요즘 "Quantile Regression - Theory and Applications"(Cristina Davino 외 2명)를 공부하고 있다. 공부한 내용을 읽고 넘어가기보다 포스팅해두는 것이 좋겠다는 생각이 들었다. 왜냐하면 기억이 오래가기 때문이다 ㅎㅎ. 각 Chapter 별로 포스팅하려고 한다. 내용이 광범위한 것은 포스팅 하나에 1개 Chapter를 소개하려고 하며 필요에 따라선 여러 Chapter를 하나의 포스팅에 정리하려고 한다. 또한 파이썬을 이용하여 예제도 같이 포함시키려고 한다.
이번 포스팅에서는 QR을 소개하는 기본적인 내용을 다루려고 하며 그 내용은 다음과 같다.
2. Quantile Regression 예제 with Python
1. Quantile Regression에 대하여
1) 정의
Koenker와 Basset이 1978년 'Regression Quantiles'라는 논문에서 Quantile Regression(이하 'QR')을 소개하였다. QR은 설명 변수가 주어졌을 때 반응 변수의 조건부 θ 분위수를 모델링하는 기법이다.
2) 기존 회귀와 다른 점
기존 선형 회귀 모형이 반응 변수의 조건부 기대값을 모델링하는 것이었다면 QR은 반응 변수의 조건부 θ-분위수를 모델링한다.
QR 모델이 타겟팅하는 것은 반응 변수의 조건부 분위수라고 했는데 이를 최적화 관점에서 다시 살펴보자. QR은 기본적으로 아래의 식을 최소화하는 설명 변수 X의 함수를 구하는 것과 같다.
argminq(X)E[ρθ(Y−q(X))]
여기서 ρθ=[(1−θI(y≤0)+θI(y>0))]|y|이다.
---- 증명 ----
증명을 해보자. 먼저 (1)을 최소화하는 상수는 무엇인지 알아보자. Y의 확률밀도함수를 f, 누적분포함수를 F, g(c)=E[ρθ(Y−c)]라 하자. 이제 g를 최소화하는 것은 Y의 θ-분위수인 것을 보여야 한다. h(c,y)=(c−y)f(y)라 하자. 여기서 f는 연속함수라 가정하자.
∂g∂c=∂∂c{(1−θ)∫c−∞(c−y)f(y)dy+θ∫∞c(y−c)f(y)dy}=(1−θ){h(c,c)+∫c−∞∂∂ch(c,y)dy}−θ{h(c,c)+∫∞c∂∂ch(c,y)dy}=(1−θ)F(c)−θ(1−F(c))
여기서 두 번째 등식은 라이프니츠 규칙(Leibniz rule)을 쓴 것이다(f를 연속으로 가정한 이유는 이 때문이다). 위 식을 0으로 놓고 정리하면 다음과 같다.
F(c)=θ⇔c=Q(θ)
여기서 Q(θ)는 Y의 θ-분위수이다. 즉, 우리가 보인 것은 g의 Q(θ)에서의 미분값이 0이므로 g를 최소화하는 값은 Q(θ)이다.
이제 식 (1)을 보자. Q_{Y|X}(\theta)를 Y의 조건부 θ-분위수라하면
E[ρθ(Y−f(X))]=EXEY|X[ρθ(Y−f(X))|X]≥EXEY|X[ρθ(Y−QY|X(θ))|X]
여기서 마지막 부등식은 X가 주어진 상황에서는 f(X)가 상수이기 때문에 앞서 살펴본 결과를 적용한 것이다.
----------------
이제 QY|X(θ)(이하 Q)를 다음과 같다고 하자.
QY|X(θ)=b0(θ)+b1(θ)x1+⋯+bp(θ)xp
결국 Quantile Regression은 Q를 설명 변수의 선형 결합으로 가정하고 각 파라미터를 식 (1)을 최소화하는 것으로 추정하는 회귀 분석 방법론인 것이다.
2. Quantile Regression 예제 with Python
여기서는 Cars93 데이터를 이용하여 QR 모형을 적합해보려고 한다. 데이터를 다운받아보자.
먼저 필요한 모듈을 임포트하고 데이터를 불러온다.
import pandas as pd import numpy as np import matplotlib.pyplot as plt import statsmodels.api as sm
car_df = pd.read_csv('../dataset/Cars93.csv')

