는 Linear programming으로 풀 수 있으며 여러 가지 알고리즘이 있다. 알고리즘을 이야기하기 전에 linear program의 standard form이 무엇인지 알 필요가 있다.
Standard form for Linear Programs
Minimize ctxSubject to atix≤bi,i=1,2,…,m,xj≥0,j=1,2,…,p
여기서 c=(c1,c2,…,cp)t,x=(x1,x2,…,xp)t,ai=(ai1,ai2,…,aip)t이다.
여기서 소개할 알고리즘의 핵심이 되는 다음의 성질을 소개하겠다. 증명은 여기에 들어가서 Proposition 1.을 보면 된다.
성질
L을 최소화하는 문제는 아래의 linear program을 푸는 것과 같다.
Minimize n∑i=1(yi−bt˜xi+2ϵi)Subject to yi≤bt˜xi−ϵi,ϵi≥0i=1,2,…,n
위 성질을 standard form으로 바꿔주면 이를 풀어주는 알고리즘을 통하여 L을 최소화하는 b를 구할 수 있다(LADR 모형을 적합할 수 있다).
위의 linear program은 다음과 같이 standard form으로 바꿀 수 있다.
c=(−n,n∑i=1xi1,…,n∑i=1xip,2,…,2⏟n times)tx=(b0,…,bp,ϵ1,…,ϵn)tai=(b0.…,bp,−ei),i=1,2,…nbi=yi,i=1,2,…,n
여기서 ei는 i 번째 원소만 1이고 나머지는 모두 0인 n차원 벡터이다. 나는 파이썬 scipy를 이용하여 위의 standard linear program을 푸는 방법을 아래에서 소개할 것이다.
3. 통계적 검정
ˆb=(ˆb0,…,ˆbp)t을 L을 최소화시키는 LAD(Least Absolute Deviation) 추정량이라고 하자. 통계학도라면 귀무가설 bj=0,j=0,…,p+1을 검정하고 싶을 것이다(그래야 한다). 검정 방법을 알아보자.
m=n−(p+1)이라고 하자. m은 0이 아닌 잔차의 개수이다. LADR 모형이 p+1개의 데이터로부터 만들어졌다는 것을 상기하면 반드시 p+1개 이상의 값이 0인 잔차가 생기게 된다. 이제 0이 아닌 잔차 ei=yi−ˆbt˜xi를 다음과 같이 절대값을 오름차순으로 정리하자.
e(1)≤e(2)≤⋯≤e(n)
이때 k1을 (m+1)/2−√m에 가장 가까운 정수, k2를 (m+1)/2+√m에 가장 가까운 정수라고 하자. 이제 다음을 계산한다.
ˆτ=√m(e(k2)−e(k1))4
그리고 ^Cov(ˆb)는 다음과 같이 추정한다.
^Cov(ˆb)=ˆτ(XtX)−1
이제 H0:bj=0을 검정하기 위한 검정 통계량 t를 다음과 같이 정의한다.
t=ˆbj^Cov(ˆb)j
여기서 ^Cov(ˆb)j는 ^Cov(ˆb)의 j번째 대각 원소이다. 위 검정 통계량에 대한 p-value는 다음과 같이 구한다.
P(|T|≥|t|),T∼t(m)
t(m)은 자유도가 m인 t 분포이다. 그리고 bj의 (1−α)% 신뢰구간은 다음과 같이 계산한다.
(ˆbj−tα2^Cov(ˆb)j,ˆbj+tα2^Cov(ˆb)j)
데이터의 개수가 많으면 t는 근사적으로 표준 정규분포를 따른다는 것이 알려져 있으므로 p-value와 신뢰구간을 정규분포를 이용하여 구하면 된다.
4. 모의 실험
먼저 여기서 필요한 모듈을 임포트한다.
import numpy as np np.set_printoptions(suppress=True) import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import statsmodels.api as sm from scipy.optimize import linprog from autograd import grad from scipy.stats import t, norm
두 번째 줄은 numpy가 숫자를 과학적 표시방법이 아닌 그냥 숫자로 표시하도록 하기 위한 것이다.
