안녕하세요~ 꽁냥이에요.
저번 포스팅에서는 RFM에 대한 기본 개념과 분석 과정을 알아봤고요. 이번 포스팅에서는 실제 데이터를 통해서 RFM 분석을 해보려고 합니다. RFM 분석 개념과 분석 과정이 궁금하신 분들은 아래 포스팅을 참고하세요.
RFM 고객[RFM 고객 분석] 1. RFM 고객 분석이 무엇일까요? : zephyrus1111.tistory.com/12
[RFM 고객 분석] 1. RFM 고객 분석이 무엇일까요?
안녕하세요~ 꽁냥이입니다. 이번 포스팅에서는 CRM(Customer relationship management : 고객관계 관리)분야에서 고객의 가치를 분석하는 데 사용되는 RFM 분석에 대해서 알아보려고 합니다. RFM분석에서 "RFM
zephyrus1111.tistory.com
이번 포스팅에서 다룰 내용은 다음과 같습니다.

1. 데이터 준비하기
먼저 이번에 사용할 데이터는 KAGGLE에서 제공하는 온라인 거래 데이터입니다. 데이터는 아래 첨부파일을 다운로드하고 압축을 풀어주세요.
2. 데이터 살펴보기
데이터를 다운받았으니 이제 읽어봐야겠죠? 아래 코드를 실행해주세요.
(코드에 대한 설명은 "데이터 분석과 직접적으로 연관된 것"을 위주로 할 거예요. 그 외 코드는 주석을 참고하시면 됩니다.)
## 데이터 보기
import pandas as pd
df = pd.read_csv('ecommerce-data.csv', encoding = 'ISO-8859-1') ## 인코딩 지정 안해주면 에러남꽁냥이는 pandas 모듈에서 제공하는 read_csv메서드를 사용하여 csv형식 데이터를 불러왔습니다. 이때 데이터가 있는 경로를 각자 상황에 맞게 설정해주세요. 꽁냥이는 데이터를 코드와 동일한 위치(같은 폴더 내)에 저장했어요.
여기서 주의하실 점은 반드시 encoding인자에 'ISO-8859-1'을 넣어주는 것입니다. 안그러면 에러가 발생하거든요.
이 데이터안에는 어떤 변수들이 있을까요? 아래 코드를 실행해보세요.
## 칼럼보기
for col in df.columns:
print(col)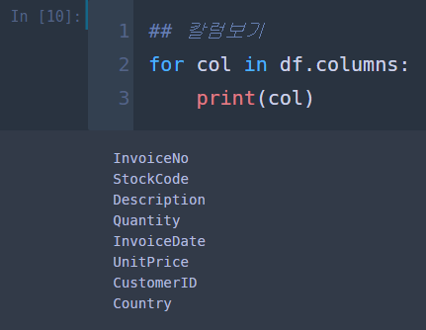
총 8개의 변수가 있는데요. 각 변수의 의미는 다음과 같습니다.

