이번 포스팅에서는 자기 상관 함수(Autocorrelation Function : ACF)와 부분 자기 상관 함수(Partial Autocorrelation Function : PACF)에 대하여 알아보고 파이썬을 이용하여 이를 구하는 방법을 살펴보고자 한다.
1. 자기 상관 함수
- 정의 -
시계열 데이터 $Y_t, Y_{t-1}, \ldots, Y_1$이 있다고 하자. 이때 자기 상관 함수는 다음과 같이 정의된다.
$$\gamma (r, s) = \frac{Cov(Y_r, Y_s)}{\sqrt{Var(Y_r)Var(Y_s)}}\tag{1-1}$$
여기서 $Cov(X, Y) = E(XY) - E(X)E(Y)$, $Var(X) = E(X^2)-E(X)^2$이다. 즉, 각각 공분산과 분산인 것이다. 공부하다 알게 된 것인데 자기 상관 함수를 위와 같이 정의하기도 하지만 아래와 같이 정의하기도 한다.
$$\gamma (r, s) = E(Y_rY_s)\tag{1-2}$$
자기 상관 함수라는 이름에 따라 정의 (1)을 사용하려고 한다.
자기 상관 함수라는 용어를 살펴보자. 함수라는 것은 시점 $r, s$의 함수를 뜻이다. 자기 상관이라는 것은 다른 성질을 갖는 두 확률 변수의 상관계수가 아니고 시간에 따라 변하는 확률 변수 하나로 이루어진 상관계수라는 뜻이다.
시계열 {$Y_t$}가 정상성(Stationary)를 갖는다고 하자. 그러면 정상성 정의에 의하여 자기 상관 함수는 오직 시간 차이에만 의존하게 된다. 따라서 자기 상관 함수는 다음과 같이 쓸 수 있다.
$$\gamma_k = \frac{Cov(Y_{t+k}, Y_t)}{\sqrt{Var(Y_{t+k})Var(Y_t)}}\tag{1-3}$$
정상성 또는 정상 과정의 정의는 여기에 포스팅해두었으니 참고하자~!
여기서는 정상성을 가정한 자기 상관 함수만을 다루려고 한다. 왜냐하면 쉽기 때문이다 ㅋㅋ. 이제 자기 상관 함수가 왜 필요한지 알아보자.
- 추정 -
실제 자기 상관 함수(ACF)는 구할 수 없고 데이터를 이용하여 추정해야 한다. 시계열 관측치 {$y_t$}가 주어졌다고 했을 때 표본 자기 상관 함수(Sample ACF)는 다음과 같이 계산한다.
$$\hat{\gamma}_k = \frac{\sum_{t=k+1}^T(y_t-\bar{y})(y_{t-k}-\bar{y})}{\sum_{t=1}^T(y_t-\bar{y})^2}\tag{1-4}$$
- 필요성-
1) 시계열의 상관성 확인
자기 상관 함수를 이용하면 시계열 데이터의 상관성 여부를 알 수 있다. 즉, 시차 $k$에 대하여 $\gamma_k$의 절대값이 클수록 $k$ 시차 시계열 데이터의 상관성이 크다고 할 수 있다. 그렇다면 어느 정도로 커야 할까?
인터넷 검색을 해보니 이 사이트에서는 다음과 같은 표본 자기 상관 함수의 95% 근사 신뢰구간을 제안하고 있다.
$$-\frac{1}{n}\pm \frac{2}{\sqrt{n}}$$
여기서 $n$은 타임 스텝의 개수이며 각 타임 스텝마다 데이터가 하나인 경우에는 데이터의 개수와 같다.
또한 J. M, Box_steffensmeier 외 2명의 저서 "Time Series Analysis for the Social Sciences"에서는 다음과 같은 신뢰구간을 소개했다.
$$\pm1.96\times \frac{SE_k}{\sqrt{n}}$$
여기서 $SE_k = \sqrt{1+2\sum_{j=1}^k|\hat{\gamma}_j^2|}$이다. 나는 두 번째 신뢰구간을 사용하겠다.
2) ARIMA 모형 식별
자기 상관 함수(ACF)는 ARIMA 모형에서 이동 평균(MA) 항의 차수(order)를 판단하는데 활용된다. 즉, 모형을 식별하는 데 사용된다. 이에 대한 내용은 ARIMA를 포스팅할 때 다루려고 한다.
2. 부분 자기 상관 함수
- 정의 -
부분 자기 상관 함수는 두 가지 정의가 있다. 하나씩 살펴보자.
정의 1
시계열 데이터 $Y_T, Y_{T-1}, \ldots, Y_1$이 있을 때 $Y_t$와 $Y_{t-k}$의 부분 자기 상관 함수(Partial Autocorrelation Function)은 다음과 같이 정의한다.
$$a(1) = Cor(Y_t, Y_{t-1})$$
$$\small a(k) = Cor(Y_t-\beta_0-\beta_1Y_{t-1} - \cdots -\beta_{k-1}Y_{t-k+1}, Y_{t-k}-\alpha_0- \alpha_1Y_{t-k+1} -\cdots \alpha_{k-1}Y_{t-1}), k>1$$
여기서 $\beta_0+\beta_1Y_{t-1}+\cdots+ \beta_{k-1}Y_{t-k+1}$은 평균 제곱 오차(Mean Square Error)를 최소화하는 $Y_t$의 최적 선형 예측자(Best Linear Predictor)이고 $\alpha_0+ \alpha_1Y_{t-k+1} +\cdots+ \alpha_{k-1}Y_{t-1}$은 비슷하게 $Y_{t-k}$의 최적 선형 예측자이다.
이때 $Y_t$가 평균이 0이고 정상 과정이라고 가정하자. 그렇다면 다음이 성립한다.
$$(\beta_0, \beta_1, \ldots, \beta_{k-1})^t = (\alpha_0, \alpha_1, \ldots, \alpha_{k-1})^t$$
왜 그런지 살펴보자. 먼저 $\hat{Y}_t = \beta_0+\beta_1Y_{t-1}+\cdots+ \beta_{k-1}Y_{t-k+1}$라 하자.
$$\begin{align} E[(Y_t-\hat{Y}_t)\cdot 1] &= 0 \\ E[(Y_t - \hat{Y}_t)Y_l] &= 0, l=t-1, t-2, \ldots, t-k+1 \\ E(Y_tY_l) &= E\left (\sum_{j=1}^{k-1}\beta_j Y_{t-j}Y_l \right) \end{align}$$
첫 번째, 두 번째 등식이 성립하는 이유는 다음과 같다. $\hat{Y}_t$이 평균 제곱 오차를 최소화하는 최적 선형 예측자이고 이 경우 $\hat{Y}_t$은 $Y_t$의 $Y_{t-1}, \ldots, Y_{t-k+1}$로 이루어진 공간으로의 정사영(Orthogonal Projection)이 된다. 정사영의 성질 중 어떤 벡터와 그 벡터의 정사영 벡터의 차이는 정사영 공간에 있는 모든 벡터와 수직이라는 것이다. 이러한 성질로 인하여 $<Y_t-\hat{Y}_t, Y_l> = E[(Y_t-\hat{Y}_t)Y_l]=0$이 된다. 이 부분에 대해서 정확하게 이야기하려면 Hilbert Space에서의 내적과 정사영에 대해서 알아야 하는데 여기에서 이 내용은 본 포스팅 주제와는 거리가 있어서 패스하겠다.
