Scikit-Learn에서 제공하는 GridSearchCV를 이용하여 예측 모형의 파라미터 최적값을 Grid Search 교차 검증으로 찾을 수 있다. 이번 포스팅에서는 GridSearchCV 사용법을 살펴본다.
GridSearchCV 기본 사용법
GridSearchCV 클래스는 기본적으로 예측 모형 클래스(estimator), 최적화할 파라미터와 grid 값을 담고 있는 딕셔너리(param_grid) 그리고 교차 검증시 데이터 분할 개수(cv) 인자를 지정한다. 더 자세한 설명은 여기를 참고하기 바란다.
GridSearchCV( estimator, param_grid, cv)
기본 사용법을 알았으니 예제를 통해 구체적인 사용법을 알아보자.
GridSearchCV 예제
여기서 살펴볼 예제는 서포트벡터머신 회귀모형 SVR과 XGBoost 회귀 모형 그리고 Pipeline이다.
1) SVR
먼저 서포트벡터머신 회귀모형으로 GridSearchCV 예제를 살펴보고자 한다. 데이터는 보스턴 집값 데이터를 이용했다.
아래 코드는 서포트벡터머신 회귀모형에서 최적 커널(kernel)과 최적 C값을 Grid Search & 교차 검증을 통해 찾는 작업을 수행한다. 한 줄 한 줄 살펴보자.
import numpy as np
from sklearn.svm import SVR
from sklearn.datasets import load_boston
from sklearn.model_selection import GridSearchCV, train_test_split
np.random.seed(100) ## GridSearchCV 결과 재생성 시드
## 붓꽃 데이터 로드
boston = load_boston()
## 훈련 데이터와 학습 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(boston.data[:,:5], boston.target, test_size=0.3)
## 모형 클래스 생성
svr = SVR()
## Grid Search 적용 파라미터
kernel_list = ['linear', 'rbf']
C_list = np.arange(1, 3, 0.1)
## parameter 키는 svr.get_params().keys()를 통해 확인
print(svr.get_params().keys())
parameters = {'kernel':kernel_list, 'C':C_list}
## Grid Search 수행
reg = GridSearchCV(svr, parameters, cv=5)
reg.fit(X_train, y_train)
line 7
GridSearchCV는 교차 검증 작업에서 랜덤으로 분할 수 만큼 분할하기 때문에 매 실행 때마다 결과가 달라진다. 따라서 결과를 재생산할 수 있도록 np.random.seed를 정한다. 안타깝게도 GridSearchCV 내부에 이를 위한 인자(예 : random_state)가 없었다.
line 15~19
서포트벡터머신 회귀 모형 클래스 SVR을 생성하고(line 15) Grid Search로 찾을 파라미터와 그에 해당하는 Grid를 리스트로 만들어준다(line 18~19). 여기서는 kernel과 C에 대한 최적값을 찾을 것이다.
line 22
GridSearchCV의 2번째 인자인 파라미터 딕셔너리를 설정해야 한다. 이때 키는 예측 모형 클래스가 갖고 있는 파라미터의 이름에 포함되어야 한다. 이는 get_params().keys()를 이용하여 확인할 수 있다. 그리고 키에 해당하는 값은 해당 키의 Grid를 리스트로 지정한다.
line 25~26
먼저 GridSearchCV 클래스를 생성하고 인자를 넣어준다. 그리고 fit을 통하여 Grid Search & 교차 검증을 수행한다.
코드가 실행되면 결과를 확인해보는 것이 인지 상정이다. 최적 파라미터 값은 best_params_, 최적 성능 지표값은 best_score_를 통해 확인할 수 있다.
## 결과 확인
print('최적 파라미터 값 : ', reg.best_params_)
print('점수 : ', reg.best_score_)