데이터 개수(행 개수)는 얼마나 될까요? 아래 코드를 실행해보세요.
print(len(df)) ## 데이터 개수
약 54만 건의 데이터가 있군요!!
다음으로 거래가 이루어진 기간을 '연도'와 '월'로 보려고 해요.
## 기간 보기
df['InvoiceDate'] = pd.to_datetime(df['InvoiceDate']) ## 문자열로된 날짜를 Timestamp형식으로 변환
set_of_year_month = list(set([(x.year, x.month) for x in df['InvoiceDate']])) ## 송장날짜에서 연도와 월정보를 가져온다.
for ym in sorted(set_of_year_month, key=lambda x: (x[0], x[1])): ## 연도와 월정보를 연도, 월 순으로 출력
print(f'{ym[0]}년 {ym[1]}월')
아하! 이 데이터는 2010년 12월부터 2011년 12월까지의 거래내역을 보여주는 거였네요~!!
이번에는 나라별 데이터 분포는 어떻게 되는지 알아볼까요? 나라별 데이터 개수를 바 차트로 그려보겠습니다. 아래 코드를 실행해보세요.
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter
nation_data = Counter(df['Country']).most_common() ## 데이터 개수가 많은 순으로 출력
nation_data = nation_data[:5] ## 상위 5개만 저장
data = [x[1] for x in nation_data] ## 데이터 개수
nations = [x[0] for x in nation_data] ## 국가
## 수평 바차트에서 데이터 개수와 나라를 맨위로 출력하기 위해서 리스트 순서를 바꿈
nations.reverse()
data.reverse()
## 시각화
fig =plt.figure(figsize=(8,8))
fig.set_facecolor('white') ## 캔버스 색깔
colors = sns.color_palette('hls',len(data)) ## color 생성
plt.yticks(fontsize=15) # y축 눈금 라벨 폰트사이즈 설정
plt.xticks(fontsize=12) # x축 눈금 라벨 폰트사이즈 설정
plt.barh(nations, data, color=colors,alpha=0.6,edgecolor='k') ## 수평바차트 생성
plt.show()
와우 United Kingdom의 데이터는 약 50만 건이네요. 압도적으로 많군요~~
데이터를 살펴보는 건 이 정도로 마치겠습니다.
바 차트 그리는 방법은 꽁냥이가 따로 정리해놓았어요. 아래 링크로 들어가시면 됩니다.
- Matplotlib을 이용하여 바 차트, 수평 바 차트 그리기 : https://zephyrus1111.tistory.com/8
[바 차트(Bar chart)] 1. Matplotlib을 이용하여 바 차트, 수평 바 차트 그리기
안녕하세요~ '꽁냥이'입니다. 이번 포스팅에서는 바 차트(Bar chart)를 그려보는 법에 대해서 알아볼 거예요. 꽁냥이는 "바 차트 그리기"에 대한 내용을 다음과 같이 5편에 걸쳐서 소개할 거예요. 1.
zephyrus1111.tistory.com
- Matplotlib을 이용하여 바 차트 꾸미기 : https://zephyrus1111.tistory.com/9
[바 차트(Bar chart)] 2. Matplotlib을 이용하여 바 차트 꾸미기
안녕하세요~ '꽁냥이'입니다. [바 차트(Bar chart)] 1. Matplotlib을 이용하여 바 차트, 수평 바 차트 그리기에 이어서 이번 포스팅에서는 Matplotlib을 이용하여 바 차트를 좀 더 예쁘게 꾸며보는 방법에 �
zephyrus1111.tistory.com
- Matplotlib 바 차트 번외 - 막대에 그라데이션 적용하기 : https://zephyrus1111.tistory.com/11
[바 차트(Bar chart)] 3. Matplotlib 바 차트 번외 - 막대에 그라데이션 적용하기
안녕하세요~ '꽁냥이'입니다. 이번 포스팅에서는 바 차트(Bar chart) 번외 편으로 막대에 그라데이션을 적용하는 방법을 소개합니다. 사실 이 내용을 이전 포스팅([바 차트(Bar chart)] 2. Matplotlib을 이�
zephyrus1111.tistory.com
3. 데이터 전처리
데이터 분석 용도에 맞게 데이터 전처리를 해볼게요. 전체 코드는 다음과 같습니다.
######### 데이터 전처리
import pandas as pd
df['InvoiceDate'] = pd.to_datetime(df['InvoiceDate']) ## 문자열로된 날짜를 Timestamp형식으로 변환
## 분석할 나라와 연도 설정
target_country = 'United Kingdom'
target_year = '2011'
df = df.query('Country == @target_country and InvoiceDate.dt.year == @target_year')
## 필요한 칼럼 추출
df = df[['InvoiceNo', 'Quantity', 'InvoiceDate', 'UnitPrice', 'CustomerID']]
## 결측값 처리
df = df.dropna()
## 구매 취소 데이터 삭제
## 송장번호 앞에 'C'가 있으면 삭제 구매취소된 데이터를 의미한다. 여기서는 단순히 'C'가 있는지 없는지만 보면된다.
df = df.query('InvoiceNo.str.get(0) != "C"')line 4
먼저 최근 방문일을 초단위로 변경하는 것을 쉽게 하기 위하여 거래 날짜(InvoiceDate) 데이터를 pd.to_datetime을 이용하여 Timestamp형식으로 바꿔줍니다.
line 7~10
꽁냥이는 국가가 'United Kingdom'이고 해당 기간은 2011년도인 데이터만 뽑아서 분석하려고 해요. 그 이유는 위에서 보셨듯이 'United Kingdom'의 데이터가 압도적으로 많고 2011년도만 1월부터 12월까지의 데이터가 있기 때문이죠.
line 13
필요한 변수만 추출합니다. CustomerID는 고객을 식별하는 도구로써 반드시 필요하고요. InvoiceDate는 최근 방문일을 구하는 데 사용되고, InvoiceNo은 방문횟수를 그리고 Quantity와 UnitPrice는 구매금액을 구하는데 사용됩니다.
line 16
문제를 단순화하기 위해 결측 값이 있는 행은 모두 삭제했습니다.
line 21
위에서 살펴봤듯이 거래 취소 내역도 존재하기 때문에 이를 제외합니다.
이번 포스팅에서 필요한 데이터 전처리는 모두 끝났어요. 다음 단계로 넘어가 볼까요?
4. 데이터 분석하기
데이터 분석에 들어가기에 앞서 목표를 설정하려고 합니다. 여기서 꽁냥이가 말하는 '목표'는 '분석 결과물'을 의미하는 거예요.
꽁냥이의 목표는 다음과 같이 고객별로 최근 방문일, 방문 횟수, 구매금액 기준으로 점수를 정리하는 것이에요.

그리고 여기서 데이터 분석을 한다는 것은 온라인 거래 데이터에서 고객별로 최근방문일, 방문횟수, 구매금액 기준으로 점수를 구한다는 뜻이에요.

