이 포스팅은 꽁냥이가 병렬 프로그래밍 공부한 내용을 포스팅하는 곳입니다.
지난 포스팅에서는 파이썬(Python)으로 멀티 프로세스(Multi Process)를 사용하는 방법과 이를 언제 사용하면 좋은지에 대해서 알아봤다.
[병렬 프로그래밍] 3. Multi-Process 사용하기 with Python
이번 포스팅에서는 멀티 프로세스를 이용하여 시간을 단출시킬 수 있는 (실제 쓰일 법한) 예제를 알아보려고 한다. Corey Schafer 님의 Python Tutorial Multi Processing 영상을 참고했다.
여기서 다루는 내용은 다음과 같다.
1. 이미지 처리
여기서는 꽤 용량이 있는 이미지의 처리를 멀티 프로세스를 사용하지 않는 경우와 사용하는 경우에 시간 절감 효과가 어떻게 되는지 확인해볼 것이다.
먼저 이미지를 여기에서 jpg 파일을 하나씩 다운받거나 본인이 처리하고 싶은 이미지를 준비해놓자(원래는 파일을 첨부하려고 했지만 10메가 밖에 못 올려서 첨부하지 못했다 ㅠ.ㅠ). 아래 코드는 각 이미지마다 가우시안 필터를 적용하고 이미지 사이즈를 변경하는 코드이다.
import time import concurrent.futures import os from PIL import Image, ImageFilter img_names = [ 'photo-1516117172878-fd2c41f4a759.jpg', 'photo-1532009324734-20a7a5813719.jpg', 'photo-1524429656589-6633a470097c.jpg', 'photo-1530224264768-7ff8c1789d79.jpg', 'photo-1564135624576-c5c88640f235.jpg', 'photo-1541698444083-023c97d3f4b6.jpg', 'photo-1522364723953-452d3431c267.jpg', 'photo-1513938709626-033611b8cc03.jpg', 'photo-1507143550189-fed454f93097.jpg', 'photo-1493976040374-85c8e12f0c0e.jpg', 'photo-1504198453319-5ce911bafcde.jpg', 'photo-1530122037265-a5f1f91d3b99.jpg', 'photo-1516972810927-80185027ca84.jpg', 'photo-1550439062-609e1531270e.jpg', 'photo-1549692520-acc6669e2f0c.jpg' ] size = (1200, 1200) img_dir = './images' save_processed_img_dir = './processed_image' if not os.path.exists(save_processed_img_dir): os.makedirs(save_processed_img_dir) if __name__ == '__main__': start = time.perf_counter() for img_name in img_names: img_path = os.path.join(img_dir,img_name) img = Image.open(img_path) img = img.filter(ImageFilter.GaussianBlur(15)) img.thumbnail(size) img.save(os.path.join(save_processed_img_dir,img_name)) print(f'{img_name} was processed...') finish = time.perf_counter() print(f'Finished in {finish-start} seconds')

