의사결정나무는 그 자체로 해석이 쉽다는 장점과 모형을 나무 형태로 보여줄 수 있다는 장점 덕분에 많이 사용한다. 하지만 잘못하면 너무 깊은(사이즈가 큰) 나무가 생성되어 모형의 과적합(Overfitting)을 유발할 수 있다. 이때 가지치기(Post Pruning)를 통하여 과적합을 방지하는데 이번 포스팅에서는 이러한 가지치기(Post Pruning)에 대해서 알아보고자 한다. 여기서 다루는 내용은 다음과 같다.
본 포스팅을 읽어보기 전에 의사결정나무에 대한 내용을 이전 포스팅에서 정리해두었으니 먼저 읽어보자. 또한 노드와 마디는 같은 뜻이니 상황에 따라 혼용해서 쓰려고 한다.
1. Cost Complexity Pruning
- 정의 -
먼저 R(T)를 의사결정나무 T의 성능 측도라고 하자. 여기에서 성능 측도는 회귀 나무인 경우 오차 제곱합(Sum of Square Error), 분류 나무인 경우 오분류율로 정의할 수 있다. 만약 의사결정나무의 정확도를 계산할 때 R(T)만을 고려한다면 예측력이 좋지 않을 수 있다. 왜냐하면 R(T)는 일반적으로 사이즈(끝마디 개수)가 큰 나무를 만들어내는 경향이 있고 이는 과적합으로 이어지기 때문이다. 따라서 성능 측도와 의사결정나무 사이즈를 고려한 아래와 같은 새로운 측도를 고려하게 된다.
Rα(T)=R(T)+α|T|
이때 α는 양의 실수, |T|는 나무 T의 끝마디 개수이다. 식 (1)을 비용 복잡도(Cost Complexity)라고 하며 이를 최소화시키는 과정을 Cost Complexity Pruning(CCP)이라 한다. 식 (1)을 잘 보면 R(T)를 최소화할 뿐만 아니라 나무의 크기(사이즈)를 조절한다. 식 (1) 오른쪽 두 번째 항은 일종의 Penalty로써 나무의 크기가 클수록 그 값은 커진다. 따라서 식 (1)을 최소화할 때 나무의 크기가 작은 나무를 더 선호하게 된다.
CCP 방법을 알아보기 전에 사전에 정의해야 할 것이 있다. 먼저 노드 t와 Tt 그리고 T−Tt에 대한 정의를 아래 그림으로 나타내었다.

그리고 아래의 개념도 알아야 한다.
R(t) : 노드 t에 해당하는 데이터(y)의 불순도
R(Tt) : 노드 t를 뿌리로 하는 나무 Tt의 불순도
아래 그림을 통해 R(t1)의 값을 계산해보자. 여기서는 오분류율을 불순도로 한다.
먼저 노드 t1에 해당하는 데이터는 16개이며 이에 대한 오분류율은 8/16인 것을 알 수 있다. 따라서
R(t1)=0.5이다. 그리고 나무 Tt1에 대한 오분류율은 0이다. 왜냐하면 모든 끝마디에서 클래스가 오직 하나이기 때문이다. 다시 말해 정확하게 분리가 되었기 때문에 오분류율이 0인 것이다. 따라서
R(Tt1)=0이다.
이제 α(≥0)와 노드 t가 주어졌다고 해보자. 이때 Rα(t)과 Rα(Tt)을 생각해보자. 이는 각각 노드 t와 Tt의 비용 복잡도이며
Rα(t)=R(t)+αRα(Tt)=R(Tt)+α|Tt|
이다. 첫 번째 식에서 노드 t에서 끝마디는 자기 자신밖에 없으므로 |Tt|=1 이므로 비용 복잡도에서 벌점항은 α가 된다.
일반적으로 R(Tt)<R(t)이다. 왜냐하면 Tt는 t를 더 세분화한 것이기 때문에 불순도 측면에서는 더 작아지기 때문이다. 이때 Rα(Tt)와 Rα(t)을 α에 대하여 그려보면 다음과 같다.
일반적으로 |Tt|>1이므로 α를 점점 크게 하면 위에 그림에서 보는 것처럼 α∗에서 만나게 된다. 간단히 계산해보면 α∗=R(t)−R(Tt)|Tt|−1인 것을 알 수 있다. 이때 Rα(Tt)와 Rα(t)가 같아지게 하는 α∗값 중에서 가장 작은 α∗에 대응하는 노드를 Weakest Link라고 한다. α∗를 기점으로 조금만 증가하면 가지치기를 하는 것이 마치 가지에 조금만 힘을 줘도 끊어진다는 의미에서 Weakest Link라고 이름 붙인 것 같다. CCP는 이러한 Weakest Link를 쳐내면서 가지치기를 수행한다. 이런 의미에서 CCP를 Weakest Link Cut이라고도 한다.
그렇다면 Weakest Link를 쳐낸다는 것이 어떤 의미일까? 그것은 바로 가지가 있을 때와 처낼 때 불순도의 차이가 거의 없는 부분을 가지치기하겠다는 뜻이다. 이제 CCP를 수행하는 방법을 알아보자.
- 방법 -
CCP 알고리즘은 다음과 같다.
1. αi와 Ti 시퀀스 얻기
1) 초기화 단계
α1=0으로 설정하고 α1에 대하여 불순도 R(T)를 최소화하는 의사결정나무 T1을 구한다.
2) 1단계 T1에 있는 모든 중간 노드 t에 대하여
g(t)=R(t)−R(T1t)|T1t|−1
를 최소화하는 노드 t를 찾는다. 이 노드를 t1이라하고 α2=g(t1), T2=T1−T1t1이라 하자.
3) i 단계 Ti에 있는 모든 중간 노드 t에 대하여
g(t)=R(t)−R(Tit)|Tit|−1
를 최소화하는 노드 t를 찾는다. 이 노드를 ti이라하고 αi+1=g(ti), Ti+1=Ti−Titi이라 하자.
이렇게 하면
T1⊃T2⊃⋯⊃{root}와 α1≤α2≤⋯≤αk≤⋯의 시퀀스를 얻을 수 있다.
2. 최적 αi와 Ti 찾기
이것은 검증 데이터 또는 교차검증(Cross Validation)을 이용하여 불순도를 가장 작게 만드는 αi와 Ti을 선택한다.
- 예제 -
이해를 돕기 위한 예제를 살펴보자. 이 예제는 ML Wiki에 잘 정리되어있어서 가져왔다.
1 단계
α1=0으로 세팅하고 의사결정나무 T1를 만들어준다. 여기서는 벌점항이 0이 되므로 일반적으로 의사결정나무를 구하는 것과 같다.