다음은 데이터 분석 전체 코드예요(위에서 데이터 불러오는 코드와 데이터 전처리 코드를 꼭 실행해주세요).
######### 데이터 분석
import pandas as pd
from tqdm import tqdm
customer_id = list(df['CustomerID'].unique()) ## 고객아이디
## 먼저 각 고객별로 구매금액이 얼마인지 알아보자.
monetary_df = pd.DataFrame() ## 구매금액 데이터 초기화
monetary_df['CustomerID'] = customer_id ## 고객아이디 삽입
monetary_data = [] ## 구매금액을 담을 리스트
for ci in tqdm(customer_id,position=0,desc='Calculating amount of individual customer'):
temp = df.query('CustomerID==@ci') ## 해당 아이디의 고객데이터 추출
amount = sum(temp['Quantity'] * temp['UnitPrice']) ## 해당 고객 구매금액
monetary_data.append(amount)
monetary_df['Monetary'] = monetary_data ## 구매금액 데이터 삽입
## 각 고객별 최근방문일을 알아보자.
temp_recency_df = df[['CustomerID','InvoiceDate']].drop_duplicates() ## 고객 아이디와 송장날짜만 추출한뒤 중복 제거
recency_df = temp_recency_df.groupby('CustomerID')['InvoiceDate'].max().reset_index() ## 아이디로 그룹화 한다음 최근방문일을 구해야 하므로 송장날짜에 max를 적용한다.
recency_df = recency_df.rename(columns={'InvoiceDate':'Recency'})
## 각 고객별 방문횟수를 알아보자.
temp_frequency_df = df[['CustomerID','InvoiceNo']].drop_duplicates() ## 고객 아이디와 송장번호만 추출한뒤 중복 제거
frequency_df = temp_frequency_df.groupby('CustomerID')['InvoiceNo'].count().reset_index() ## 아이디로 그룹화 한다음 방문횟수를 구해야 한다. 여기서는 방문횟수를 송장번호 개수로 생각했으므로 송장번호에 count를 적용한다.
frequency_df = frequency_df.rename(columns={'InvoiceNo':'Frequency'})
## 데이터를 고객아이디를 기준으로 합쳐야한다.
rfm_df = pd.merge(recency_df,frequency_df,how='left',on='CustomerID')
rfm_df = pd.merge(rfm_df,monetary_df,how='left',on='CustomerID')line 3
tqdm은 for loop를 실행할 때 progress bar를 출력해주는 모듈입니다. 이를 통해 남은 시간이 얼마인지 알 수 있지요. tqdm 모듈 관련 내용은 여기를 참고하세요.
line 5
고객 아이디를 중복되지 않게 저장합니다.
line 8~9
먼저 구매금액을 만들 거라서 구매금액 데이터를 초기화해주고 CustomerID라는 변수에 고객 아이디를 담아줍니다.
line 11~17
고객 별로 총 구매금액을 리스트에 담을 거예요. 이 부분에서 실행시간이 좀 걸리는데요. 제대로 실행되고 있는지 시간은 얼마나 남았는지 보기 위해 tqdm을 사용했습니다(line 12). 먼저 해당 고객 아이디를 갖는 데이터만 추출한 합니다(line 13). 그리고 구매 수량과 상품 단가를 곱한 뒤 더해주면 총 구매금액이 나오지요(line 14). 마지막으로 위에서 만들어 둔 구매금액 데이터에서 Monetary라는 변수에 구매금액을 삽입합니다(line 17).
line 20
다음으로 고객별 최근 방문일 데이터를 만들 거예요. 먼저 처음에 불러왔던 데이터에서 CustomerID와 InvoiceDate를 추출하고 중복된 값을 제거합니다.
line 21
그리고 고객 아이디별로 최근 방문일을 구해야 합니다. 이를 위해 먼저 CustomerID로 그룹화하고요. 그룹화를 했으면 고객 아이디별로 어떤 InvoiceDate를 선택할지를 결정해줘야 돼요. 꽁냥이는 최근 방문일이 필요하므로 InvoiceDate의 최대값을 가져올 거예요(날짜에도 순서가 있기 때문에 최대값을 적용할 수 있습니다).
line 22
마지막으로 InvoiceDate라는 이름을 최근 방문일을 뜻하는 Recency로 바꿔줍니다.
line 25~27
다음으로 고객별로 방문 횟수를 구해야 합니다. 이는 고객별 최근 방문일 데이터를 만드는 과정과 비슷합니다. 차이점은, InvoiceNo의 개수가 방문횟수를 의미한다는 점, 그리고 개수를 구해야 하므로 그룹화 할때는 최대값(max)이 아닌 집계(count)를 해야한다는 점입니다.
line 30~31
이제 필요한 데이터를 다 만들었으니 이를 합쳐보겠습니다.
먼저 최근 방문일과 방문횟수 데이터를 합치고, 합친 데이터를 다시 구매금액 데이터와 합쳐줍니다.
자 그럼 여기까지 만들어진 데이터를 볼게요.