1. Dummy Regressor
나는 USA 회사와 그렇지 않은 회사 간의 가격차이를 보고 싶었다(왜냐고? 책에서 이렇게 했으니까 ㅎㅎ). 따라서 목적에 맞게 데이터를 전처리해줘야 한다. 필요한 칼럼만 뽑고 'Origin' 칼럼에서 USA인 경우는 0 아닌 경우는 1 값을 갖는 새로운 칼럼을 만들어 주었다. 그리고 절편항을 추가해준다. 그리고 반응 변수와 설명변수를 정해준 뒤 이를 numpy.array로 바꿔줘야 한다. 안 그러면 에러 난다.
car_df = car_df[['Price','Origin','Passengers']] car_df = pd.get_dummies(car_df,columns=['Origin'],drop_first=True) y = car_df['Price'].values X = car_df['Origin_non-USA'] X = sm.add_constant(X) X = X.values
파이썬에서 Quantile Regression은 statsmodels 내의 QuantReg를 이용하여 모형을 적합한다.
처음에 반응 변수와 설명 변수를 QuantReg의 초기 인자로 넣어주고 적합시에는 fit에 q인자에 확인하고자 하는 분위수 값을 넣어준다. 나는 0.11, 0.25, 0.5, 0.75, 0.9 분위수에 해당하는 파라미터를 추정하고 싶었다.
qs = [0.1, 0.25, 0.5, 0.75, 0.9] intercepts = [] slopes = [] for q in qs: qr_reg = sm.QuantReg(y,X).fit(q=q) intercept = round(qr_reg.params[0],4) slope = round(qr_reg.params[1],4) intercepts.append(intercept) slopes.append(slope) print(f'q : {q}, intercept : {intercept}, slope : {slope}')
더미 변수 하나를 설명 변수로 했기 때문에 일종의 그룹 간 분위수 비교가 가능하다. 그룹간 분위수의 차이를 시각적으로 보기 위하여 stem plot을 그려보았다(stem plot을 그리는 방법에 대한 설명은 여기를 참고하기 바란다).
fig = plt.figure(figsize=(8,8)) fig.set_facecolor('white') ax = fig.add_subplot() stems = [] leafs1 = [] leafs2 = [] for i, q in enumerate(qs): stems.append(i) leafs1.append(intercepts[i]) leafs2.append(intercepts[i]+slopes[i]) ax.stem(stems,leafs1,label='USA') ax.stem(stems,leafs2,markerfmt='ro',label='non-USA') ## stemline과 baseline은 안보이게 설정 [x.set_visible(False) for i, x in enumerate(ax.get_children()) if i in [0,1,3,5]] plt.legend() plt.xticks(range(len(qs)),qs) plt.show()
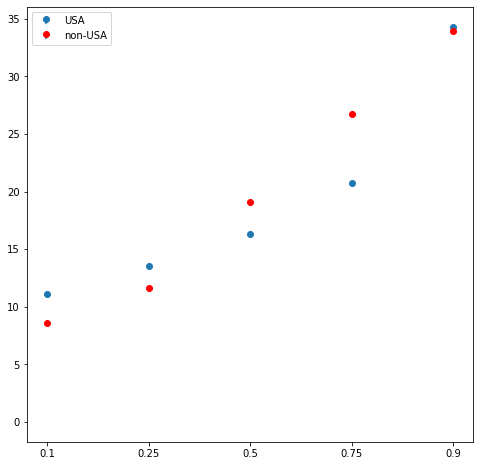
QR의 장점 중 하나는 각 분위수 별로 그룹간 차이를 보여줄 수 있다는 것이다.
2. Quantitative Regressor
이번에는 탑승하는 승객 수에 따른 가격의 변화를 보고 싶었다. 승객 수는 4~6명으로 제한했다. 왜냐하면 나머지 승객 수에 대한 데이터가 10개도 안되었기 때문이다. 여기서는 4분위수에 대한 회귀 계수를 추정해보고자 한다. 여기서는 최소 제곱법을 이용한 회귀 모형도 추가해보았다.
qs = [0.25, 0.5, 0.75] intercepts = [] slopes = [] for q in qs: qr_reg = sm.QuantReg(y,X).fit(q=q) intercept = round(qr_reg.params[0],4) slope = round(qr_reg.params[1],4) intercepts.append(intercept) slopes.append(slope) print(f'q : {q}, intercept : {intercept}, slope : {slope}') ols = sm.OLS(y,X).fit() print(f'OLS - intercept : {ols.params[0]}, slope : {ols.params[1]}')

각 직선을 시각화해보자. 나는 데이터 산포에 각 직선을 겹쳐 그렸다.
fig = plt.figure(figsize=(8,8)) fig.set_facecolor('white') line_x = np.array([4,5,6]) labels = ['1st Quartile', '2nd Quartile', '3rd Quartile'] plt.scatter(car_df['Passengers'],car_df['Price'], color='k', label='Data Points') for i, icpt in enumerate(intercepts): plt.plot(line_x, icpt+slopes[i]*line_x, marker='*', markersize=10, label=labels[i] ) plt.plot(line_x, ols.params[0]+ols.params[1]*line_x, ls='--', color='r', marker='+', markersize=10, label = 'OLS' ) plt.legend() plt.xticks(range(4,len(line_x)+4),line_x) plt.show()
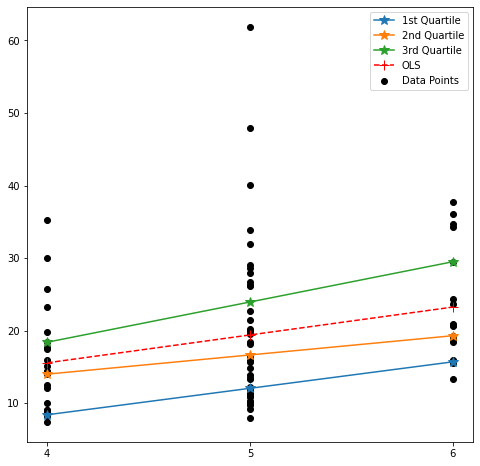
여기서도 기존 OLS 대비 QR의 장점이 여실히 드러난다. OLS는 반응 변수의 조건부 평균 하나만 모델링하는 반면 QR은 분위수 별로 모델링하기 때문에 반응 변수의 변화를 좀 더 다양하게 볼 수 있다는 것이다.

'통계 > 머신러닝' 카테고리의 다른 글
| 8. 연관 규칙 분석(Association Rule Analysis) with Python (1108) | 2021.05.23 |
|---|---|
| [Quantile Regression] 2. Quantile regression : Understanding how and why? (1557) | 2021.05.05 |
| 7. 이상치 탐지(Outlier Detection) - 통계적 검정과 여러가지 판별법 with Python (2) | 2021.02.17 |
| 6. Least Absolute Deviation Regression에 대해서 알아보자 with Python (0) | 2021.01.26 |
| [머신 러닝] 5. EM(Expectation-Maximization) Algorithm(알고리즘)에 대해서 알아보자. (0) | 2021.01.19 |





댓글