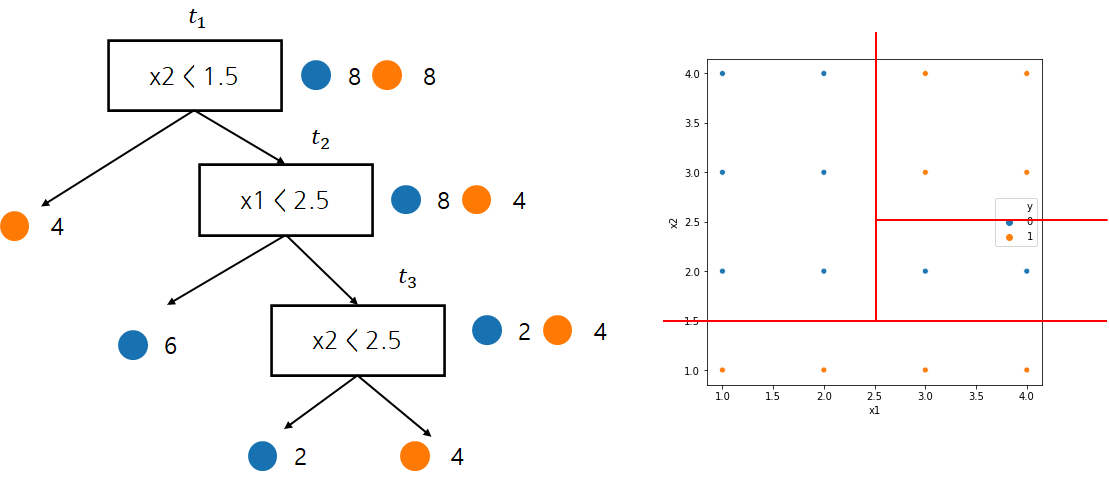
| t | R(t) | R(Tt) | g(t) |
| t1 | 816 | 016=0 | 8/16−04−1=16 |
| t2 | 416 | 016=0 | 4/16−03−1=18 |
| t3 | 216 | 016=0 | 2/16−02−1=18 |
이제 g(t)를 최소화하는 노드(Weakest Link)는 t2, t3가 된다. 이때에는 끝마디의 개수가 적은 t1을 선택하거나 단순한 의사결정나무를 얻고 싶다면 t2를 선택한다(Weakest Link가 2개 이상인 경우 어떤 것을 선택하는지와 그에 따른 성질에 대한 내용을 찾지 못했다). 나는 t2를 선택했다. 그리고 α2=1/8로 세팅하고 t2를 가지치기하고 남은 T1−T1t2을 T2로 설정한다.
2 단계
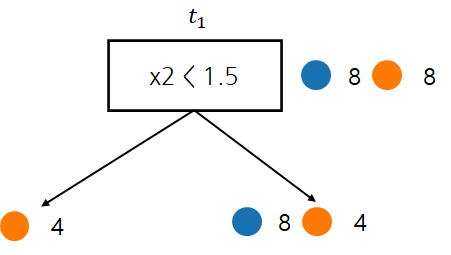
| t | R(t) | R(Tt) | g(t) |
| t1 | 816 | 416 | 8/16−4/162−1=14 |
노드가 하나밖에 없으므로 t1이 Weakest Link가 되며 α3=1/4로 설정하고 T3=T2−T2t1로 설정한다.
이렇게 해서 (α1α2,α3)와 (T1,T2,T3)를 얻게 된다.
3 단계
이제 검증데이터 셋을 준비하여 T1,T2,T3중에서 가장 작은 불순도를 갖게 하는 T∗를 최종 의사결정나무로 선택한다.
- 장단점 -
1. 장점
- 불순도를 최대한 유지하면서 가지치기를 하기 때문에 너무 과하게 가지치기를 하지 않고 그에 따라서 안정적인(Stable) 나무를 얻을 수 있다.
2. 단점
- 알고리즘이 복잡하고 그에 따라 구현하기가 매우 까다롭다.
- 모든 Subtree를 고려하는 것이 아니기 때문에 Local Minima에 빠질 수 있다.
2. Reduced Error Pruning
- 정의 -
Reduced Error Pruning(REP)은 훈련 데이터를 통해 의사결정나무를 만든 뒤 검증 데이터를 이용하여 모든 중간 마디들에 대하여 분리 후 불순도와 분리 전 불순도를 비교해가며 가지치기를 수행하는 방법이다.
- 예제 -
REP가 작동하는 과정을 이해하기 위해 다음과 같은 나무가 만들어졌다고 하자.
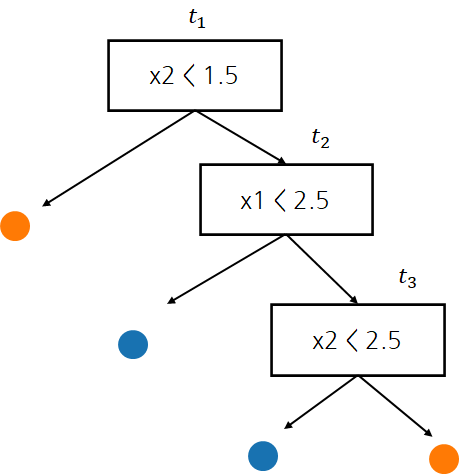
이제 아래와 같은 검증 데이터가 있다고 가정하자.

1 단계
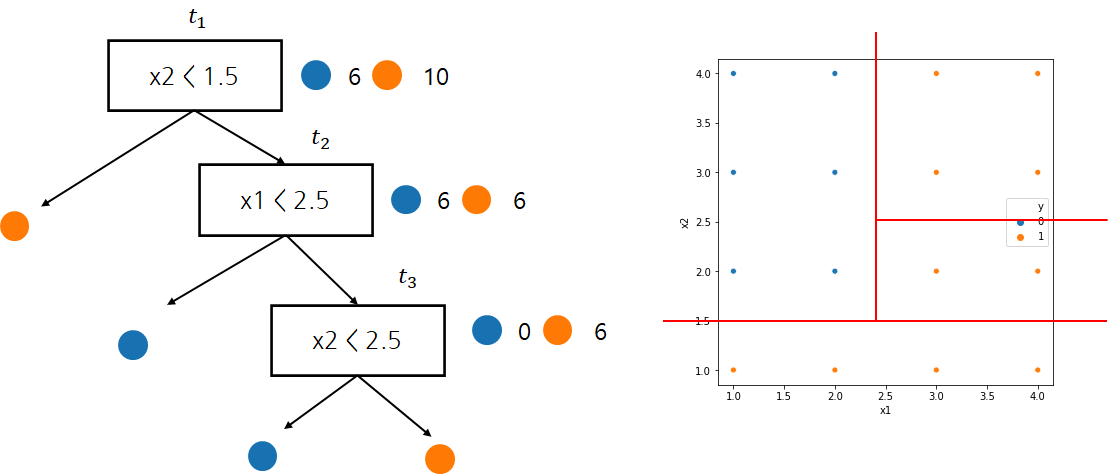
| t | 분리된 후 오분류 개수 | 분리되기 전 오분류개수 | 가지치기 여부 |
| t3 | 2 | 0 | Yes |
먼저 t3이 분리되었을 경우 오분류 개수(오분류 개수 말고 다른 불순도를 측도로 사용할 수 있다)는 2개이다. 왜냐하면 x2≥1.5,x1≥2.5 영역에서 남아있는 라벨은 모두 주황색인데 이중 2개를 파란색으로 분류하기 때문이다. 또한 분리되기 전 오분류 개수는 0이다. 왜냐하면 x2≥1.5,x1≥2.5 영역에서 모두 주황색으로 분류하기 때문이다.