세 번째 등식에서 $E(Y_l)=0$ 이므로 $\beta_0$는 사라진다. 첫 번째 등식에 의하여 $\beta_0=0$인 것을 알 수 있다.
$Y_t$가 정상 과정이므로 $Var(Y_t) = \sqrt{Var(Y_{t-j})Var(Y_l)}$이다. $l=t-1, t-2, \ldots, t-k+1$에 대하여 위식 양변에 $Var(Y_t)$을 나누어 줄 것이다.
$$\begin{align} \gamma_1 &= \beta_1\gamma_0 + \beta_2\gamma_1 + \cdots + \beta_{k-1}\gamma_{k-2} \\ &\vdots \\ \gamma_{k-1} &= \beta_1\gamma_{k-2} + \beta_2\gamma_{k-1} + \cdots + \beta_{k-1}\gamma_0\end{align}$$
이를 벡터와 행렬로 표시하면 다음과 같다.
\begin{equation*}
\begin{pmatrix} \gamma_1 \\ \gamma_2 \\ \vdots \\ \gamma_{k-1} \end{pmatrix} =
\begin{pmatrix}
\gamma_0 & \gamma_1 & \cdots & \gamma_{k-2} \\
\gamma_1 & \gamma_0 & \cdots & \gamma_{k-3} \\
\vdots & \vdots & \ddots & \vdots \\
\gamma_{k-2} & \gamma_{k-3} & \cdots & \gamma_0
\end{pmatrix} \begin{pmatrix} \beta_1 \\ \beta_2 \\ \vdots \\ \beta_{k-1} \end{pmatrix}
\tag{2-2}\end{equation*}
마찬가지로 $\hat{Y}_{t-k} = \alpha_1Y_{t-k+1} + \cdots + \alpha_{k-1}Y_{t-1}$에 대해서도 앞에서 살펴본 것과 동일하게 전개하면 $\alpha_0=0$이고 다음과 같이 표현할 수 있다.
\begin{equation*}
\begin{pmatrix} \gamma_1 \\ \gamma_2 \\ \vdots \\ \gamma_{k-1} \end{pmatrix} =
\begin{pmatrix}
\gamma_0 & \gamma_1 & \cdots & \gamma_{k-2} \\
\gamma_1 & \gamma_0 & \cdots & \gamma_{k-3} \\
\vdots & \vdots & \ddots & \vdots \\
\gamma_{k-2} & \gamma_{k-3} & \cdots & \gamma_0
\end{pmatrix} \begin{pmatrix} \alpha_1 \\ \alpha_2 \\ \vdots \\ \alpha_{k-1} \end{pmatrix}
\tag{2-3}\end{equation*}
식 (2-2)과 (2-3)는 정확히 같은 식이며 (역행렬이 존재한다고 가정하는 경우)
$$(\beta_0, \beta_1, \ldots, \beta_{k-1})^t = (\alpha_0, \alpha_1, \ldots, \alpha_{k-1})^t$$
임을 알 수 있다.
따라서 $Y_t$가 평균이 0인 정상 과정이라면 정의 (2-1)을 다음과 같이 쓸 수 있다.
$$\small a(k) = Cor(Y_t -\beta_1Y_{t-1} - \cdots -\beta_{k-1}Y_{t-k+1}, Y_{t-k}-\beta_1Y_{t-k+1} -\cdots \beta_{k-1}Y_{t-1})\tag{2-4}$$
정의 2
부분 자기 상관 함수의 두 번째 정의는 Yule-Walker 방정식을 이용한 정의라고도 한다. 정상성을 만족하고 평균이 0인 시계열 $Y_t$가 있다고 하자. 이때 $Y_{k+1}$의 $Y_1, Y_2, \ldots, Y_k$를 이용하여 평균 제곱 오차를 최소화시키는 최적 선형 예측자(Best Linear Predictor)를 다음과 같이 나타내자.
$$\hat{Y}_{k+1} = \sum_{j=1}^k\phi_{kj}Y_{k+1-j}$$
그러면 다음 식을 만족한다.
$$E[(Y_{k+1}-Y_{k+1-j})Y_l] = 0, j, l=1,2, \ldots, k$$
이를 행렬로 표현하면 다음과 같다.
\begin{equation*}
\begin{pmatrix} \gamma_1 \\ \gamma_2 \\ \vdots \\ \gamma_k \end{pmatrix} =
\begin{pmatrix}
\gamma_0 & \gamma_1 & \cdots & \gamma_{k-1} \\
\gamma_1 & \gamma_0 & \cdots & \gamma_{k-2} \\
\vdots & \vdots & \ddots & \vdots \\
\gamma_{k-1} & \gamma_{k-2} & \cdots & \gamma_0
\end{pmatrix} \begin{pmatrix} \phi_{k1} \\ \phi_{k2} \\ \vdots \\ \phi_{kk} \end{pmatrix}
\tag{2-5}\end{equation*}
이때 $\phi_{kk}$를 부분 자기 상관 함수라 한다.
부분 자기 상관 함수의 두가지 정의를 알아봤는데 특정 조건하에서 두 정의는 서로 일치한다.
- 추정 -
부분 자기 상관 함수는 정의 2를 이용하면 쉽게 구할 수 있다. 식 (2-5)에서 자기 상관 함수를 식 (1-4)의 추정치로 대체한 후 역행렬 계산을 이용하여 구하면 된다.
그리고 부분 자기 상관 함수에 대한 95% 근사 신뢰구간을 다음과 같다.
$$\pm 1.96/\sqrt{n}$$
- 필요성 -
ARIMA 모형 식별
부분 자기 상관 함수는 ARIMA 모형에서 자기 회귀 차수를 식별하는 용도로 사용된다. 이에 대해서는 ARIMA를 다룰 때 소개하도록 하겠다.
3. 예제
이제 파이썬을 이용하여 ACF와 PACF를 계산하고 시각화해보자. 여기서는 직접 구현하는 방법과 statsmodes 모듈을 이용하는 방법에 대해서 소개한다.
1. 데이터
여기서 사용할 데이터는 1981년부터 1990년까지 오스트레일리아 멜버른(Melbourne, Australia)의 온도 데이터를 사용하겠다. 데이터는 아래의 첨부해두었으니 다운받으면 된다.
다음으로 필요한 모듈을 임포트하고 데이터를 불러온다.
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
import numpy as np
df = pd.read_csv('./dataset/daily-min-temperatures.csv')

