One-class SVM(1-SVM)은 정상 데이터 중에서 이상치를 예측할 때 많이 활용되는 모형으로 Scikit-Learn(sklearn)에서는 OneClassSVM 클래스를 이용하여 One-class SVM(1-SVM) 모형을 학습할 수 있다.
이번 포스팅에서는 Scikit-Learn(sklearn)에서 제공하는 OneClassSVM의 기본적인 사용방법을 알아보고자 한다.
One-class SVM(1-SVM)에 대한 개념은 아래 포스팅을 참고하기 바란다.
41. One-class Support Vector Machine(1-SVM)에 대하여 알아보자 with Python
41. One-class Support Vector Machine(1-SVM)에 대하여 알아보자 with Python
이번 포스팅에서는 모델 기반 이상치 탐지 방법론 중에 하나인 One-class Support Vector Machine(1-SVM)에 대해 알아보고자 한다. 여기에서는 One-class Support Vector Machine(1-SVM)의 개념과 파이썬 구현 방법을
zephyrus1111.tistory.com
OneClassSVM 사용법
먼저 예제로 사용할 데이터를 만들어준다.
import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus'] = False
import numpy as np
from sklearn.svm import OneClassSVM as OCS
from sklearn.datasets import make_classification
## 실험용 데이터
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2,
n_redundant=0, n_repeated=0, n_classes=2,
n_clusters_per_class=1,
weights=[0.995, 0.005],
class_sep=0.5, random_state=100)
OneClassSVM은 커널의 종류, $\nu, \gamma$ 값을 지정하여 초기화한다. 그러고 나서 fit 메서드에 학습할 데이터를 넣어주고 학습을 수행한다. 그리고 predict를 이용하면 이상치인지 정상인지 예측할 수 있다.
ocs = OCS(kernel='rbf', ## 커널 {‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’}
nu=0.1, ## Regularization Parameter
gamma = 'auto' ## rbf의 감마
).fit(X)
outlier_labels = ocs.predict(X) ## -1 이상치, 1 정상 예측하기
이제 결과를 시각화해 보자.
fig = plt.figure(figsize=(8, 8))
fig.set_facecolor('white')
ax = fig.add_subplot()
ax.scatter(X[:, 0], X[:, 1], c=outlier_labels)
plt.show()
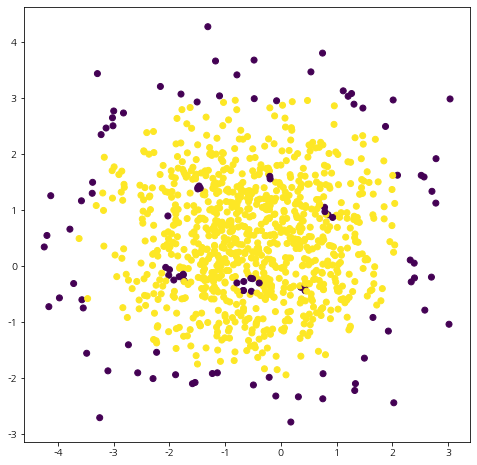
결과가 썩 만족스럽지 않다. OneClassSVM에는 score_examples를 통해 주어진 데이터가 정상인지 아닌지 점수를 매겨준다. 값이 높을수록 정상이며 낮을수록 이상치라고 판단한다. 따라서 예측 결과가 만족스럽지 못할 때에는 score_examples를 통해 얻은 점수를 기반으로 이상치를 재예측할 수 있다.
아래 코드는 하위 5프로의 해당하는 점수를 기준으로 하여 낮으면 이상치 높으면 정상으로 재 예측했다.
## 스코어 기반 이상치 재 예측
score = ocs.score_samples(X)
score_threshold = np.percentile(score, 5) ## 하위 5프로
## 하위 5프로 이하인 경우는 모두 이상치로 예측한다.
new_labels = np.array([-1 if i < score_threshold else 1 for i in score])
시각화 결과를 살펴보자.
fig = plt.figure(figsize=(8, 8))
fig.set_facecolor('white')
ax = fig.add_subplot()
ax.scatter(X[:, 0], X[:, 1], c=new_labels)
plt.show()
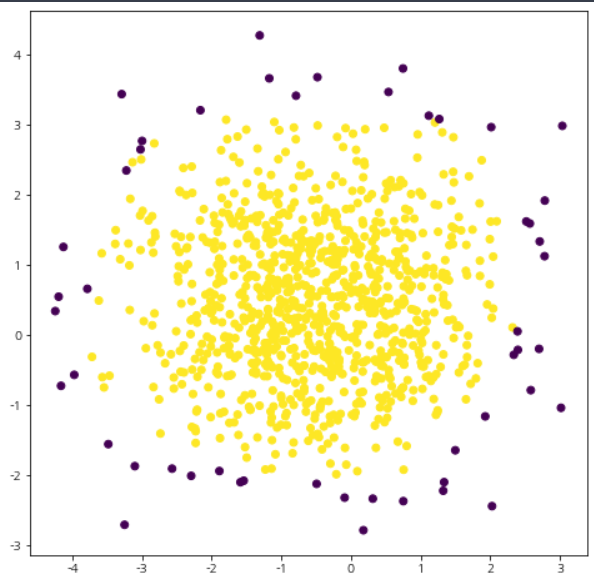
아까보다 훨씬 합리적인 결과를 얻을 수 있다.





댓글