1. 알고리즘 구현
나는 LADRegression이라는 클래스를 만들 것이다. 그리고 필요한 값을 초기화해준다. 전체 코드는 아래에 첨부해두었다.
class LADRegression: def __init__(self, X, y): ## X should contain a column of ones as first column of X ## X should be a 2-d array if isinstance(X, pd.DataFrame): self.X = X.values elif isinstance(X, pd.Series): self.X = np.expand_dims(X.values, axis=1) else: if len(X.shape) != 2: raise ValueError('X should be a 2-d array') else: self.X = X if isinstance(y, pd.Series): self.y = y.values else: self.y = y self.method = None ## method used self.cost = None ## cost value self.params = None ## lad estimate self.std_error = None ## std_error self.z = None ## test_statistics self.interval = None ## confiden ce inter val self.residual = None ## residual self.p_val = None ## p-value
필요 함수를 정의한다. 이 함수는 오름차순으로 정렬된 배열을 돌면서 원소가 최초로 양수가 나오면 그 직전의 인덱스를 출력한다.
class LADRegression: '''생략''' def get_index_positive(self,x): for i in range(len(x)): if x[i] > 0: return i-1 return False
다음으로 모형 적합 알고리즘을 앞서 소개한 방법에 따라 적합시킬 것이다. 따라서 fit 함수에는 기본적으로 적용시킬 알고리즘을 method 인자에 넣어주어야 한다. 그리고 31~36줄에서 모형 적합이 다 끝나면 잔차와 각종 통계적인 값들을 구하도록 했다.
class LADRegression: '''생략''' def fit(self,round_digit=5,alpha=0.01,max_its=100,initial_params=None, tolerance=1e-5,epsilon = 1e-2,method='data_points', threshold_num_data=20,significance_level = 0.5): ''' round_digit = 0으로 만들기 위한 최소 자리수 alpha = step_size max_its = 최대 반복 횟수 initial_params = 파라미터 초기값 tolerance = 허용 한계치 epsilon = IRLS에서 필요한 값 method = 알고리즘 threshold_num_data = 데이터 임계치 (이 값보다 큰 데이터는 정규분포로 추정, 작으면 t 분포로 추정) significance_level = 유의 수준 ''' self.method = method if method == 'data_points': self._fit_data_points(round_digit) elif method == 'subgradient': self._fit_subgradient(alpha,max_its,initial_params,tolerance) elif method == 'irls': self._fit_irls(initial_params,max_its,epsilon,tolerance) elif method == 'lp': self._fit_lp() else: methods = ['data_points','subgradient','irls','lp'] raise ValueError(f'method should be one of {methods}') if self.params is not None: self._get_residual() self._get_std_error() self._get_interval(threshold_num_data,significance_level) self._get_z() self._get_p_val(threshold_num_data)
이제 각 알고리즘 별로 모형을 적합하는 함수를 만들어야 한다. 먼저 설명 변수가 한 개인 경우에 대하여 모형 적합 함수를 만들었다.
class LADRegression: '''생략''' def _single_fit(self,X,y): x = X[:,X.shape[1]-1] mean_x = np.mean(x) ## Step. 1 find index which has the closest distance to mean distances = np.linalg.norm(x-mean_x) idx = np.where(distances==np.min(distances))[0][0] starting_x = X[idx,X.shape[1]-1] starting_y = y[idx] ## Step. 2 xyslopes = [] for i in range(len(y)): if starting_x == x[i]: ## In this case, cannot calculate slope continue slope = (y[i] - starting_y)/(x[i] - starting_x) xyslopes.append((x[i], y[i], slope)) sorted_xyslopes = sorted(xyslopes, key=lambda x: x[2]) valid_x_set = [x[0] for x in sorted_xyslopes] W = np.sum(abs(valid_x_set-starting_x)) W_zeros = np.array([2*np.sum(abs(valid_x_set[:i+1]-starting_x)) for i in range(len(valid_x_set))]) W_diff = W_zeros - W if (W_diff>0).all(): target_x = sorted_xyslopes[0][0] target_y = sorted_xyslopes[0][1] else: v_0 = self.get_index_positive(W_diff) if W_diff[v_0] <= 0: target_x = sorted_xyslopes[v_0+1][0] target_y = sorted_xyslopes[v_0+1][1] else: raise ValueError('Something impossible happens') slope1 = (target_y-starting_y)/((target_x-starting_x)) if X.shape[1] == 2: intercept1 = -slope1*starting_x+starting_y params = np.array([intercept1,slope1]) elif X.shape[1] == 1: params = np.array([slope1]) G1 = np.sum(abs(y-X.dot(params))) starting_x = target_x starting_y = target_y ## Step. 3 while True: xyslopes = [] for i in range(len(y)): if starting_x == x[i]: ## In this case, cannot calculate slope continue slope = (y[i] - starting_y)/(x[i] - starting_x) xyslopes.append((x[i], y[i], slope)) sorted_xyslopes = sorted(xyslopes, key=lambda x: x[2]) valid_x_set = [x[0] for x in sorted_xyslopes] W = np.sum(abs(valid_x_set-starting_x)) W_zeros = np.array([2*np.sum(abs(valid_x_set[:i+1]-starting_x)) for i in range(len(valid_x_set))]) W_diff = W_zeros - W if (W_diff>0).all(): target_x = sorted_xyslopes[0][0] target_y = sorted_xyslopes[0][1] else: v_0 = self.get_index_positive(W_diff) if W_diff[v_0] <= 0: target_x = sorted_xyslopes[v_0+1][0] target_y = sorted_xyslopes[v_0+1][1] else: raise ValueError('Something impossible happens') slope1 = (target_y-starting_y)/((target_x-starting_x)) if X.shape[1] == 2: intercept1 = -slope1*starting_x+starting_y params = np.array([intercept1,slope1]) elif X.shape[1] == 1: params = np.array([slope1]) G2 = np.sum(abs(y-X.dot(params))) if G2 < G1: G1 = G2 starting_x = target_x starting_y = target_y else: return params break
다음으로 설명 변수가 2개 이상인 경우에 대한 모형 적합 함수를 만들었다. 이때 설명 변수의 개수가 1개인 경우는 앞서 정의한 함수를 사용하도록 했다. 왜 이렇게 했냐면 이미 만들어 놓은 것을 버리기 아까워서였다.
코드 중간중간에 round 함수를 이용하여 z나 w 값을 0으로 만들어 줬다. 왜냐하면 이론적으로 0이 나와야 할 값들이 e-16처럼 정확히 0이 안되기 때문이다. 이는 알고리즘을 무한루프에 빠질 수 있게 한다.
class LADRegression: '''생략''' def _fit_data_points(self,round_digit): if self.X.shape[1] == 2: ## one variable, one intercept self.params = self._single_fit(self.X,self.y) self.cost = self._cost(self.params) elif self.X.shape[1] == 1: raise ValueError('the number of columns should be greater than 1') else: p = self.X.shape[1] mean_x = np.mean(self.X,axis=0) ## Step. 1 find index which has the closest distance to mean distances = np.linalg.norm(self.X-mean_x,axis=1) idx = np.argpartition(distances, p) idx = idx[:p] # idx = [0,1,2,3] ## Step. 2 find best stepsize and direction A = self.X[idx] c = self.y[idx] while True: A_inv = np.linalg.inv(A) b = A_inv.dot(c) res = [] for j in range(A_inv.shape[1]): ## calculate derivative give d d = A_inv[:,j] W_minus = 0 W_zero = 0 W_plus = 0 for i in range(self.X.shape[0]): z = self.y[i] - b.dot(self.X[i]) w = d.dot(self.X[i]) w = round(w,round_digit) if w==0: pass else: if z/w < 0: W_minus += abs(w) elif round(z,round_digit) == 0: W_zero += abs(w) elif z/w > 0: W_plus += abs(w) derivative_val = W_minus+W_zero-W_plus res.append((j,d,derivative_val)) for j in range(A_inv.shape[1]): d = -A_inv[:,j] W_minus = 0 W_zero = 0 W_plus = 0 for i in range(self.X.shape[0]): z = self.y[i] - b.dot(self.X[i]) w = d.dot(self.X[i]) w = round(w,round_digit) if w==0: pass else: if z/w < 0: W_minus += abs(w) elif round(z,round_digit) == 0: W_zero += abs(w) elif z/w > 0: W_plus += abs(w) derivative_val = W_minus+W_zero-W_plus res.append((j,d,derivative_val)) derivative_vals = np.array([x[2] for x in res]) if min(derivative_vals)>=0: self.params = b self.cost = self._cost(self.params) break else: sorted_res = sorted(res,key=lambda x: x[2]) col_idx, col_vec, _ = sorted_res[0] z = self.y-self.X.dot(b) z = np.array([round(x,round_digit) for x in z]) w = self.X.dot(col_vec) w = np.array([round(x,round_digit) for x in w]) T = np.sum(abs(w)) zwslopes = [] for i in range(len(z)): if w[i] == 0: pass else: slope = z[i]/w[i] zwslopes.append((i,z[i],w[i],slope)) sorted_zwslopes = sorted(zwslopes,key=lambda x:x[3]) valid_w = [s[2] for s in sorted_zwslopes] valid_w = np.array(valid_w) T_zeros = np.array([2*np.sum(abs(valid_w[:i+1])) for i in range(len(valid_w))]) T_diff = T_zeros - T if (T_diff>0).all(): w_idx = 0 else: v_0 = self.get_index_positive(T_diff) if T_diff[v_0] <= 0: w_idx = v_0+1 else: raise ValueError('Something impossible happens') w_val = valid_w[w_idx] new_idx = [s for s in sorted_zwslopes if s[2]==w_val][0][0] A[col_idx] = self.X[new_idx] c[col_idx] = self.y[new_idx]
다음으로 Subgradient method를 이용한 모형 적합 함수를 만들었다. 초기값은 최소 제곱 추정치를 기본값으로 설정했다. 파이썬에는 미분값을 계산해주는 auto_grad라는 고마운 패키지가 있어서 이를 사용했다.
class LADRegression: '''생략''' def _fit_subgradient(self,alpha,max_its,initial_params,tolerance): if initial_params is None: X_tX = self.X.T.dot(self.X) X_tX_inv = np.linalg.inv(X_tX) w = X_tX_inv.dot(X.T.dot(self.y)) else: w = initial_params gradient = grad(self._cost) its = 0 ws = [w] cost_vals = [self._cost(w)] while its < max_its: its += 1 grad_eval = gradient(w) w = w - alpha*grad_eval cost_val = self._cost(w) ws.append(w) cost_vals.append(cost_val) min_cost = min(cost_vals) min_idx = cost_vals.index(min_cost) self.params = ws[min_idx] self.cost = min_cost
이번에는 Iterative Reweighted Least Square를 이용한 모형 적합 함수를 만들었다. 초기값은 최소 제곱 추정치를 기본값으로 설정했다.
class LADRegression: '''생략''' def _fit_irls(self,initial_params,max_its,epsilon,tolerance): if initial_params is None: X_tX = self.X.T.dot(self.X) X_tX_inv = np.linalg.inv(X_tX) w = X_tX_inv.dot(X.T.dot(self.y)) else: w = initial_params train_X = self.X train_y = self.y its = 0 while its < max_its: residual = train_y-train_X.dot(w) weight = 1/np.sqrt(np.square(residual)+epsilon) W = np.diag(weight) X_tWX = train_X.T.dot(W.dot(train_X)) X_tWX_inv = np.linalg.inv(X_tWX) new_w = X_tWX_inv.dot(train_X.T.dot(W.dot(train_y))) if np.linalg.norm(new_w-w) < tolerance: break else: w = new_w self.params = np.squeeze(new_w) self.cost = self._cost(self.params)
마지막으로 Linear Programming을 이용한 모형 적합 함수를 만들었다. scipy에서 제공하는 linprog를 이용하면 쉽게 해를 찾을 수 있다.
class LADRegression: '''생략''' def _fit_lp(self): b = self.y A = self.X ## setting c c = -np.sum(A,axis=0) c = np.hstack((c,2*np.ones(len(b)))) ## setting bounds epsilon_bounds = [] for i in range(A.shape[1]): epsilon_bounds.append((None,None)) for i in range(len(b)): epsilon = np.zeros(len(b)) epsilon[i] = -1 if i == 0: temp = epsilon else: temp = np.vstack((temp, epsilon)) epsilon_bounds.append((0,None)) A = np.hstack((A,temp)) res = linprog(c, A_ub=A, b_ub=b, bounds=epsilon_bounds) self.params = res.x[:self.X.shape[1]] self.cost = self._cost(self.params)
모형 적합 함수를 만들어 주는 일은 끝났고 예측값을 구하는 함수, 각종 통계 값을 구하는 함수, 결과를 요약하는 함수를 만들어 보았다.