방문 횟수(Frequency)와 구매금액(Monetary)은 데이터가 숫자라서 이를 가지고 점수를 매기기 쉽지만, 최근 방문일(Recency)은 날짜 형식이라 이를 가지고 점수를 매기기에는 무리가 있어요. 따라서 아래와 같이 추가적인 작업이 필요합니다.

여기서 다음과 같은 질문이 생길 수 있습니다. 바로 "기준시간을 어떻게 잡아야 하는가?"입니다.
선택지는 2가지 정도가 있을것 같아요. 2011년 시작날짜 또는 그 이전을 기준으로 할 수 있고요. 2012년 이후 또는 현재시간을 기준으로 잡을 수도 있습니다. 꽁냥이는 2011년 1월 1일 0분 0시로 잡았습니다. 그 이유는 해석의 방향을 동일하게 하기 위함입니다.
쉽게 말하면 방문 횟수, 구매금액 같은 경우는 숫자 값이 클수록 큰 점수를 주는 것처럼 최근방문일 또한 큰 값을 가질수록 큰 점수를 주기 위함입니다.
즉, 아래 그림과 같이 2011년 1월 1일 0분 0시를 기준(또는 그 이전)으로 하여 최근 방문일과 시간 차이를 계산해주면 그 차이값이 클수록 큰 점수를 부여하게 되지요(우리가 다루고 있는 데이터에서 거래 연도는 2011년이라는 것을 기억하세요). 만약 현재시간을 기준으로 하면 시간 차이가 작을수록 큰 값을 가지게 되므로 해석의 방향이 다르게 되지요.
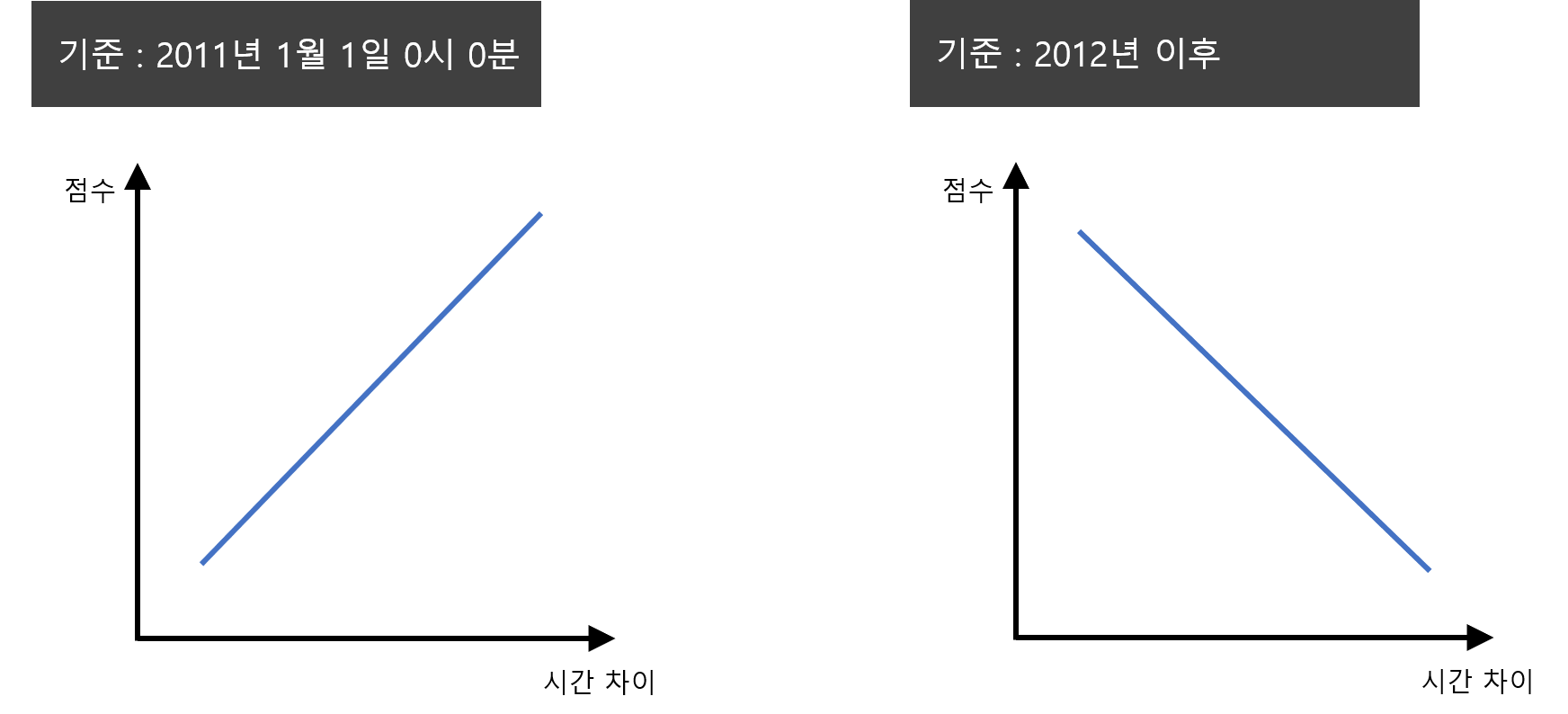
자 이해가 되었으리라 믿고 아래의 코드를 추가해주세요.
## 데이터 변환
current_day = pd.to_datetime('20110101') ## 기준 날짜를 2011년 1월 1일 0시 0분으로 잡았다.
time_diff = rfm_df['Recency']-current_day ## 최근방문일과 기준 날짜의 시간 차이
time_in_seconds = [x.total_seconds() for x in time_diff] ## 시간 차이를 초단위로 계산
rfm_df['Recency'] = time_in_seconds ## 변환된 데이터를 다시 삽입한다.
이제 데이터가 모두 숫자로 잘 나왔습니다~짝짝!!
이제 거의 다 왔어요~

