이번 포스팅에서는 Scikit-Learn(sklearn)을 이용하여 정준 상관 분석(Canonical Correlation Analysis)을 수행하는 방법을 알아보려고 한다.
정준 상관 분석(Canonical Correlation Analysis)에 대한 개념은 아래 포스팅을 참고하기 바란다.
39. 정준 상관 분석(Canonical Correlation Analysis)에 대해서 알아보자 with Python
39. 정준 상관 분석(Canonical Correlation Analysis)에 대해서 알아보자 with Python
이번 포스팅에서는 다변량 분석 방법 중 하나인 정준 상관 분석(Canonical Correlation Analysis : CCA)에 대한 개념과 파이썬 구현 방법에 대해서 알아보고자 한다. - 목차 - 1. 정준 상관 분석이란? 2. 분석
zephyrus1111.tistory.com
CCA 사용법
Scikit-Learn(sklearn)에서는 CCA 클래스를 이용하여 정준 상관 분석을 수행할 수 있다. 여기서는 중년 남성들이 어느 헬스클럽에서 측정된 3개의 생리적 변수(몸무게, 허리둘레, 맥박)와 운동량 변수(턱걸이, 윗몸일으키기, 멀리뛰기) 데이터를 사용한다. 데이터는 아래에 첨부해 두었다.
데이터를 불러오고 생리적 변수를 독립 변수 집단, 운동량 변수를 종속 변수 집단으로 설정했다.
import pandas as pd
import numpy as np
from sklearn.cross_decomposition import CCA
df = pd.read_excel('../../machine_learning/cca_data.xlsx')
X = df[['Weight', 'Waist', 'Pulse']].values ## 설명 변수 집단
Y = df[['Chins', 'Situps', 'Jumps']].values ## 종속 변수 집단
CCA 클래스는 n_components를 이용하여 정준 변수의 개수를 설정한다. 그러고 나서 fit 메서드를 이용하여 정준 상관 분석 결과를 얻을 수 있다.
cca = CCA(n_components=3).fit(X, Y)1) 정준 변수
독립 변수 집단의 정준 변수 계수 행렬은 x_weights, 종속 변수 집단의 정준 변수 계수 행렬은 y_weights 속성으로 구할 수 있다.
## 설명 변수 집단의 정준 변수 계수
x_weights =pd.DataFrame(cca.x_weights_,
columns=['v1', 'v2', 'v3'],
index=['Weight', 'Waist', 'Pulse'])
x_weights

## 종속 변수 집단의 정준 변수 계수
y_weights =pd.DataFrame(cca.y_weights_,
columns=['w1', 'w2', 'w3'],
index=['Chins', 'Situps', 'Jumps'])
y_weights

2) 정준 적재 행렬
CCA 클래스의 x_loadings, y_loadings 속성을 이용하여 정준 적재 행렬을 얻을 수 있다.
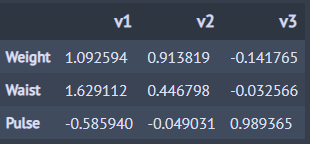
## 독립 변수 집단의 정준 적재 행렬
x_loadings = pd.DataFrame(cca.x_loadings_,
columns=['v1', 'v2', 'v3'],
index=['Weight', 'Waist', 'Pulse'])
x_loadings
## 종속 변수 집단의 정준 적재 행렬
y_loadings = pd.DataFrame(cca.y_loadings_,
columns=['w1', 'w2', 'w3'],
index=['Chins', 'Situps', 'Jumps'])
y_loadings

참고로 정준 교차 적재 행렬은 transform을 이용하여 각 집단별 정준 변수를 구하고 원 변수를 표준화하여 np.corrcoef를 이용하여 계산한다.
## 정준 변수 변환
X_c, Y_c = cca.transform(X, Y)
## 변수 표준화
st_X = (X-np.mean(X, axis=0))/np.std(X, axis=0, ddof=True)
st_Y = (Y-np.mean(Y, axis=0))/np.std(Y, axis=0, ddof=True)
## 종속 변수와 독립 변수 집단의 정준 변수간 정준 교차 적재 행렬
np.corrcoef(st_Y.T, X_c.T)[:3, 3:]
## 독립 변수와 종속 변수 집단의 정준 변수간 정준 교차 적재 행렬
np.corrcoef(st_X.T, Y_c.T)[:3, 3:]




댓글