데이터가 어떤 모양인지 시각화를 간단하게 해 보았다.
fig = plt.figure(figsize=(10,6))
fig.set_facecolor('white')
plt.plot(df['Date'], df['Temp'])
plt.show()

시계열 데이터를 보니 주기가 1년인 특성을 지니고 있다. 이러한 특성을 지닌 데이터는 보통 자기 회귀 모형으로 모델링할 수 있다.
2. ACF, PACF 직접 구현하기
- ACF, PACF 계산 -
파이썬과 넘파이(Numpy), 판다스(Pandas)를 이용하여 ACF와 PACF를 계산하는 함수를 만들어준다. PACF의 경우 시차(lag)가 0인 경우 1로 설정했고 2번째 정의를 이용하여 PACF를 계산한 코드이다.
def acf(series, k):
mean = series.mean()
denominator = np.sum(np.square(series-mean))
numerator = np.sum((series-mean)*(series.shift(k)-mean))
acf_val = numerator/denominator
return acf_val
def pacf(series, k):
if k == 0:
pacf_val = 1
else:
gamma_array = np.array([acf(series, k) for k in range(1,k+1)])
gamma_matrix = []
for i in range(k):
temp = [0]*k
temp[i:] = [acf(series, j) for j in range(k-i)]
gamma_matrix.append(temp)
gamma_matrix = np.array(gamma_matrix)
gamma_matrix = gamma_matrix + gamma_matrix.T - np.diag(gamma_matrix.diagonal())
pacf_val = np.linalg.inv(gamma_matrix).dot(gamma_array)[-1]
return pacf_val
함수를 만들었으니 테스트를 해봐야 할 것이다. ACF와 PACF에 대해서 10차까지 계산해보자. 이때 0차 ACF, PACF는 1로 설정한다.
[acf(df['Temp'],k) for k in range(11)]
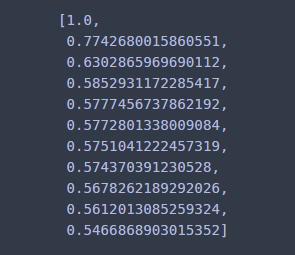
[pacf(df['Temp'],k) for k in range(11)]

