이 포스팅은 꽁냥이가 병렬 프로그래밍 공부한 내용을 포스팅하는 곳입니다.
저번 포스팅에서는 파이썬으로 멀티 쓰레드(Multi Thread)를 사용하는 방법과 언제 사용해야 하는지에 대해서 알아보았다.
[병렬 프로그래밍] 1. Multi-Thread 사용하기 with Python
이번 포스팅에서는 좀 더 그럴듯한(?) 작업을 멀티 쓰레드(Multi Thread)를 이용하여 시간을 단축시킬 수 있는 예제와 그럴 수 없는 예제를 보여주려고 한다. 이번 포스팅 또한 Corey Schafer 님의 Python Threading Tutorial 영상을 (아주 아주 많이) 참고했다.
여기서 다루는 내용은 다음과 같다.
2. 멀티 쓰레드 효과가 없는 경우 - csv 파일 저장
1. 이미지 다운로드
여기서 사용할 이미지는 Corey Schafer 님의 Python Threading Tutorial에서 가져온 15장의 이미지를 사용한다. Corey Schafer 님이 말씀하시길 각 이미지는 고해상도의 이미지라고 한다. 따라서 한 장을 다운받는데에도 시간이 은근히 걸린다. 아래 코드는 멀티 쓰레드를 사용하지 않고 이미지를 다운받는 코드이다.
import time import os import requests img_urls = [ 'https://images.unsplash.com/photo-1516117172878-fd2c41f4a759', 'https://images.unsplash.com/photo-1532009324734-20a7a5813719', 'https://images.unsplash.com/photo-1524429656589-6633a470097c', 'https://images.unsplash.com/photo-1530224264768-7ff8c1789d79', 'https://images.unsplash.com/photo-1564135624576-c5c88640f235', 'https://images.unsplash.com/photo-1541698444083-023c97d3f4b6', 'https://images.unsplash.com/photo-1522364723953-452d3431c267', 'https://images.unsplash.com/photo-1513938709626-033611b8cc03', 'https://images.unsplash.com/photo-1507143550189-fed454f93097', 'https://images.unsplash.com/photo-1493976040374-85c8e12f0c0e', 'https://images.unsplash.com/photo-1504198453319-5ce911bafcde', 'https://images.unsplash.com/photo-1530122037265-a5f1f91d3b99', 'https://images.unsplash.com/photo-1516972810927-80185027ca84', 'https://images.unsplash.com/photo-1550439062-609e1531270e', 'https://images.unsplash.com/photo-1549692520-acc6669e2f0c' ] if __name__ == '__main__': start = time.perf_counter() save_file_dir = './images' if not os.path.exists(save_file_dir): os.makedirs(save_file_dir) for img_url in img_urls: img_bytes = requests.get(img_url).content img_name = img_url.split('/')[3] img_path = os.path.join(save_file_dir,f'{img_name}.jpg') with open(img_path, 'wb') as img_file: img_file.write(img_bytes) print(f'{img_name} was downloaded...') finish = time.perf_counter() print(f'Finished in {round(finish-start, 2)} second(s)')
line 3
requests 모듈을 임포트한다. 이는 이미지 url에서 이미지를 가져오기 위해 필요하다.
line 5~21
15장의 이미지 url을 담고 있는 리스트이다.
line 26~28
이미지를 저장할 폴더가 이미 있다면 패스하고 없다면 만들어준다.
line 31~33
requests.get 메서드에 이미지 url을 인자로 넣고 content를 이용하여 이미지 바이트 코드를 읽어온다(line 31). 그리고 이미지 이름(line 32)과 이미지를 저장할 경로(line 33)를 만들어준다.
line 35~36
이미지 파일을 저장한다.
위 코드를 실행해보자.