이제 분리된 후 오분류 개수와 분리되기 전 오분류 개수를 비교한다. 이때 분리되기 전 오분류 개수가 적다면 가지치기를 수행하고 아니라면 유지한다. 이 경우 분리되기 전 오분류 개수가 적으므로 t3를 가지치기한다.
2 단계
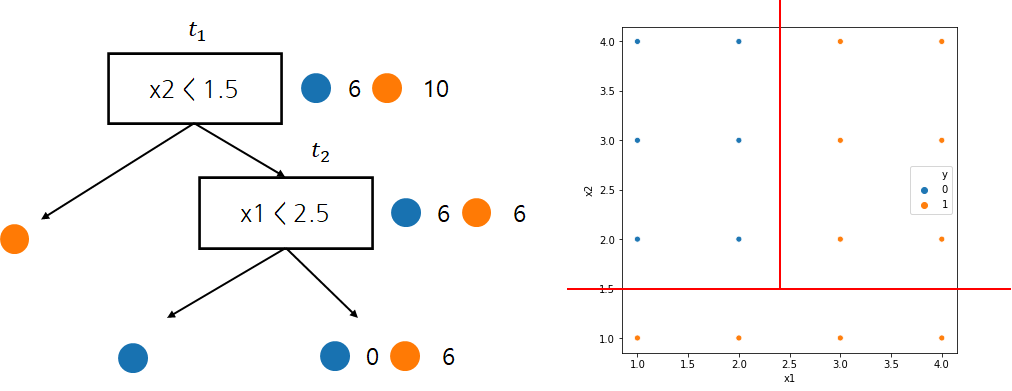
| t | 분리된 후 오분류 개수 | 분리되기 전 오분류 개수 | 가지치기 여부 |
| t2 | 0 | 6 | No |
여기에서는 분리되기전 오분류 개수가 많으므로 가지치기는 일어나지 않고 REP는 종료된다. 이때 남겨진 의사결정나무를 최종 모형으로 선택한다.
- 장단점 -
1. 장점
- 구현이 간단하다.
- 알고리즘이 직관적이라 이해하기 쉽다.
2. 단점
- REP는 검증 데이터를 통해서 가지치기가 진행되는데 이때 검증 데이터의 수가 적으면 필요 이상으로 가지치기(Over Pruning)이 될 수 있다.
3. 구현하기(Implementation)
이번엔 앞서 배운 것들은 Python을 이용하여 구현해보고자 한다. 먼저 전체 코드는 다음과 같다.
1. Cost Complexity Pruning
먼저 구현에 필요한 모듈을 불러오자. 이 모듈은 아래에서 다룰 REP 구현에도 사용되는 모듈이다.
from graphviz import * from sklearn.datasets import load_boston, load_breast_cancer from collections import Counter from itertools import chain, combinations from sklearn.model_selection import train_test_split from tqdm import tqdm import copy import ast import matplotlib.pyplot as plt import pandas as pd import numpy as np import graphviz import seaborn as sns
이제 CCP에서 필요한 함수와 클래스를 정의한다. 이때 Node, DecisionTree 클래스와 visualize_tree, RGBtoHex, is_integer_num에 대해서는 이전 포스팅에서 소개했으므로 설명은 생략한다.
먼저 나무에 있는 모든 마디(끝 마디)를 찾는 traverseInOrder, 나무에 포함된 끝마디 개수를 찾아주는 getNumOfLeaves, 나무에 포함된 모든 중간 노드를 찾아주는 getNodes 함수를 정의한다.
def traverseInOrder(node): res = [] if node.leftNode != None: res = res + traverseInOrder(node.leftNode) res.append(node) if node.rightNode != None: res = res + traverseInOrder(node.rightNode) return res def getNumOfLeaves(tree): res = traverseInOrder(tree) res = [node for node in res if node.isTerminal == True] return len(res) def getNodes(tree, remove_terminal = True): res = traverseInOrder(tree) if remove_terminal: res = [node for node in res if node.isTerminal == False] return res
나무에서 특정 노드를 끝 마디로 바꾸는 함수 pruningLeaf와 특정 노드를 가지치기하는 함수 pruningBranch를 정의한다. pruningBranch 함수는 나무의 모든 중간 노드를 돌면서 특정 노드를 만나면 그 노드를 끝 마디로 지정하여 가지치기하게 된다.
def pruningLeaf(node,target_node, X, y, tree_type): if tree_type == 'classification': classes, counts = np.unique(y, return_counts=True) index = counts.argmax() leaf = classes[index] else: leaf = np.mean(y) if target_node == node: if isinstance(leaf, float): if not leaf.is_integer(): leaf = round(leaf,2) return Node(target_node.nodeId, label=leaf, isTerminal=True) else: return node def pruningBranch(node, target_node, X, y, tree_type): left_child = node.leftNode right_child = node.rightNode if (left_child.isTerminal == True and right_child.isTerminal == True) or\ (node==target_node): return pruningLeaf(node, target_node, X, y, tree_type) else: tr_yes_idx, tr_no_idx = filterX(X, node) if left_child.isTerminal == False: left_child = pruningBranch(node.leftNode, target_node, X.loc[tr_yes_idx], y[tr_yes_idx], tree_type) if right_child.isTerminal == False: right_child = pruningBranch(node.rightNode, target_node, X.loc[tr_no_idx], y[tr_no_idx], tree_type) attr = node.attr node = Node(node.nodeId, label=node.label, isTerminal=node.isTerminal) node.attr = attr node.leftNode = left_child left_child.parentNode = node node.rightNode = right_child right_child.parentNode = node return pruningLeaf(node, target_node, X, y, tree_type)
다음으로 특정 데이터를 노드의 질문에 따라 분리해주는 filterX 함수, 리스트에서 중복이 있는 원소의 인덱스를 추출하는 list_duplicates_of, 각 노드의 질문과 답에 대응하는 데이터의 인덱스를 추출하는 getSampleIndex 함수도 정의한다.
def list_duplicates_of(seq,item): start_at = -1 locs = [] while True: try: loc = seq.index(item,start_at+1) except ValueError: break else: locs.append(loc) start_at = loc return locs def getQuestions(tree, nodes,node_id): target_node = [node for node in nodes if node.nodeId == node_id][0] questions = [] answers = [] if target_node.isRoot == True: return questions, answers while True: if target_node.parentNode: parent_node = target_node.parentNode questions.append(parent_node.label) if target_node == parent_node.leftNode: answers.append('yes') else: answers.append('no') target_node = parent_node else: questions = [x.split('\n')[0] for x in questions] return questions[::-1], answers[::-1] def getSampleIndex(X, questions, answers): for i, question in enumerate(questions): if ' <= ' in question: col_name, value = question.split(' <= ') if answers[i] == 'yes': X = X.loc[X[col_name] <= float(value)] else: X = X.loc[X[col_name] > float(value)] else: col_name, value = question.split(' in ') if answers[i] == 'yes': X = X.loc[X[col_name] in ast.literal_eval(value)] else: X = X.loc[X[col_name] not in ast.literal_eval(value)] return X.index
이제 핵심이라 할 수 있는 pruning 함수에 대해서 알아보자.