위 코드를 실행했더니 약 13초가 걸렸다. 이번엔 멀티 프로세스를 적용하여 위 작업을 수행해보자. 이미지 전처리는 CPU 작업이므로 멀티 프로세스의 효과를 볼 수 있을 것이다.
import time import concurrent.futures import os from PIL import Image, ImageFilter img_names = [ 'photo-1516117172878-fd2c41f4a759.jpg', 'photo-1532009324734-20a7a5813719.jpg', 'photo-1524429656589-6633a470097c.jpg', 'photo-1530224264768-7ff8c1789d79.jpg', 'photo-1564135624576-c5c88640f235.jpg', 'photo-1541698444083-023c97d3f4b6.jpg', 'photo-1522364723953-452d3431c267.jpg', 'photo-1513938709626-033611b8cc03.jpg', 'photo-1507143550189-fed454f93097.jpg', 'photo-1493976040374-85c8e12f0c0e.jpg', 'photo-1504198453319-5ce911bafcde.jpg', 'photo-1530122037265-a5f1f91d3b99.jpg', 'photo-1516972810927-80185027ca84.jpg', 'photo-1550439062-609e1531270e.jpg', 'photo-1549692520-acc6669e2f0c.jpg' ] size = (1200, 1200) img_dir = './images' save_processed_img_dir = './processed_image' if not os.path.exists(save_processed_img_dir): os.makedirs(save_processed_img_dir) def process_image(img_name): img_path = os.path.join(img_dir,img_name) img = Image.open(img_path) img = img.filter(ImageFilter.GaussianBlur(15)) img.thumbnail(size) img.save(os.path.join(save_processed_img_dir,img_name)) print(f'{img_name} was processed...') if __name__ == '__main__': start = time.perf_counter() with concurrent.futures.ProcessPoolExecutor() as executor: executor.map(process_image, img_names) finish = time.perf_counter() print(f'Finished in {finish-start} seconds')
line 45~46
멀티 프로세스를 사용하기 위하여 concurrent.future.ProcessPoolExecutor 클래스의 인스턴스 executor를 만들어준 뒤 map 메서드 인자에 해야 할 작업(함수)과 인자를 리스트로 넘겨주었다.
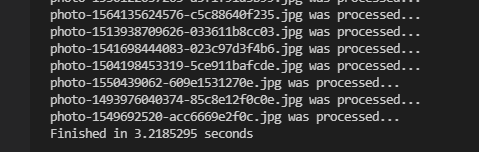
위 코드를 실행하면 약 3초가 걸리는 것을 알 수 있다. 이는 멀티 프로세스를 사용하지 않았을 때보다 약 4배 정도 빨라졌다.
2. csv 파일 저장
이번엔 지난 포스팅에서 멀티 쓰레드를 이용해도 효과를 보지 못했던 csv 파일 읽기/쓰기 예제를 멀티 프로세스로 처리하는 경우 시간 절감 효과가 있는지 확인해보고자 한다. 먼저 이번 예제에서 사용할 csv 파일을 만들어보자. 각 csv 파일은 10개 칼럼, 200,000개 행을 갖는 정규분포 난수로 이루어져 있다.
import pandas as pd import numpy as np import os import time def generate_df(size): df = pd.DataFrame() for x in list('abcdefghi'): df[x] = np.random.normal(size=size) return df if __name__ == '__main__': csv_dir = './csv' if not os.path.exists(csv_dir): os.makedirs(csv_dir) num_df = 30 size = 200000 dfs = [] for i in range(num_df): dfs.append(generate_df(size)) start = time.perf_counter() for i, df in enumerate(dfs): csv_file_name = str(i)+'.csv' csv_file_path = os.path.join(csv_dir,csv_file_name) df.to_csv(csv_file_path) print(f'CSV File {i}/{len(dfs)} saved...') finish = time.perf_counter() print(f'Finished in {round(finish-start, 2)} second(s)')
이렇게 만들어진 csv 파일들을 읽은 다음 처음 20번째 줄만 저장하는 간단한(하지만 별 의미 없는) 작업을 수행해보자. 먼저 멀티 프로세스를 사용하지 않고 작업을 수행해보자.
import os import time import concurrent.futures csv_dir = './csv' ## 읽을 csv 파일 디렉토리 csv_save_dir = './save_csv' ## 저장할 csv 파일 디렉토리 if not os.path.exists(csv_save_dir): os.makedirs(csv_save_dir) csv_files = os.listdir(csv_dir) if __name__ == '__main__': start = time.perf_counter() for csv_file in csv_files: csv_file_path = os.path.join(csv_dir,csv_file) with open(csv_file_path,'r') as f: lines = f.readlines() csv_file_save_path = os.path.join(csv_save_dir,'1_'+csv_file) with open(csv_file_save_path,'w') as f: f.writelines(lines[:20]) print(f'CSV File saved...') finish = time.perf_counter() print(f'Finished in {round(finish-start, 2)} second(s)')
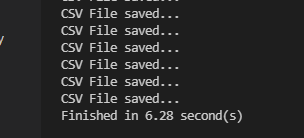
위 코드를 수행하면 약 6초 정도 걸리는 것을 알 수 있다. 이제 멀티 프로세스를 이용하여 위 작업을 수행해보자.
import os import time import concurrent.futures csv_dir = './csv' ## 읽을 csv 파일 디렉토리 csv_save_dir = './save_csv' ## 저장할 csv 파일 디렉토리 if not os.path.exists(csv_save_dir): os.makedirs(csv_save_dir) csv_files = os.listdir(csv_dir) def read_and_write_csv(csv_file): csv_file_path = os.path.join(csv_dir,csv_file) with open(csv_file_path,'r') as f: lines = f.readlines() csv_file_save_path = os.path.join(csv_save_dir,'1_'+csv_file) with open(csv_file_save_path,'w') as f: f.writelines(lines[:20]) print(f'CSV File saved...') if __name__ == '__main__': start = time.perf_counter() with concurrent.futures.ProcessPoolExecutor() as executor: executor.map(read_and_write_csv, [csv_file for csv_file in csv_files]) finish = time.perf_counter() print(f'Finished in {round(finish-start, 2)} second(s)')
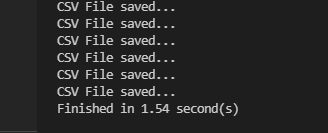
위 코드를 수행하면 약 1.5초가 걸리는 것을 알 수 있다. 기존 대비 약 4배 빨라졌음을 알 수 있다. 멀티 프로세스는 한 드라이브에 파일을 읽고 쓰는 작업에도 효과가 있음을 알 수 있다.
이번 포스팅에서는 멀티 프로세스(Multi Process)를 사용하여 실제 현업에서 사용할 수 있는 작업들을 수행해보았다. 멀티 프로세스를 잘 구현하는 것도 중요하지만 해당 작업이 멀티 프로세스로 효과가 있을 것인지 사전에 충분히 숙지하는 것도 중요하다.
아직 병렬 프로그래밍 관련 지식이 부족하여 포스팅 내용에 잘못된 부분이 있을 수 있다. 잘못된 부분에 대해서 알려주시면 정말 감사하다. 병렬 프로그래밍 마스터가 되고 싶다.
지금까지 꽁냥이의 글 읽어주셔서 감사합니다.

'프로그래밍 > Python' 카테고리의 다른 글
| [오류 해결] Pandas - query 실행 오류 "TypeError: 'Series' objects are mutable, thus they cannot be hashed" (1295) | 2021.06.13 |
|---|---|
| [오류 해결] ExecutableNotFound: failed to execute ['dot', '-Kdot', '-Tsvg'], make sure the Graphviz executables are on your systems' PATH (1497) | 2021.06.02 |
| [병렬 프로그래밍] 3. Multi-Process 사용하기 with Python (1481) | 2021.05.16 |
| [병렬 프로그래밍] 2. Multi-Thread 응용 with Python (1123) | 2021.05.15 |
| [병렬 프로그래밍] 1. Multi-Thread 사용하기 with Python (2510) | 2021.05.13 |





댓글