이제 이번 포스팅의 핵심 함수인 get_score와 get_rfm_grade함수를 이용할 거예요. 이 함수는 아래와 같아요.
def get_score(level, data):
'''
Description :
level안에 있는 원소를 기준으로
1 ~ len(level)+ 1 까지 점수를 부여하는 함수
Parameters :
level = 튜플 또는 리스트 타입의 숫자형 데이터이며 반드시 오름차순으로 정렬되어 있어야함.
예 - [1,2,3,4,5] O, [5,4,3,2,1] X, [1,3,2,10,4] X
data = 점수를 부여할 데이터. 순회가능한(iterable) 데이터 형식
return :
점수를 담고 있는 리스트 반환
'''
score = []
for j in range(len(data)):
for i in range(len(level)):
if data[j] <= level[i]:
score.append(i+1)
break
elif data[j] > max(level):
score.append(len(level)+1)
break
else:
continue
return score
def get_rfm_grade(df, num_class, rfm_tick_point, rfm_col_map, suffix=None):
'''
Description :
개별 고객에 대한 최근방문일/방문횟수/구매금액 데이터가 주어졌을때
최근방문일/방문횟수/구매금액 점수를 계산하여 주어진 데이터 오른쪽에 붙여줍니다.
Parameters :
df = pandas.DataFrame 데이터
num_class = 등급(점수) 개수
rfm_tick_point = 최근방문일/방문횟수/구매금액에 대해서 등급을 나눌 기준이 되는 값
'quantile', 'min_max' 또는 리스트를 통하여 직접 값을 정할 수 있음.
단, 리스트 사용시 원소의 개수는 반드시 num_class - 1 이어야함.
quatile = 데이터의 분위수를 기준으로 점수를 매김
min_max = 데이터의 최소값과 최대값을 동일 간격으로 나누어 점수를 매김
rfm_col_map = 최근방문일/방문횟수/구매금액에 대응하는 칼럼명
예 - {'R':'Recency','F':'Frequency','M':'Monetary'}
suffix = 최근방문일/방문횟수/구매금액에 대응하는 칼럼명 뒤에 붙는 접미사
Return :
pandas.DataFrame
'''
##### 필요모듈 체크
import pandas as pd
import numpy as np
from sklearn import preprocessing
##### 파라미터 체크
if not isinstance(df, pd.DataFrame): ## 데이터는 pd.DataFrame이어야 함.
print('데이터는 pandas.DataFrame 객체여야 합니다.')
return
if isinstance(rfm_tick_point, dict) == False or isinstance(rfm_col_map, dict) == False: ## rfm_tick_point와 rfm_col_map은 모두 딕셔너리
print(f'rfm_tick_point와 rfm_col_map은 모두 딕셔너리여야합니다.')
return
if len(rfm_col_map) != 3: ## rfm_col_map에는 반드시 3개의 키를 가져아함.
print(f'rfm_col_map인자는 반드시 3개의 키를 가져야합니다. \n현재 rfm_col_map에는 {len(rfm_col_map)}개의 키가 있습니다.')
return
if len(rfm_tick_point) != 3: ## rfm_tick_point에는 반드시 3개의 키를 가져아함.
print(f'rfm_tick_point인자는 반드시 3개의 키를 가져야합니다. \n현재 rfm_col_map에는 {len(rfm_col_map)}개의 키가 있습니다.')
return
if set(rfm_tick_point.keys()) != set(rfm_col_map.keys()): ## rfm_tick_point와 rfm_col_map은 같은 키를 가져야함.
print(f'rfm_tick_point와 rfm_col_map은 같은 키를 가져야 합니다.')
return
if not set(rfm_col_map.values()).issubset(set(df.columns)):
not_in_df = set(rfm_col_map.values())-set(df.columns)
print(f'{not_in_df}이 데이터 칼럼에 있어야 합니다.')
return
for k, v in rfm_tick_point.items():
if isinstance(v, str):
if not v in ['quantile','min_max']:
print(f'{k}의 값은 "quantile" 또는 "min_max"중에 하나여야 합니다.')
return
elif isinstance(v,list) or isinstance(v,tuple):
if len(v) != num_class-1:
print(f'{k}에 대응하는 리스트(튜플)의 원소는 {num_class-1}개여야 합니다.')
return
if suffix:
if not isinstance(suffix, str):
print('suffix인자는 문자열이어야합니다.')
return
##### 최근방문일/방문횟수/구매금액 점수 부여
for k, v in rfm_tick_point.items():
if isinstance(v,str):
if v == 'quantile':
## 데이터 변환
scale = preprocessing.StandardScaler() ## 데이터의 범위 조작하기 쉽게 해주는 클래스
temp_data = np.array(df[rfm_col_map[k]]) ## 데이터를 Numpy 배열로 변환
temp_data = temp_data.reshape((-1,1)) ## scale을 적용하기위해 1차원 배열을 2차원으로 변환
temp_data = scale.fit_transform(temp_data) ## 데이터를 평균은 0, 표준편차는 1을 갖도록 변환
temp_data = temp_data.squeeze() ## 데이터를 다시 1차원으로 변환
## 분위수 벡터
quantiles_level = np.linspace(0,1,num_class+1)[1:-1] ## 분위수를 구할 기준값을 지정 0과 1은 제외
quantiles = [] ## 분위수를 담을 리스트
for ql in quantiles_level:
quantiles.append(np.quantile(temp_data,ql)) ## 분위수를 계산하고 리스트에 삽입
else: ## min_max인 경우
## 데이터 변환
temp_data = np.array(df[rfm_col_map[k]])
## 등분점 계산
quantiles = np.linspace(np.min(temp_data),np.max(temp_data),num_class+1)[1:-1] ## 최소값과 최대값을 점수 개수만큼 등간격으로 분할하는 점
else: ## 직접 구분값을 넣어주는 경우
temp_data = np.array(df[rfm_col_map[k]])
quantiles = v ## 직접 구분값을 넣어줌
score = get_score(quantiles, temp_data) ## 구분값을 기준으로 점수를 부여하고 리스트로 저장한다.
new_col_name = rfm_col_map[k]+'_'+k ## 점수값을 담는 변수의 이름
if suffix:
new_col_name = rfm_col_map[k]+'_'+suffix
df[new_col_name] = score ## 기존데이터 옆에 점수 데이터를 추가한다.
return df이 함수의 사용법을 알려드리고 코드 설명은 함수 내 주석으로 대체할게요
(제가 만든 거지만 너무 길어요 ㅠ.ㅠ).
get_score함수는 주어진 기준에 따라 데이터에 점수를 매겨주는 함수입니다.
예를 들어 학생 5명의 수학 점수가 각각 100점, 85점, 70점, 60점, 55점이라고 하고 85점보다 높으면 3점, 55점보다 높으면 2점 마지막으로 55점 이하면 1점을 준다고 가정해보겠습니다.
그러면 get_score를 이용하여 다음과 같이 점수를 얻을 수 있습니다.
get_score([55, 85],[100, 85, 70, 60, 55])
즉, 100점 맞은 학생은 3점, 55점 맞은 학생은 1점 나머지는 2점이 되지요.
get_rfm_grade함수는 주어진 데이터를 이용하여 고객별로 최근 방문일, 방문 횟수, 구매금액 점수를 구해주는 함수이지요. 여기서 다음과 같은 궁금증이 생길 수 있어요.