def pruning(clf, X, y): tree_type = clf.tree_type alpha_list = [] pruned_tree_list = [] alpha_list.append(0) pruned_tree_list.append(clf.root) tree_copy = copy.deepcopy(clf.root) while True: ## copy tree not to change nodes = getNodes(tree_copy) ## internel node all_node_id = [node.nodeId for node in nodes] id_to_node = dict(zip(all_node_id, nodes)) total_sample = len(X) ## 각 노드마다 오분류율 또는 오차 제곱과 샘플 비율 obj_values= [] for node_id in all_node_id: target_node = id_to_node[node_id] num_of_leave = getNumOfLeaves(target_node) questions, answers = getQuestions(clf.root, nodes, node_id) if questions: target_idx = getSampleIndex(X, questions, answers) else: target_idx = X.index # target_samples.append(len(target_idx)) target_X = X.loc[target_idx,:] target_y = y[target_idx] ## classification 인 경우와 regression인 경우를 나누어야한다. if tree_type == 'classification': classes, counts = np.unique(target_y, return_counts=True) index = counts.argmax() node_predict = classes[index] node_error = sum(target_y != node_predict)/total_sample tn = DecisionTree() tn.root = target_node branch_predict = tn.predict(target_X) branch_error = sum(target_y != branch_predict)/total_sample else: node_predict = np.mean(target_y) node_error = sum(np.square(target_y-node_predict))/total_sample tn = DecisionTree('regression') tn.root = target_node branch_predict = tn.predict(target_X) branch_error = sum(np.square(target_y-branch_predict))/total_sample obj_value = (node_error - branch_error)/(num_of_leave - 1) obj_values.append(obj_value) min_obj_value = min(obj_values) min_node_id = [n for i, n in enumerate(all_node_id) if obj_values[i] == min_obj_value] target_prune_node_id = min_node_id[0] if len(min_node_id) > 1: min_nodes = [] for mni in min_node_id: min_nodes.append(id_to_node[mni]) min_leaves_idx = np.argmin([getNumOfLeaves(x) for x in min_nodes]) target_prune_node_id = min_node_id[min_leaves_idx] target_prune_node = id_to_node[target_prune_node_id] pruned_tree = pruningBranch(tree_copy, target_prune_node, X, y, tree_type=tree_type) pruned_node = [node for node in getNodes(pruned_tree, remove_terminal=False) if node.nodeId == target_prune_node_id][0] if tree_type == 'classification': pruned_node.attr = clf.leaf_attr[pruned_node.label] else: pruned_node.attr = {'shape':'box','peripheries':'2'} alpha_list.append(min_obj_value) pruned_tree_list.append(pruned_tree) if target_prune_node_id == 1: break else: tree_copy = copy.deepcopy(pruned_tree) if len(alpha_list) > len(set(alpha_list)): valid_idx = [] idx = 0 while idx < len(alpha_list): alpha = alpha_list[idx] locs = list_duplicates_of(alpha_list, alpha) if len(locs) > 1: valid_idx.append(locs[-1]) idx += len(locs) else: valid_idx.append(idx) idx += 1 alpha_list = [x for i, x in enumerate(alpha_list) if i in valid_idx] pruned_tree_list = [x for i, x in enumerate(pruned_tree_list) if i in valid_idx] return alpha_list, pruned_tree_list
pruning 함수는 의사결정나무를 훈련시킨 DecisionTree 클래스와 데이터 X, y를 인자로 받고 α와 그에 대응하는 나무 T의 시퀀스를 출력한다.
line 5~7
먼저 초기값 α=0과 훈련 데이터를 통하여 만들어진 나무를 리스트에 추가한다. 다음으로 의사결정나무를 가지치기해야 하는데 그냥 하면 기존 의사결정나무가 변경되므로 이를 방지하기 위해 기존 나무를 복사한다.
line 8~72
모든 중간 노드를 돌면서 R(t),R(Tt),g(t)를 계산하고(line 10~45) g(t)를 최소화시키는 노드를 찾는다(line 50~59). 그리고 해당 노드를 가지치기한다(line 60). 해당 노드가 끝 마디가 되므로 이에 대응하는 시각화 스타일을 지정한다(line 61~65). 다음으로 g(t)의 최소값을 alpha_list에 추가하고 가지치기된 나무를 pruned_tree_list에 추가한다(line 67~68). 만약 노드가 뿌리 마디(뿌리 마디는 노드 아이디가 1번으로 설정됨)라면 알고리즘을 멈추고 아니라면 가지치기된 나무를 복사하여 알고리즘을 반복한다(line 69~72).
line 74~88
추가적으로 중복된 α가 있다면 이를 제거해주고 그에 대응하는 나무도 제거해준다.
마지막으로 앞서 구한 나무들의 시퀀스와 검증 데이터를 이용하여 비용 함수를 계산한다. 이때 분류 나무인 경우에는 오분류율, 회귀 나무인 경우에는 평균 오차 제곱합을 비용 함수로 설정한다. 원래 교차 검증하는 코드도 만들었으나 조금 느려서 생략했다.
def getCostValues(pruned_tree_list, X_val, y_val, tree_type): cost_vals = [] for pt in pruned_tree_list: dt = DecisionTree(tree_type) dt.root = pt predict = dt.predict(X_val) if tree_type == 'classification': cost_val = sum(y_val!=predict)/len(y_val) else: cost_val = sum(np.square(y_val-predict))/len(y_val) cost_vals.append(cost_val) return cost_vals
2. Reduced Error Pruning
REP는 DecisionTree 내부에서 동작하도록 설계했다. 방법이 단순하기 때문에 그렇게 했다. REP는 DecisionTree 클래스에서 pruning 메서드를 통해 수행되며 훈련된 의사결정나무(node)와 검증 데이터(X_val, y_val)을 인자로 받고 내부 함수인 _pruning을 통해 가지치기된 나무를 출력한다. _filterX는 위에서 살펴본 filterX와 동일한 기능을 한다. _pruning_leaf은 특정 노드에서 분리되기 전 에러(errors_leaf)와 분리된 후 에러(errors_decision_node)를 비교하여 분리되기전 에러가 더 작으면 가지치기를 수행하고 아니면 유지시킨다. _pruning 함수는 모든 중간 노드를 돌면서 _pruning_leaf을 통하여 가지치기를 수행한다.