또한 cv_results_를 통해 검증 결과를 확인해 볼 수 있다. 나는 추가적으로 C값에 따른 검증 결과를 시각화해보았다. 설명은 주석으로 대체하며 cv_results_가 제공하는 것이 무엇이 있는지 궁금한 분들은 여기를 참고해보기 바란다.
import matplotlib.pyplot as plt
best_kernel = reg.best_params_['kernel'] ## 최적 커널
## 최적 커널을 갖는 인덱스만 추출
target_idx = [i for i, x in enumerate(reg.cv_results_['params']) if x['kernel']==best_kernel]
## Grid Search에 사용된 C값
target_C = [x['C'] for x in reg.cv_results_['params'] if x['kernel']==best_kernel]
## 교차 검증 스코어
mean_test_score = reg.cv_results_['mean_test_score'][target_idx]
## 최적 커널에 대하여 C에 대한 교차 검증 스코어 값 시각화
fig = plt.figure()
fig.set_facecolor('white')
plt.plot(target_C, mean_test_score)
plt.scatter(reg.best_params_['C'], reg.best_score_, color='red')
plt.title(f'Best Kernel : {best_kernel}')
plt.show()
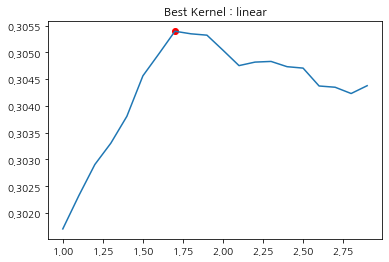
이제 마지막으로 최적 파라미터를 가지고 최종 모형을 만들고 테스트 셋을 이용하여 성능을 평가한다.
final_reg = SVR(C=reg.best_params_['C'],
kernel=reg.best_params_['kernel'])
final_reg.fit(X_train, y_train)
final_reg.score(X_test, y_test)

2) XGBRegressor
xgboost에서 Scikit-Learn 사용자를 위해 개발된 예측 모형 클래스에 대해서도 GridSearchCV를 쓸 수 있다.
아래 코드는 앞에서 본 것과 거의 동일하므로 설명은 주석으로 대체하겠다.
import numpy as np
from xgboost.sklearn import XGBRegressor
from sklearn.datasets import load_boston
from sklearn.model_selection import GridSearchCV, train_test_split
np.random.seed(100) ## GridSearchCV 결과 재생성 시드
## 붓꽃 데이터 로드
boston = load_boston()
## 훈련 데이터와 학습 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(boston.data[:,:5], boston.target, test_size=0.3)
## 모형 클래스 생성
xgb = XGBRegressor()
## Grid Search 적용 파라미터
lambda_list = np.arange(1, 3, 0.1)
gamma_list = [10, 20, 50, 100]
## parameter 키는 xgb.get_params().keys()를 통해 확인
print(xgb.get_params().keys())
parameters = {'reg_lambda':lambda_list, 'gamma':gamma_list}
## Grid Search 수행
reg = GridSearchCV(xgb, parameters, cv=5)
reg.fit(X_train, y_train)
최적 파라미터 값도 확인해보자.
print('최적 파라미터 값 : ', reg.best_params_)
print('점수 : ', reg.best_score_)

마지막으로 최적 파라미터 값을 가지고 최종 모형을 만들고 테스트 셋을 이용하여 성능을 평가한다.
final_reg = XGBRegressor(gamma=reg.best_params_['gamma'],
reg_lambda=reg.best_params_['reg_lambda'])
final_reg.fit(X_train, y_train)
final_reg.score(X_test, y_test)

3) Pipeline
Pipeline에 대해서도 GridSearchCV를 사용할 수 있다. Pipeline에 대한 개념과 사용법은 여기를 참고하기 바란다.
사용법은 거의 동일하나 기존과 차이점은 최적화할 파라미터 이름이 Pipeline에 등록된 작업명과 예측 모형 클래스의 파라미터가 언더바(under bar) 2개로 이루어졌다는 것이다. GridSearchCV 2번째 인자에 들어갈 딕셔너리의 키 형태는 "Pipeline의 작업명 +__+ 모형 클래스의 파라미터" 이라는 것이다.
import numpy as np
from sklearn.pipeline import Pipeline
from sklearn.datasets import load_boston
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVR
np.random.seed(100) ## GridSearchCV 결과 재생성 시드
## 붓꽃 데이터 로드
boston = load_boston()
## 훈련 데이터와 학습 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(boston.data[:,:3], boston.target, test_size=0.3)
## Pipeline 클래스 생성
pipeline = Pipeline([('Scaler', StandardScaler()), ('SVR', SVR())])
## Grid Search 적용 파라미터
C_list = [0.1, 0.5, 1, 2, 5, 10]
## parameter 키는 pipeline.get_params().keys()를 통해 확인
parameters = {'SVR__C':C_list} ## "Pipeline의 작업명 +__+ 모형 클래스의 파라미터"
## Grid Search 수행
reg = GridSearchCV(pipeline, parameters, cv=5)
reg.fit(X_train, y_train)
검증 결과와 최종 모형의 성능 평가도 확인해보자.
print('최적 파라미터 값 : ', reg.best_params_)
print('점수 : ', reg.best_score_)
final_reg = SVR(C=reg.best_params_['SVR__C'])
final_reg.fit(X_train, y_train)
print('최종 모형 성능 : ', final_reg.score(X_test, y_test))






댓글