꽁냥이는 점수를 부여하는 방법으로 대해서 1)분위수를 이용하는 방법, 2)최소값과 최대값을 이용하는 방법 마지막으로 3)직접 기준값을 정하는 방법을 고려했습니다.
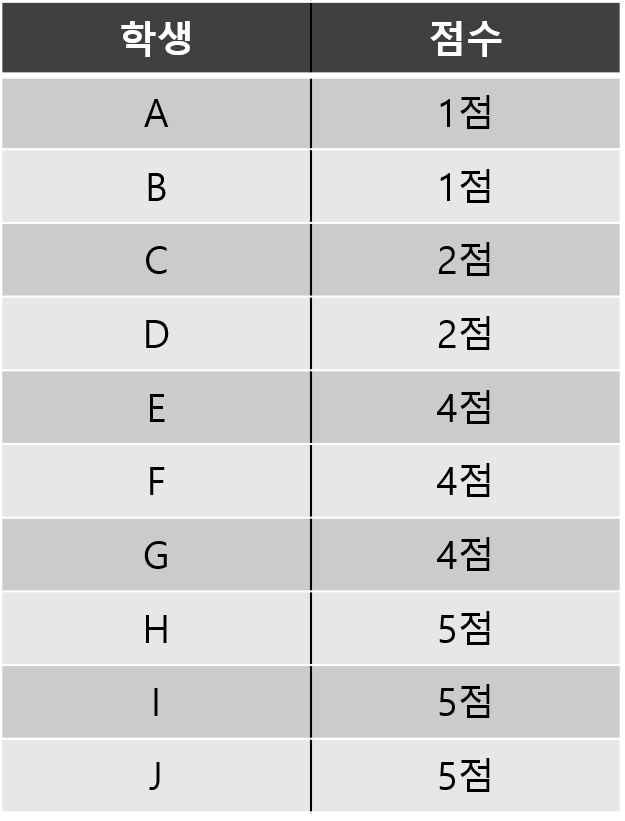
예를 들어 10명의 학생의 통계 점수가 다음과 같다고 해볼게요.