class DecisionTree: ''' 중략 ''' def pruning(self, node, X_val, y_val): X = self.X X = X.reset_index(drop=True) y = self.y # y = y.reset_index(drop=True) if isinstance(y, pd.Series): y = y.reset return self._pruning(node, X, y, X_val, y_val) def _filterX(self, X, node): question = node.label.split('\n')[0] if ' <= ' in question: col_name, value = question.split(' <= ') yes_index = X.loc[X[col_name] <= float(value)].index no_index = X.loc[X[col_name] > float(value)].index else: col_name, value = question.split(' in ') yes_index = X.loc[X[col_name].isin(ast.literal_eval(value))].index no_index = X.loc[~X[col_name].isin(ast.literal_eval(value))].index return yes_index, no_index def _pruning_leaf(self, node, X, y, X_val, y_val): if self.tree_type == 'classification': classes, counts = np.unique(y, return_counts=True) index = counts.argmax() leaf = classes[index] attr = self.leaf_attr[leaf] errors_leaf = np.sum(y_val != leaf) errors_decision_node = np.sum(y_val != self.predict(X_val)) ##<---self로 바꿔야해 else: leaf = np.mean(y) errors_leaf = np.mean(np.square(y_val-leaf)) errors_decision_node = np.mean(np.square(y_val-self.predict(X_val))) attr = {'shape':'box','peripheries':'2'} if errors_leaf <= errors_decision_node: if isinstance(leaf, float): if not leaf.is_integer(): leaf = round(leaf,2) return Node(node.nodeId, label=leaf, isTerminal=True, attr=attr) else: return node def _pruning(self, node, X, y, X_val, y_val): # assert self.root is not None, 'you must fit first' X = X.reset_index(drop=True) X_val = X_val.reset_index(drop=True) # X_val.index = list(X_val.index) # y_val = y_val.reset_index(drop=True) left_child = node.leftNode right_child = node.rightNode if node.leftNode.isTerminal == True and node.rightNode.isTerminal == True: return self._pruning_leaf(node, X, y, X_val, y_val) else: tr_yes_idx, tr_no_idx = self._filterX(X, node) val_yes_idx, val_no_idx = self._filterX(X_val, node) if node.leftNode.isTerminal == False: left_child = self._pruning(node.leftNode, X.loc[tr_yes_idx, :], y[tr_yes_idx], X_val.loc[val_yes_idx], y_val[val_yes_idx]) if node.rightNode.isTerminal == False: right_child = self._pruning(node.rightNode, X.loc[tr_no_idx, :], y[tr_no_idx], X_val.loc[val_no_idx, :], y_val[val_no_idx]) attr = node.attr node = Node(node.nodeId, label=node.label, isTerminal=node.isTerminal) node.attr = attr node.leftNode = left_child left_child.parentNode = node node.rightNode = right_child right_child.parentNode = node return self._pruning_leaf(node, X, y, X_val, y_val)
4. 데이터에 적용해보기
앞서 구현한 코드를 이용하여 실제 데이터에 적용해보자.
1. Cost Complexity Pruning
1.1 분류 나무
먼저 Breast Cancer 데이터를 이용하여 의사결정나무를 훈련한다.
cancer = load_breast_cancer() df = pd.DataFrame(np.c_[cancer['data'], cancer['target']], columns= np.append(cancer['feature_names'], ['target'])) X = df[[col for col in df.columns if col != 'target']] y = df['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42) X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.33, random_state=42) clf = DecisionTree() clf.fit(X_train,y_train, min_sample=5, max_depth=3,type_of_col=['continuous']*X.shape[1], auto_determine_type_of_col=False)
이 나무의 성능을 먼저 살펴보자. 이후 가지치기된 성능과 어떻게 달라지는지 비교해볼 것이다.
predict = clf.predict(X_test) accuracy = sum(y_test == predict)/len(y_test) print(accuracy)
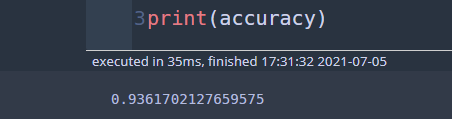
정확도가 약 93.6%가 나왔다. 이 나무를 시각화해보자.
visualize_tree(clf.root)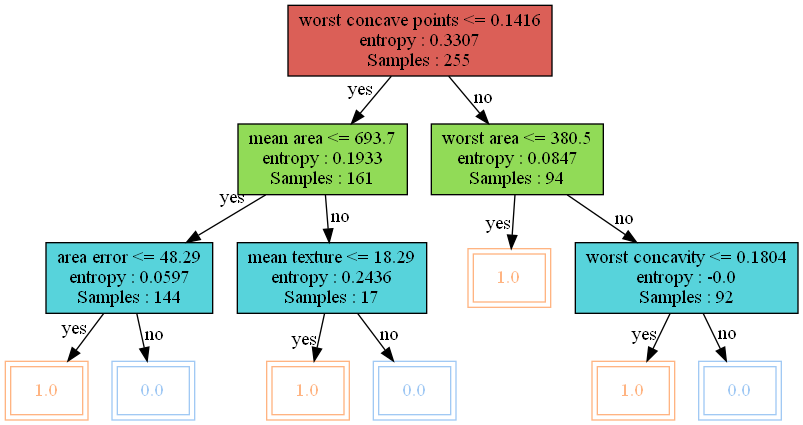
이제 CCP를 수행하자.
alpha_list, pruned_tree_list = pruning(clf, X_train, y_train)
검증 데이터를 이용하여 각 나무에 대한 비용을 계산한다.
cost_vals = getCostValues(pruned_tree_list, X_val, y_val, clf.tree_type)
α에 따른 비용 값의 변화를 확인해보자.
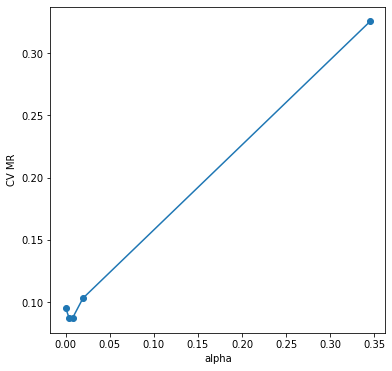
α가 증가할 때 감소하다가 다시 증가하는 경향이 있다. 이제 최종 가지치기 나무를 선택하고 이를 시각화해보자.
final_tree = pruned_tree_list[np.argmin(cost_vals)] visualize_tree(final_tree)
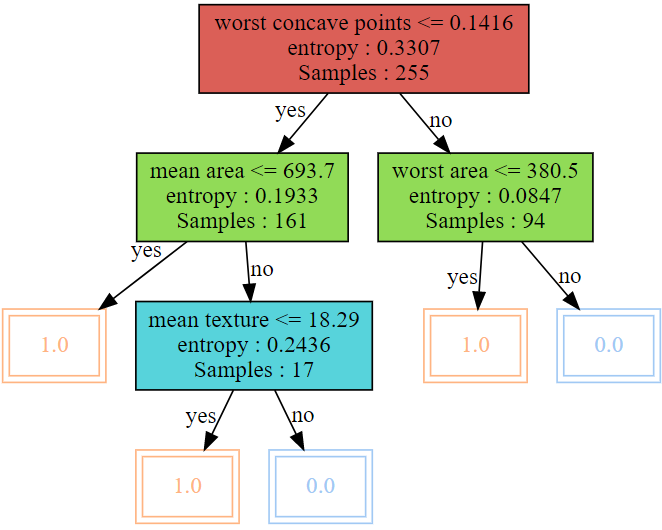
이제 최종 나무의 성능을 측정해보자.
dt = DecisionTree() dt.root = final_tree predict = dt.predict(X_test) accuracy = sum(y_test == predict)/len(y_test) print(accuracy)
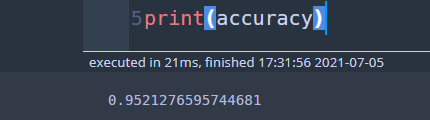
정확도는 95.2%이며 이는 이전 93.6%보다 더 높아진 성능을 나타낸다. 가지치기가 효과가 있었다!!