20.72초가 걸렸다. ㄷㄷ;;
이번엔 멀티 쓰레드를 이용하여 이미지를 다운받아보자. 아래 코드를 살펴보자.
import time import os import requests import concurrent.futures img_urls = [ 'https://images.unsplash.com/photo-1516117172878-fd2c41f4a759', 'https://images.unsplash.com/photo-1532009324734-20a7a5813719', 'https://images.unsplash.com/photo-1524429656589-6633a470097c', 'https://images.unsplash.com/photo-1530224264768-7ff8c1789d79', 'https://images.unsplash.com/photo-1564135624576-c5c88640f235', 'https://images.unsplash.com/photo-1541698444083-023c97d3f4b6', 'https://images.unsplash.com/photo-1522364723953-452d3431c267', 'https://images.unsplash.com/photo-1513938709626-033611b8cc03', 'https://images.unsplash.com/photo-1507143550189-fed454f93097', 'https://images.unsplash.com/photo-1493976040374-85c8e12f0c0e', 'https://images.unsplash.com/photo-1504198453319-5ce911bafcde', 'https://images.unsplash.com/photo-1530122037265-a5f1f91d3b99', 'https://images.unsplash.com/photo-1516972810927-80185027ca84', 'https://images.unsplash.com/photo-1550439062-609e1531270e', 'https://images.unsplash.com/photo-1549692520-acc6669e2f0c' ] def download_image(input_list): img_url = input_list[0] save_file_dir =input_list[1] img_bytes = requests.get(img_url).content img_name = img_url.split('/')[3] img_path = os.path.join(save_file_dir,f'{img_name}.jpg') with open(img_path, 'wb') as img_file: img_file.write(img_bytes) print(f'{img_name} was downloaded...') if __name__ == '__main__': start = time.perf_counter() save_file_dir = './images' if not os.path.exists(save_file_dir): os.makedirs(save_file_dir) with concurrent.futures.ThreadPoolExecutor(max_workers=20) as executor: executor.map(download_image, [[img_url,save_file_dir] for img_url in img_urls]) finish = time.perf_counter() print(f'Finished in {round(finish-start, 2)} second(s)')
line 24~33
이미지를 url로부터 가져오고 이를 저장하는 작업을 함수로 만들어 주었다.
line 42~43
ThreadPoolExecutor 클래스에 쓰레드 풀을 구성하는 스레드의 최대 개수를 20개로 설정해보았다. 그리고 map을 이용하여 지정된 함수에 리스트 인자를 받아서 반복 수행하게끔 해주었다.
위 코드를 실행해보자.
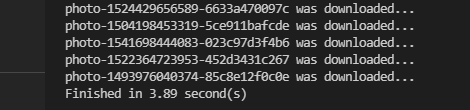
약 4초가 걸렸다. 멀티 쓰레드를 사용함으로써 기존 작업이 5배 정도 빨라진 것이다.
2. 멀티 쓰레드 효과가 없는 경우 csv 파일 저장
이번엔 여러개의 csv 파일을 읽고 각 csv 파일을 처리하여 다시 저장하는 상황을 생각해보자. 이런 작업은 데이터 분석하는 사람이라면 많이 접하는 경우일 것이다. 나 역시 이러한 상황을 많이 접했고 이번 기회에 속도를 개선하려고 병렬 프로그래밍을 공부한 것이다.
이번 예제에서 사용할 csv 파일은 만들어보자. 10개 열, 200,000개 행을 갖는 csv 파일을 30개 만들어 주었다.
import pandas as pd import numpy as np import os import time def generate_df(size): df = pd.DataFrame() for x in list('abcdefghi'): df[x] = np.random.normal(size=size) return df if __name__ == '__main__': csv_dir = './csv' if not os.path.exists(csv_dir): os.makedirs(csv_dir) num_df = 30 size = 200000 dfs = [] for i in range(num_df): dfs.append(generate_df(size)) start = time.perf_counter() for i, df in enumerate(dfs): csv_file_name = str(i)+'.csv' csv_file_path = os.path.join(csv_dir,csv_file_name) df.to_csv(csv_file_path) print(f'CSV File {i}/{len(dfs)} saved...') finish = time.perf_counter() print(f'Finished in {round(finish-start, 2)} second(s)')
이제 이 파일을 읽고 간단한(하지만 의미 없는) 작업을 거친 후 저장하는 작업을 해볼 것이다. 아래 코드는 멀티 스레드(Multi-Thread)를 사용하지 않고 해당 작업을 수행하는 코드이다.