- 시각화 -
시차를 x축으로 하고 그에 대응하는 ACF(또는 PACF) 값을 y축으로 그린 것을 correlogram이라 한다. Matplotlib을 이용하여 그려보자. 여기서는 stem 함수를 이용할 것이다. stem 함수는 보통 줄기잎 그릴 때 사용하는데 correlogram을 그릴 때에도 사용할 수 있다. stem 함수에 대한 사용법은 여기에 포스팅해두었으니 참고하면 된다.
먼저 ACF에 대한 correlogram을 그려보자. 이때 95% 근사 신뢰구간도 추가하였다.
nlags = 10
acfs = [acf(df['Temp'],k) for k in range(nlags+1)]
x = range(nlags+1)
fig = plt.figure(figsize=(8,5))
fig.set_facecolor('white')
## correlogram
markers, stemlines, baseline = plt.stem(x, acfs, use_line_collection=True)
markers.set_color('red')
stemlines.set_linestyle('--')
stemlines.set_color('purple')
baseline.set_visible(False) ## base line 안보이게
n = len(df)
upper_limit = []
lower_limit = []
for k in x:
if k == 0:
upper_limit.append(0)
lower_limit.append(0)
else:
term1 = np.sqrt((1+2*np.sum(np.square(acfs[1:k+1])))/n)
upper_limit.append(1.96*term1)
lower_limit.append(-1.96*term1)
plt.fill_between(x, lower_limit, upper_limit, alpha=0.5)
plt.show()
위 코드를 실행해보자~