class LADRegression: '''생략''' def predict(self,X): prediction = [self._predict(x) for x in X] return prediction def _predict(self,x): return x.dot(self.params) def _cost(self, w): cost = np.sum(np.abs(self.y-self.X.dot(w))) return cost def _get_interval(self,threshold_num_data,significance_level): X = self.X y = self.y params = self.params std_error = self.std_error dof = len(y) - X.shape[1] alpha = 0.5 if X.shape[0] < threshold_num_data: coef = t.ppf(1-alpha/2,dof) else: coef = norm.ppf(1-alpha/2) cis = [] for i, p in enumerate(self.params): ub = p + coef * std_error[i] lb = p - coef * std_error[i] ci = (lb,ub) cis.append(ci) self.interval = cis def _get_std_error(self): X = self.X y = self.y dof = len(y) - X.shape[1] assert dof > 0, 'the degree of freedom must be positive' round_digit = 5 X_tX_inv = np.linalg.inv(X.T.dot(X)) residual = self.residual residual = [round(r,round_digit) for r in residual] ## rounding num_zero = X.shape[1] ## remove p+1 zero from residual vector for r in residual: if num_zero == 0: break if r == 0: residual.remove((r)) num_zero -= 1 residual = sorted(residual) k1 = int(round((dof+1)/2-np.sqrt(dof))) k2 = int(round((dof+1)/2+np.sqrt(dof))) tau = np.sqrt(dof)*(residual[k2]-residual[k1])/4 std_error = np.sqrt(np.diagonal(tau*X_tX_inv)) self.std_error = std_error def _get_z(self): self.z = self.params/self.std_error def _get_residual(self): self.residual = self.y-self.X.dot(self.params) def _get_p_val(self,threshold_num_data): X = self.X y = self.y z = self.z std_error = self.std_error dof = len(y) - X.shape[1] alpha = 0.5 t_dis = False if X.shape[0] < threshold_num_data: t_dis = True if t_dis: self.p_val = 2*(1-t.cdf(abs(z),dof)) else: self.p_val = 2*(1-norm.cdf(abs(z))) def summary(self, prefix='x'): X = self.X params = self.params std = self.std_error z = self.z interval = self.interval p_val = self.p_val method = self.method if method == 'lp': method = 'linear programming' if method == 'irls': method = 'iterative reweighted least square' print(f'{method} method used') texts = ['coef.','est.','std','z','lower','upper','P(Z>|z|)'] string = '' for t in texts: string += f'{t:<8}' print(string) f = lambda x:str(round(x,4)) prefix = 'x' for i in range(X.shape[1]): string = '' texts = [prefix+str(i),f(params[i]),f(std[i]),f(z[i]), f(interval[i][0]),f(interval[i][1]),f(p_val[i])] for t in texts: string += f'{t:<8}' print(string)
2. 모의 실험
간단한 모의실험을 해보았다. 데이터를 난수를 이용하여 생성해주자. 이때 실제 모형을 y=1+2x+ϵ,ϵ∼N(0,1)이라 가정하였다.
np.random.seed(101) n = 19 p = 1 epsilon = np.random.randn(n) true_beta = np.array([1,2]) X = np.squeeze(np.random.rand(n,p)) const = np.ones(n) const = np.expand_dims(const,axis=1) X = np.hstack((const,np.expand_dims(X,axis=1))) y = X.dot(true_beta) + epsilon
이제 각 알고리즘 별로 결과가 어떤지 확인해보자. 이때 최소 제곱 추정량도 구해서 같이 비교해보았다.