import os import time csv_dir = './csv' ## 읽을 csv 파일 디렉토리 csv_save_dir = './save_csv' ## 저장할 csv 파일 디렉토리 csv_files = os.listdir(csv_dir) if __name__ == '__main__': if not os.path.exists(csv_save_dir): os.makedirs(csv_save_dir) start = time.perf_counter() for csv_file in csv_files: csv_file_path = os.path.join(csv_dir,csv_file) with open(csv_file_path,'r') as f: lines = f.readlines() csv_file_save_path = os.path.join(csv_save_dir,'1_'+csv_file) with open(csv_file_save_path,'w') as f: f.writelines(lines[:20]) print(f'CSV File saved...') finish = time.perf_counter() print(f'Finished in {round(finish-start, 2)} second(s)')
line 13~21
'csv' 디렉토리에 있는 모든 csv 파일에 대해서 각 파일을 읽은 후 전체 행에서 처음 20개 행만 뽑아서 다시 저장한다.
위 코드를 실행해보자.
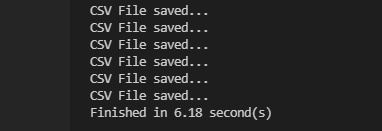
약 6초가 걸렸다. 이번엔 같은 작업을 멀티 쓰레드(Multi-Thread)를 이용하여 수행해보았다. 코드 설명은 이미지 다운로드 예제에서 살펴본 것과 거의 동일하므로 생략한다.
import os import time import concurrent.futures csv_dir = './csv' ## 읽을 csv 파일 디렉토리 csv_save_dir = './save_csv' ## 저장할 csv 파일 디렉토리 csv_files = os.listdir(csv_dir) def read_and_write_csv(csv_file): csv_file_path = os.path.join(csv_dir,csv_file) with open(csv_file_path,'r') as f: lines = f.readlines() csv_file_save_path = os.path.join(csv_save_dir,'1_'+csv_file) with open(csv_file_save_path,'w') as f: f.writelines(lines[:20]) print(f'CSV File saved...') if __name__ == '__main__': if not os.path.exists(csv_save_dir): os.makedirs(csv_save_dir) start = time.perf_counter() with concurrent.futures.ThreadPoolExecutor(max_workers=20) as executor: executor.map(read_and_write_csv, [csv_file for csv_file in csv_files]) finish = time.perf_counter() print(f'Finished in {round(finish-start, 2)} second(s)')
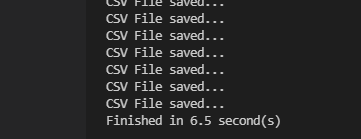
오잉? 멀티 쓰레드를 사용한 것이 오히려 시간이 (비록 얼마 되진 않지만) 더 걸렸다. 시간이 줄어들지 않는 이유는 파이썬 정책인 GIL(Global Interpreter Lock)으로 인하여 하나의 쓰레드가 하나의 드라이브에 읽고 저장할 동안 다른 쓰레드의 Lock을 걸었기 때문이다. 따라서 동시에 여러 쓰레드가 일을 할 수 없기 때문에 시간이 줄어들지 않은 것이다(파일 읽고 쓰는 것은 I/O 작업이 아닌 것 같다). 그리고 Lock을 걸고 해제하는 시간이 추가되어 멀티 쓰레드를 이용한 코드가 완료 시간이 더 길었던 것이다. 이런 경우엔 멀티 프로세싱(Multi Processing)을 이용하면 나아지려나? 한번 해봐야겠다.
아직 병렬 프로그래밍과 쓰레드 관련 지식이 부족하여 틀린 내용이 있을 수 있다. 혹시 틀린 내용이 있다면 알려주시면 정말 감사하다. 병렬 프로그래밍 마스터가 되고 싶다!!
'프로그래밍 > Python' 카테고리의 다른 글
| [병렬 프로그래밍] 4. Multi-Process 응용 with Python (1108) | 2021.05.17 |
|---|---|
| [병렬 프로그래밍] 3. Multi-Process 사용하기 with Python (1481) | 2021.05.16 |
| [병렬 프로그래밍] 1. Multi-Thread 사용하기 with Python (2510) | 2021.05.13 |
| [Python] 텍스트 파일 내용 수정하기 (1659) | 2021.04.24 |
| folium - popup, tooltip 한글 깨짐 현상 - 임시 방편 해결법! (0) | 2020.09.16 |





댓글