그림을 살펴보니 ACF가 굉장히 천천히 줄어드는 것을 확인했다. 이는 전형적인 자기 회귀 모형의 특성이다. 다음으로 PACF를 10차까지 그려보았다.
nlags = 10
pacfs = [pacf(df['Temp'],k) for k in range(nlags+1)]
x = range(nlags+1)
fig = plt.figure(figsize=(8,5))
fig.set_facecolor('white')
## correlogram
markers, stemlines, baseline = plt.stem(x, pacfs, use_line_collection=True)
markers.set_color('red')
stemlines.set_linestyle('--')
stemlines.set_color('purple')
baseline.set_visible(False) ## base line 안보이게
n = len(df)
upper_limit = 1.96/np.sqrt(n)
lower_limit = -1.96/np.sqrt(n)
plt.fill_between(x, lower_limit, upper_limit, alpha=0.5)
plt.show()
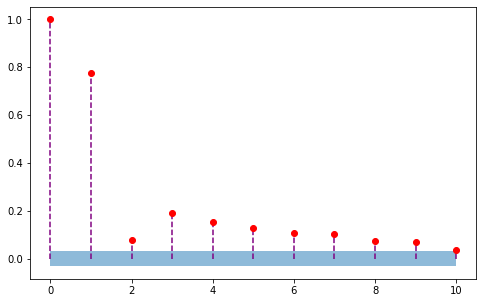
PACF가 2차에서 확 떨어진 것을 알 수 있다. 아마도 이 모형은 2차 자기 회귀 모형으로 모델링할 수 있을 것이다.
3. Statsmodels 이용하기
- ACF, PACF 계산 -
statsmodels는 다양한 통계적 모델을 구축할 수 있도록 도와주는 강력한 파이썬 모듈이다. 먼저 ACF는 다음과 같이 구할 수 있다.
sm.tsa.stattools.acf(df['Temp'], nlags=10, fft=False)

다음으로 PACF 10차까지 계산해보자.
sm.tsa.stattools.pacf(df['Temp'], nlags=10, method='ywm')

- 시각화 -
statsmodels 모듈은 correlogram까지 그려준다. 먼저 ACF에 대한 correlogram은 아래 코드를 통해 그릴 수 있다.
fig = plt.figure(figsize=(8,6))
fig.set_facecolor('white')
ax = fig.add_subplot()
sm.graphics.tsa.plot_acf(df['Temp'], lags=10, ax=ax)
plt.show()

아래 코드는 PACF를 10차까지 그린 것이다.
fig = plt.figure(figsize=(8,6))
fig.set_facecolor('white')
ax = fig.add_subplot()
sm.graphics.tsa.plot_pacf(df['Temp'], lags=10, ax=ax)
plt.show()

이번 포스팅에서는 자기 상관 함수(ACF)와 부분 자기 상관 함수(PACF)에 대해서 알아보았다. 앞서 설명했지만 ACF, PACF는 그 자체로 의미가 있지만 주로 ARIMA(또는 ARMA) 모형을 식별하는 용도로 주로 많이 사용된다. ARIMA(또는 ARMA)를 다룰 때 ACF, PACF가 어떻게 모형을 식별할 수 있는지 알아보겠다.

참고자료
https://machinelearningmastery.com/gentle-introduction-autocorrelation-partial-autocorrelation/
'통계 > 시계열 모형' 카테고리의 다른 글
| [시계열 분석] 7. ARMA 모형에 대해서 알아보자 with Python (803) | 2021.09.18 |
|---|---|
| [시계열 분석] 6. 이동 평균 모형(Moving Average Model) 적합하기 with Python (809) | 2021.08.20 |
| [시계열 분석] 4. 자기 회귀 모형(Autoregressive Model) 적합하기 with Python (1434) | 2021.04.09 |
| [시계열 분석] 3. (General) Durbin-Watson 검정 with Python (1118) | 2021.03.21 |
| [시계열 분석] 2. 최소 제곱법을 이용한 시계열 분석 with Python (1) | 2021.02.24 |





댓글