methods = ['data_points','subgradient','irls','lp','ols'] max_str = max([len(x) for x in methods]) print('%-*s%-*s%-*s'%(max_str+3,'method',25,'estimates',8,'cost')) for m in methods: lar = LADRegression(X,y) if m == 'subgradient': lar.fit(method=m,initial_params=np.array([2.0,1.5])) params = lar.params cost = lar.cost elif m == 'ols': ## fit least square X_tX_inv = np.linalg.inv(X.T.dot(X)) params = X_tX_inv.dot(X.T.dot(y)) cost = np.sum(np.abs(y-X.dot(params))) else: lar.fit(method=m) params = lar.params cost = lar.cost print('%-*s%-*s%-*s'%(max_str+3,m,25,str(params),8,str(round(cost,4))))
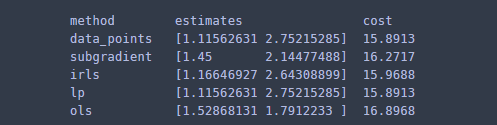
data_points와 linear programming을 이용한 방법은 동일한 결과를 나타낸다. 사실 data_points 알고리즘도 선형 문제를 풀기 위한 것이라고 하니 당연히 같을 수밖에 없다. 다음으로 iterative reweighted least square 방법이 실제 LAD 추정량 값과 가장 가까운 값을 보였고 subgradient method, ols 순으로 추정량이 (cost 측면에서) 안 좋았다.
결과를 시각화하여 실제 직선과 얼마나 차이가 있는지 살펴보았다.
## visualize x = np.linspace(min(X[:,1]),max(X[:,1])) x = np.hstack((np.expand_dims(np.ones(len(x)),axis=1),np.expand_dims(x,axis=1))) fig = plt.figure(figsize=(8,8)) fig.set_facecolor('white') plt.scatter(X[:,1],y) ## distribution plt.plot(x[:,1], x.dot(true_beta),label='True Model',color='k') ## true model methods = ['data_points','subgradient','irls','lp','ols'] line_type = ['-','--','-.',':',(0,(4,2,2,2))] colors = sns.color_palette('hls',len(methods)) for i, m in enumerate(methods): lar = LADRegression(X,y) label = f'LAD via {m}' if m == 'subgradient': lar.fit(method=m,initial_params=np.array([2.0,1.5])) params = lar.params elif m == 'ols': ## fit least square X_tX_inv = np.linalg.inv(X.T.dot(X)) params = X_tX_inv.dot(X.T.dot(y)) label = 'Least Square' else: lar.fit(method=m) params = lar.params plt.plot(x[:,1], x.dot(params), label=label, color=colors[i], linestyle=line_type[i]) plt.title('Fitting Result') plt.legend() plt.show()
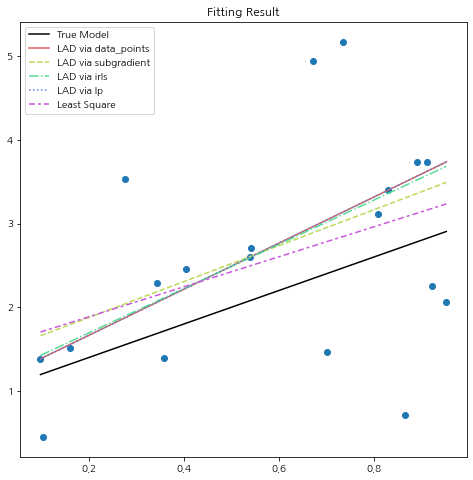
저마다 사정이 있는 직선들이다. LADR의 장점은 이상치에 민감하지 않다는 것인데 여기에서도 그 장점이 눈에 띈다. 최소 제곱 직선은 아래쪽 이상치에 쏠려 있지만 LADR 직선(LAD via data_points, LAD via lp)은 쏠리지 않았다.
5. 실제 데이터 적용
실제 데이터에 적용해보자. 데이터를 다운 받는다.
데이터를 불러온다.
df = pd.read_csv('chicago_information_reduced.csv')
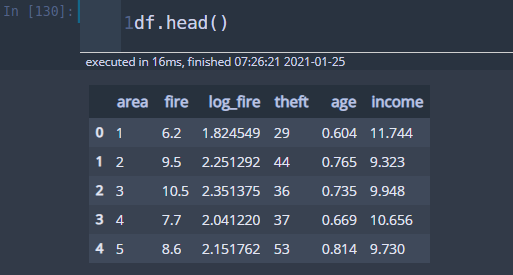
이 데이터는 원래 데이터에서 필요 없는 변수와 이상치 2개(area 7, 24)를 제외한 데이터이다. 모형을 적합해보자.