1.2 회귀 나무
이번엔 Boston 집값 데이터에 대해서 CCP를 적용해보자. 먼저 기본적인 의사결정나무를 만들어준다.
lb = load_boston() df = pd.DataFrame(lb.data, columns=lb.feature_names) df['MEDV'] = lb.target X = df[[col for col in df.columns if col != 'MEDV']] y = df['MEDV'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42) X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.33, random_state=42) reg = DecisionTree(tree_type = 'regression') reg.fit(X_train,y_train,impurity_measure='mse',max_depth=4)
만들어진 의사결정나무를 시각화해보자.
visualize_tree(reg.root)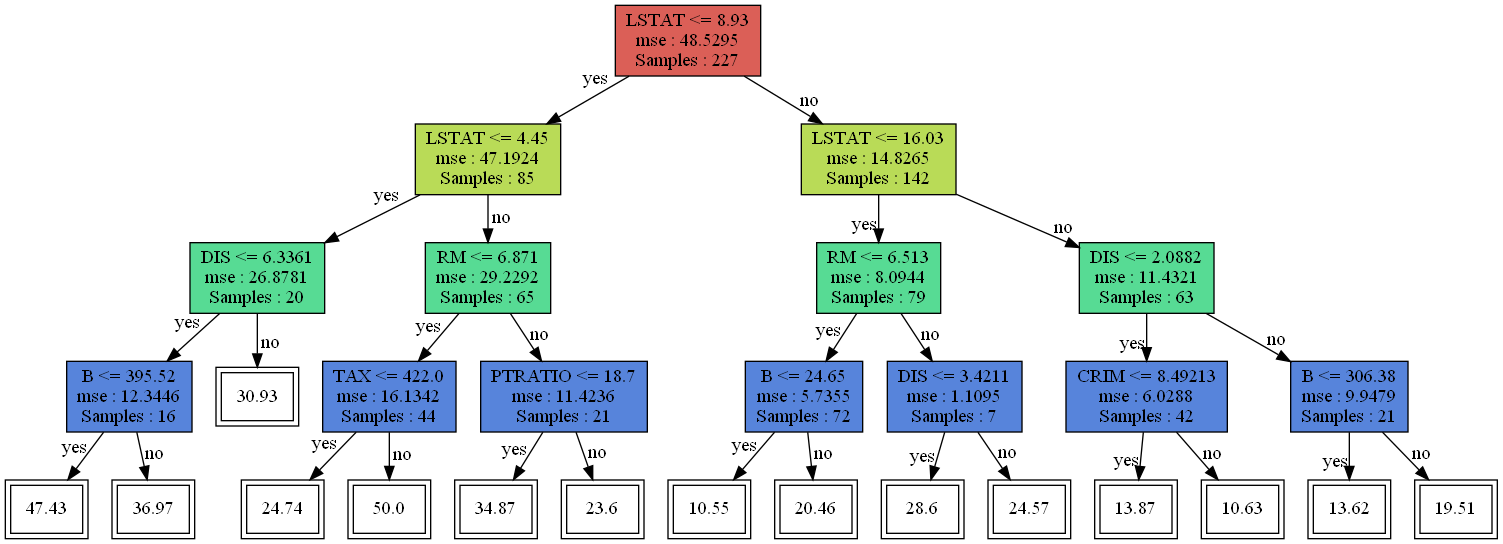
이 회귀 나무의 성능을 측정해보자.
predict = reg.predict(X_test) mse = sum(np.square(y_test - predict))/len(y_test) print(mse)
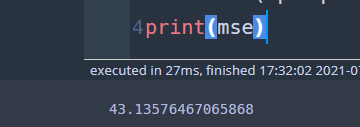
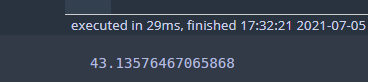
평균 오차 제곱합은 43.16 정도가 나왔다. 이제 CCP를 수행하고 그 결과 얻어진 나무들의 시퀀스에 대하여 비용 함수를 계산한다.
alpha_list, pruned_tree_list = pruning(reg, X_train, y_train) cost_vals = getCostValues(pruned_tree_list, X_val, y_val, reg.tree_type)
α에 대하여 비용(cost)이 어떻게 변하는지 살펴보자.
fig = plt.figure(figsize=(6,6)) fig.set_facecolor('white') plt.plot(alpha_list, cost_vals, marker='o') plt.xlabel('alpha') plt.ylabel('CV MR') plt.show()
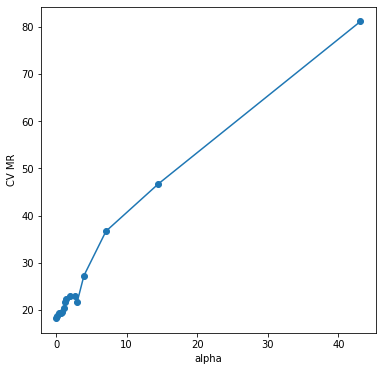
음 그림을 살펴보니 가지치기를 하지 않는 나무가 선택될 것 같다. 최종 나무를 선택하고 시각화해보자.