위의 학생들을 다음 3가지 방법에 따라 1점부터 5점까지 부여해보겠습니다.
1) 분위수를 이용하는 방법
분위수를 이용하는 방법은 데이터에 아주 작은 값 또는 아주 큰 값에 영향을 받지 않고 각 구간에 일정한 비율로 데이터가 포함될 수 있게 해주는 방법이에요(꽁냥이는 구간별 일정한 비율로 데이터가 포함되게 했지만 각 구간별로 비율을 다르게 줄 수도 있어요).
여기서는 1점부터 5점까지를 줘야 하니 5개의 구간을 정해야 합니다. 따라서 상위 20%, 상위 20~40%,... , 하위 20%를 나누는 지점을 찾고, 그 지점을 기준으로 점수를 부여하는 것이죠. 아래 그림을 보시면 이해하는데 도움이 될 거예요.

나누는 지점은 아래의 코드를 실행해서 찾을 수 있어요.
import numpy as np
data = [30, 40, 53, 55, 70, 79, 81, 83, 89, 95]
for x in np.linspace(0,1,6)[1:-1]:
print(f'분위수 : {np.quantile(data,x):.1f}')
이 방법에 의하면 학생들은 다음과 같이 점수를 매길 수 있습니다.

2) 최소값과 최대값을 이용하는 방법
이 방법은 데이터의 구간을 최소값과 최대값을 이용하여 동일 간격으로 분할하고 각 구간별로 점수를 주는 것이에요. 아래 그림을 보시면 이해할 수 있을 거예요.

나누는 지점은 아래의 코드를 실행하면 구할 수 있어요.
import numpy as np
data = [30, 40, 53, 55, 70, 79, 81, 83, 89, 95]
for x in np.linspace(np.min(data),np.max(data),6)[1:-1]:
print(f'구분값 : {x:.1f}')
이 방법에 의하면 학생들은 다음과 같이 점수를 매길 수 있습니다.
분위수를 이용해서 구한 점수와 다르다는 것을 확인하세요~
3) 직접 기준값을 정하는 방법
이 방법은 말 그대로 기준 값을 직접 정하는 방법이에요. 만약 기준 값을 40, 60, 75, 85라고 한다면 각 구간과 그에 대응하는 점수는 아래와 같을 거예요.

이 방법에 의하면 학생들은 다음과 같이 점수를 매길 수 있습니다.

여기서 또 다음과 같은 질문을 할 수 있습니다.

우리가 자주 사용하는 분위수는 중앙값과 4분위수가 있는데요. 분위수는 아주 크거나 작은 값에 영향을 덜 받는 것으로 아주 잘알려져있죠. 따라서 만약 데이터에 압도적으로 크거나 작은 값이 있다면 분위수를 이용하여 점수를 매기는 것을 고려해보세요.
하지만 분위수는 각 구간에 해당하는 값의 크기를 반영하지 못해요. 극단적인 예로 구매금액이 0원인 사람과 10만원인 고객이 같은 구간, 즉 같은 점수를 얻게 될 수 있지요. 따라서 값의 크기가 중요하다고 판단되는 경우에는 최소값, 최대값을 이용하는 방법 또한 고려해보세요.
그리고 이산형 변수 같은 경우 동일한 값을 어떻게 처리하느냐에 따라 같은 값이라도 다른 구간에 속해있을 수 있어요. 예를 들면, 고객 4명의 방문 횟수가 아래와 같다고 해볼게요.