X = df[['age','theft','income']] y = df['log_fire'].map(lambda x: round(x,3)) X = sm.add_constant(X) ## add a columns of ones X = X.values initial_params = None methods = ['data_points','subgradient','irls','lp','ols'] max_str = max([len(x) for x in methods]) print('%-*s%-*s %-*s'%(max_str+3,'method',25,'estimates',8,'cost')) for m in methods: lar = LADRegression(X,y) if m == 'subgradient': lar.fit(method=m,initial_params=initial_params) params = lar.params cost = lar.cost elif m == 'ols': ## fit least square X_tX_inv = np.linalg.inv(X.T.dot(X)) params = X_tX_inv.dot(X.T.dot(y)) cost = np.sum(np.abs(y-X.dot(params))) else: lar.fit(method=m) params = lar.params cost = lar.cost print('%-*s%-*s %-*s'%(max_str+3,m,25,str(params),8,str(round(cost,4))))

여기서도 IRLS 방법은 LAD 추정량과 cost 측면에서 비슷해 보이지만, age 변수에 대한 회귀 계수 추정치가 많이 다르다. 여기서는 subgradient method와 최소 제곱 추정량과 정확히 일치한다. 왜냐하면 subgradient method는 초기값을 최소 제곱 추정량으로 설정했는데 업데이트가 하나도 되지 않았기 때문이다. 일어나지 않았기 때문이다. subgradient method는 쓰지 말자.
이번엔 LAD 추정량에 대한 통계값을 확인해보자.
## summary lar = LADRegression(X,y) lar.fit() lar.summary()

x3에 해당하는 변수 income이 반응 변수 log(fire)에 가장 유의한 변수로 나타났다. 즉, 소득이 적을수록 화재건수가 증가한다고 볼 수 있다. 나는 이 결과와 최소 제곱 모형으로 적합했을 때의 통계적인 결과를 비교해보고 싶었다.
from statsmodels.api import OLS ols = OLS(y,X).fit() ols.summary()
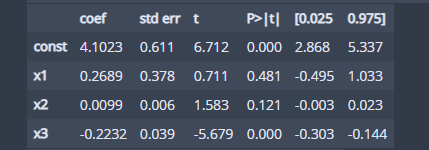
여기서도 역시 income 변수가 유의하게 나왔다. 하지만 추정치는 차이가 났다(심지어 age에 대한 변수는 부호가 달랐다). 또한 신뢰구간에서도 약간의 차이가 났다.
이번 포스팅을 준비하면서 사람들이 왜 최소 제곱 모형을 더 선호하는지 확실히 알았다. LADR은 모형 구현이 굉장히 복잡하다. 따라서 코드도 길어지게 되었다. 하지만 LADR에 대해서 개념적으로만 알았던 것을 직접 구현도 해보고 더 깊게 알게 돼서 좋은 시간이었다.
참고자료
1. David Birkes, Yadolah Dodgea - Alternative Methods of Regression
2. Kristian Sabo, Rudolf Scitovski - The best least absolute deviations line : Properties and two efficient methods for its derivation
4. wiki - Subgradient Method
5. Kenneth Lange - Optimization
6. Han-Lin Li - Solve Least Absolute Value Regression Problems Using Modified Goal Programming Techniques

'통계 > 머신러닝' 카테고리의 다른 글
| [Quantile Regression] 1. A visual introduction to quantile regression (1085) | 2021.04.24 |
|---|---|
| 7. 이상치 탐지(Outlier Detection) - 통계적 검정과 여러가지 판별법 with Python (2) | 2021.02.17 |
| [머신 러닝] 5. EM(Expectation-Maximization) Algorithm(알고리즘)에 대해서 알아보자. (0) | 2021.01.19 |
| [머신 러닝] 4. 나이브 베이즈 분류기(Naive Bayes Classifier) with Python (7) | 2020.12.26 |
| [머신 러닝] 3. 베이즈 분류기(Bayes Classifier) (0) | 2020.12.21 |





댓글