final_tree = pruned_tree_list[np.argmin(cost_vals)] visualize_tree(final_tree)
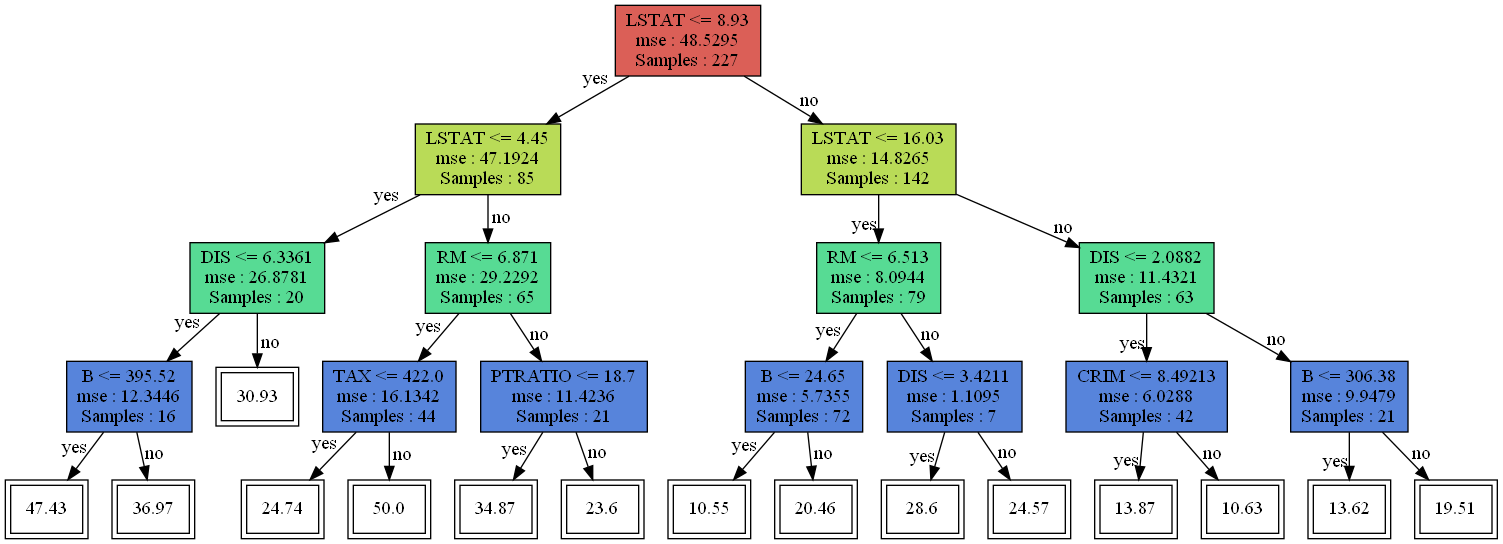
역시 가지치기는 일어나지 않았다. 따라서 이전과 똑같은 성능을 보일 것이다.
dt = DecisionTree('regression') dt.root = final_tree predict = dt.predict(X_test) mse = sum(np.square(y_test-predict))/len(y_test) print(mse)
2. Reduced Error Pruning
2.1 분류 나무
여기에서는 타이타닉 데이터를 이용하여 REP를 수행하고자 한다. 데이터는 아래에서 다운받아준다.
타이타닉 데이터에 대하여 의사결정나무를 만들어주고 REP를 수행한다.
df = pd.read_csv('../dataset/titanic.csv') median_age = df['Age'].median() mode_embarked = df['Embarked'].mode()[0] df = df.fillna({'Age':median_age, 'Embarked':mode_embarked}) X = df[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']] y = df['Survived'].values X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42) X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.33, random_state=42) X_val = X_val.reset_index(drop=True) clf = DecisionTree() clf.fit(X_train,y_train, min_sample=5, max_depth=4) pruned_tree = clf.pruning(clf.root, X_val, y_val)
먼저 REP를 하지 않는 의사결정나무의 성능을 확인해보자.
predict = clf.predict(X_test) accuracy = sum(y_test== predict)/len(y_test) print(accuracy)

정확도는 80.3%가 나왔다. 다음으로 이 나무를 시각화해보자.
visualize_tree(clf.root)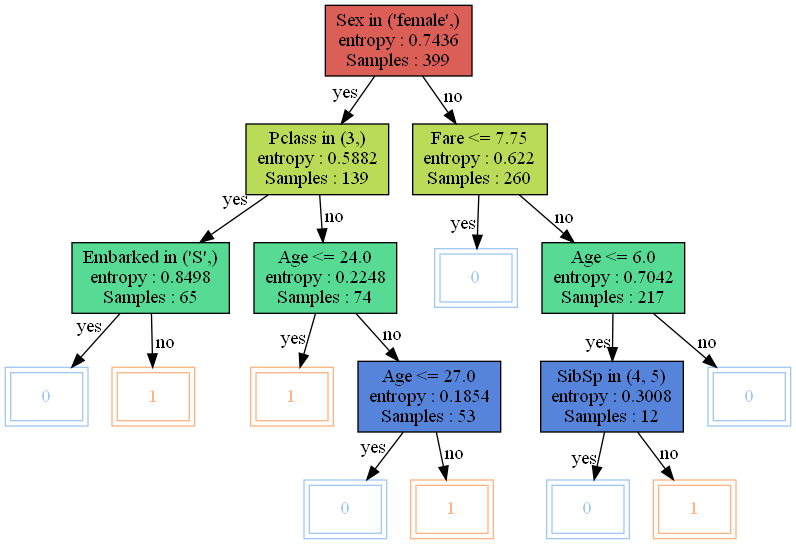
이제 REP를 수행한 최종 나무의 성능을 확인해보자.
dt = DecisionTree() dt.root = pruned_tree predict = dt.predict(X_test) accuracy = sum(y_test== predict)/len(y_test) print(accuracy)
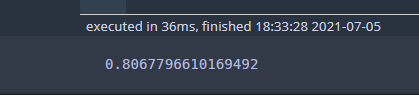
정확도는 80.7%로써 아까보다 높아진 것을 확인할 수 있다. 최종 나무를 시각적으로 확인해봐야 속이 편할 것 같다.
visualize_tree(pruned_tree)
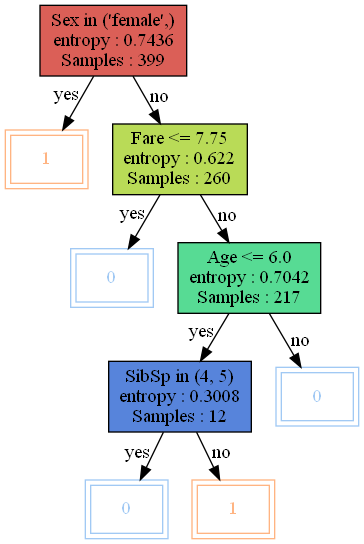
기존 나무에서 왼쪽 부분이 가지치기된 것을 알 수 있다.
2.2 회귀 나무
이전과 똑같이 기본 의사결정나무를 만들어준다.
lb = load_boston() df = pd.DataFrame(lb.data, columns=lb.feature_names) df['MEDV'] = lb.target X = df[[col for col in df.columns if col != 'MEDV']] y = df['MEDV'].values X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42) X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.33, random_state=42) X_val = X_val.reset_index(drop=True) # y_val = y_val.values reg = DecisionTree(tree_type = 'regression') reg.fit(X_train,y_train,impurity_measure='mse',max_depth=4)
성능을 측정해보자.
predict = reg.predict(X_test) mse = sum(np.square(y_test - predict))/len(y_test) print(mse)
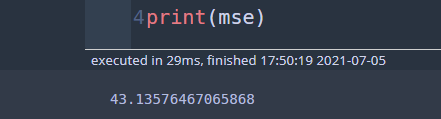
나무를 그려보자.