위와 같은 상황에서 1점, 2점을 줘야 하고 분위수를 이용한다면 A와 B는 1점, C와 D는 2점이 될 수 있어요. B와 C는 같은 방문 횟수이지만 서로 다른 점수를 받게 되는 상황인 것이지요.
이러한 경우에는 기준 값을 1.5로 잡아서 A는 1점, B, C, D는 2점을 주거나 기준값을 3으로 잡아서 A, B, C를 1점, D를 2점으로 주는 것이 합리적일 거예요.
이처럼 이산형 변수를 다룰 때는 기준 값을 직접 정해보는 것도 하나의 방법이에요. 이때 데이터의 분포를 시각화해서 살펴보면 기준값을 정하는데 많은 도움이 될 거예요.
드디어 마지막입니다!!
get_rfm_grade함수를 이용하여 고객별로 최근 방문일/방문 횟수/구매금액 점수를 구해보겠습니다.
아래의 코드를 실행해보세요.
rfm_tick_point={'R':'quantile','F':'quantile','M':'quantile'}
rfm_col_map={'R':'Recency','F':'Frequency','M':'Monetary'}
result = get_rfm_grade(df=rfm_df, num_class=5, rfm_tick_point=rfm_tick_point, rfm_col_map=rfm_col_map)
result.to_csv('result.csv',index=False)line 1
rfm_tick_point는 최근 방문일/방문 횟수/구매금액에 대하여 어떤 방법으로 점수를 매길지를 결정하는 인자입니다. 여기서, 'R', 'F', 'M'은 각각 최근 방문일/방문 횟수/구매금액을 의미하며 위에서 말한 3가지 방법을 지정할 수 있습니다. 우선은 세 개 모두 분위수를 이용한 방법을 지정했습니다.
line 2
그리고 get_rfm_grade함수에 데이터에서 최근 방문일/방문 횟수/구매금액에 해당하는 변수가 무엇인지 알려줘야 합니다. 현재 데이터상에서 최근방문일/방문횟수/구매금액에 해당하는 변수는 각각 Recency, Frequency, Monetary이므로 이 값을 rfm_col_map인자에 넣어 줍니다.
line 4
get_rfm_grade 함수를 실행하여 최근방문일/방문횟수/구매금액 점수를 구합니다. 여기서는 1점부터 5점까지 주기 위해 num_class인자에 5를 넣었습니다.
line 5
데이터를 저장해줍니다. 왜냐하면 다음 포스팅에서 필요해요~
이제 분석 결과를 볼까요? 아래의 코드를 실행해보세요.
result[['CustomerID','Recency_R','Frequency_F','Monetary_M']]
데이터 분석 목표에서 말한 것처럼 고객별로 최근 방문일/방문 횟수/구매금액 점수가 잘 나온 것을 확인할 수 있습니다.
아래 코드를 보시고 점수를 구하는 3가지 방법을 다양하게 적용해보세요.
최소값과 최대값을 이용하는 방법
rfm_tick_point={'R':'quantile','F':'quantile','M':'min_max'} ## 구매금액에 최소값 최대값을 이용한 방법 적용
rfm_col_map={'R':'Recency','F':'Frequency','M':'Monetary'}
result = get_rfm_grade(df=rfm_df, num_class=5, rfm_tick_point=rfm_tick_point, rfm_col_map=rfm_col_map)
result[['CustomerID','Recency_R','Frequency_F','Monetary_M']]직접 기준값을 정하는 방법
rfm_tick_point={'R':'quantile','F':[5, 10, 50, 90],'M':'quantile'} ## 방문 횟수에 직접 기준값을 정하는 방법 적용
rfm_col_map={'R':'Recency','F':'Frequency','M':'Monetary'}
result = get_rfm_grade(df=rfm_df, num_class=5, rfm_tick_point=rfm_tick_point, rfm_col_map=rfm_col_map)
result[['CustomerID','Recency_R','Frequency_F','Monetary_M']]
지금까지 RFM 분석 과정을 데이터 살펴보는 것에서부터 실제 점수를 부여하는 과정까지 알아보았습니다.
여기가지 오시느라 수고하셨고요(내용을 최대한 줄여본다고 했는데도 길어졌어요 ㅠ.ㅠ).
소스코드는 첨부할테니 필요하신 분들은 쓰시면 되세요~.
궁금한 점이나 잘못된 내용 또는 그 밖에 하고 싶은 말은 댓글로 남겨주세요.
다음 포스팅에서는 RFM 분석에서 가중치를 이용하여 고객에게 점수를 부여하는 과정에 대해서 소개하겠습니다. 많이 기대해주세요. 지금까지 꽁냥이의 긴글 읽어주셔서 감사합니다.

이번 포스팅에서 참고한 자료는 다음과 같습니다.
Recency, Frequency, Monetary Model with Python :
Recency, Frequency, Monetary Model with Python — and how Sephora uses it to optimize their Google…
The last time we analyzed our online shopper date set using the cohort analysis method. We discovered some interesting observations around…
towardsdatascience.com
KAGGLE - Customer Segmentation :
Customer Segmentation
Explore and run machine learning code with Kaggle Notebooks | Using data from E-Commerce Data
www.kaggle.com
'데이터 분석 > 데이터 분석' 카테고리의 다른 글
| [A/B 테스트] 2. A/B 테스트 사례에 대하여 알아볼까요?! (0) | 2020.08.09 |
|---|---|
| [A/B 테스트] 1. A/B 테스트란 무엇일까요? (0) | 2020.07.24 |
| [RFM 고객 분석] 3. Python을 이용한 RFM 분석 - RFM 가중치 계산 (420) | 2020.06.28 |
| [RFM 고객 분석] 1. RFM 고객 분석이 무엇일까요? (2182) | 2020.06.15 |
| [프롤로그] 들어가는 글 (0) | 2020.06.08 |





댓글