visualize_tree(reg.root)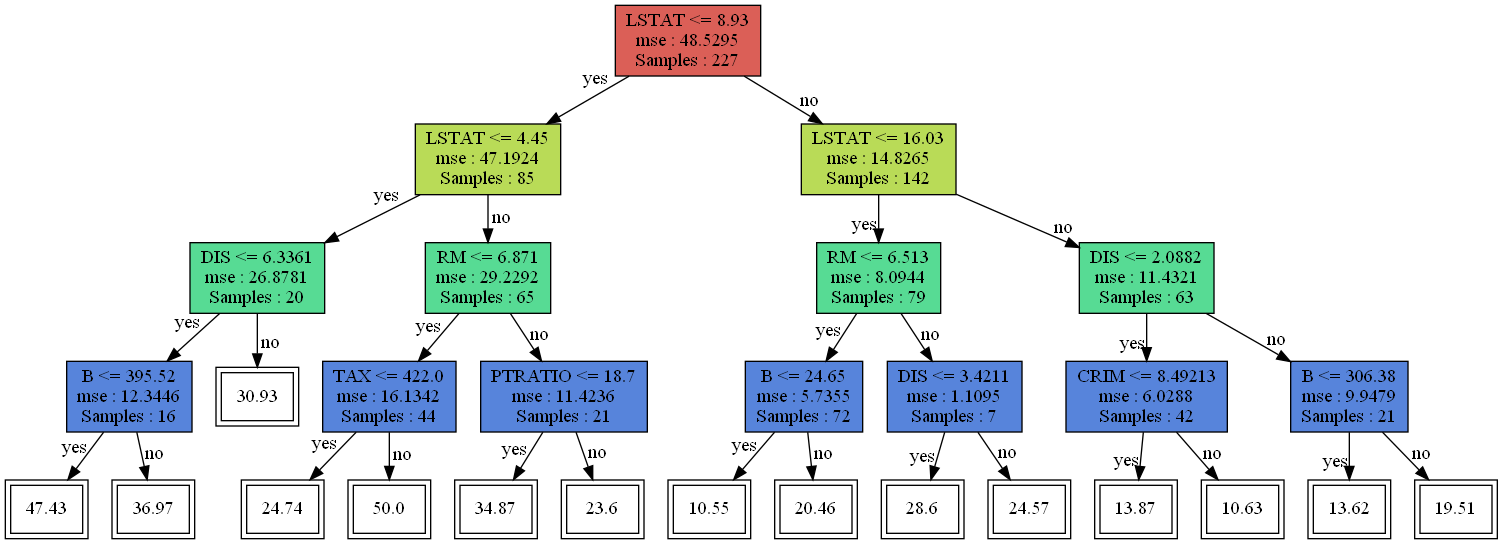
이번엔 REP를 수행하여 가지를 쳐보자.
pruned_tree = reg.pruning(reg.root, X_val, y_val)
시각화를 통하여 가지치기가 일어났는지 확인해보자.
visualize_tree(pruned_tree)
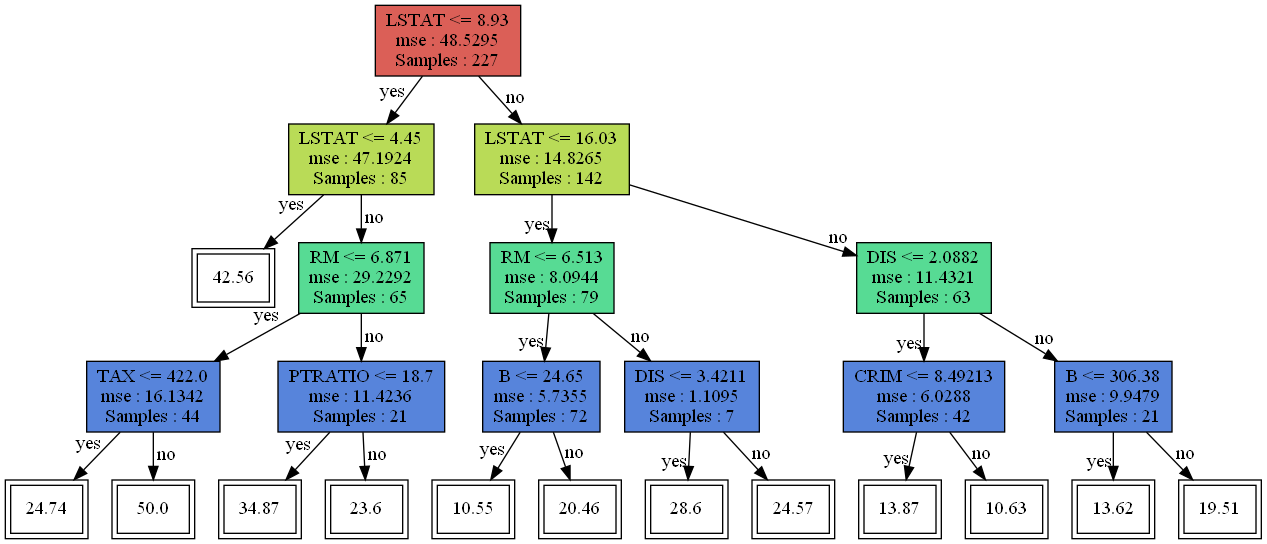
비교해보면 가장 왼쪽 부분에서 가지치기가 일어났다. 그렇다면 성능은 좋아졌을까?
## not pruned dt = DecisionTree('regression') dt.root = pruned_tree predict = dt.predict(X_test) mse = sum(np.square(y_test - predict))/len(y_test) print(mse)
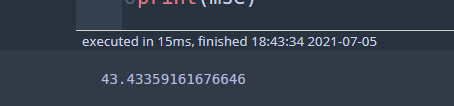
43.43으로 아까보다 성능이 안 좋아졌다. 이는 검증 데이터 패턴의 영향인 듯싶다. 회귀 나무의 경우 가지치기의 성능은 별로 안 좋은가 보다.
이번 포스팅에서는 가지치기에 대한 내용을 살펴보았다. 여기서 소개한 CCP, REP 외에도 여러 가지가 있었다. Pessimistic Error Pruning, Minimum Error Pruning, Critical Value Pruning 등이 더 있었다. 이 부분은 나중에 시간 되면 더 공부해봐야겠다.
참고자료
https://www.youtube.com/watch?v=u4kbPtiVVB8&t=1s
https://online.stat.psu.edu/stat508/lesson/11/11.8/11.8.2
https://matthewmcgonagle.github.io/blog/2018/09/13/PruningDecisionTree
http://mlwiki.org/index.php/Cost-Complexity_Pruning

'통계 > 머신러닝' 카테고리의 다른 글
| 12. 클러스터링(군집화) 평가 지표 Dunn Index with Python (401) | 2022.04.22 |
|---|---|
| 11. K-Means 클러스터링(Clustering, 군집화)에 대해서 알아보자 with Python (410) | 2022.04.21 |
| 9. 의사결정나무(Decision Tree) 에 대해서 알아보자 with Python (1275) | 2021.06.10 |
| 8. 연관 규칙 분석(Association Rule Analysis) with Python (1108) | 2021.05.23 |
| [Quantile Regression] 2. Quantile regression : Understanding how and why? (1557) | 2021.05.05 |





댓글