이 포스팅은 꽁냥이가 병렬 프로그래밍 공부한 내용을 포스팅하는 곳입니다.
요즘 들어 병렬 프로그래밍에 관심이 많아졌다. 특히 큰 용량의 데이터를 처리할 때 병렬 프로그래밍을 이용하면 더 빠른 속도로 전 처리할 수 있을 것만 같았다.
병렬 프로그래밍은 멀티 쓰레드(Multi-Thread)와 멀티 프로세스(Multi-Process)를 이용하여 구현할 수 있다고 한다. 이번 포스팅에서는 파이썬(Python)으로 멀티 쓰레드를 구현하는 방법에 대해서 살펴보려고 한다. 본 포스팅은 Corey Schafer 님의 유튜브 영상을 (아주 많이) 참고했다.
이번 포스팅에서 다루는 내용은 다음과 같다.
1. 예제
아래의 함수를 10번 실행한다고 생각해보자.
def do_something():
print('Sleeping 1 seconds')
time.sleep(1)
print('Done Sleeping...')
아래 코드는 do_something 함수를 10번 실행하는 코드이다(주피터 노트북으로는 이 코드를 실행하기 복잡하여 Visual Studio Code 또는 파이참에서 실행하려고 한다).
import time
def do_something():
print('Sleeping 1 seconds')
time.sleep(1)
print('Done Sleeping...')
if __name__ == '__main__':
start = time.perf_counter()
for _ in range(10):
do_something()
finish = time.perf_counter()
print(f'Finished in {round(finish-start, 2)} second(s)')
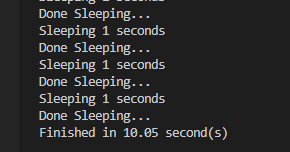
예상대로 약 10초가 걸렸다. 위 코드는 똑같은 작업을 10번 반복하는 코드이다. 만약 이 작업을 멀티 쓰레드로 처리하면 어떠한 효과가 나타날지 알아보자.
2. threading 모듈을 이용한 멀티 쓰레드
이번엔 위 코드를 멀티 쓰레드로 처리해보려고 한다. 여기서는 threading 모듈을 이용한다. 아래 코드를 살펴보자.
import time
import threading
def do_something():
print('Sleeping 1 seconds')
time.sleep(1)
print('Done Sleeping...')
if __name__ == '__main__':
start = time.perf_counter()
threads = []
for _ in range(10):
t = threading.Thread(target=do_something)
t.start()
threads.append(t)
for thread in threads:
thread.join()
finish = time.perf_counter()
print(f'Finished in {round(finish-start, 2)} second(s)')
line 1
threading 모듈을 임포트한다.
line 11~15
쓰레드를 담을 리스트 threads 를 초기화한다. 각 반복 스텝마다 쓰레드를 생성해준다. 쓰레드는 threading.Thread를 이용하여 생성할 수 있으며 이때 쓰레드가 실행할 함수를 target 인자에 넣어준다. 하지만 쓰레드가 생성되었다고 해서 함수는 실행 되지 않는다. 함수를 실행하기 위해서는 start를 이용한다. 그리고 각 쓰레드를 threads에 담아준다.
line 17~19
쓰레드를 실행한후 모든 쓰레드가 실행이 완료된 후 다음 코드를 실행시키기 위하여 join을 이용해준다.
위 코드를 실행해보자.
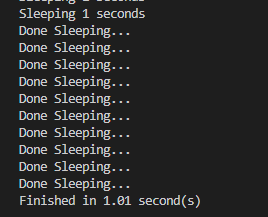
예제에서 살펴본 코드와 동일한 작업을 수행하지만 작업시간은 1초로 기존 대비 10배 빨라졌다. ㄷㄷ;;
3. concurrent 모듈 이용하기
threading 모듈을 이용하여 멀티 쓰레드를 구현하려고 하면 쓰레드마다 start와 join을 해주어야 한다. 귀찮은 일이다. 하지만 concurrent를 사용한다면 위와 같은 귀찮은 작업을 안 해도 된다. 아래 코드를 살펴보자.
import time
from concurrent import futures
def do_something():
print('Sleeping 1 seconds')
time.sleep(1)
return 'Done Sleeping...'
if __name__ == '__main__':
start = time.perf_counter()
with futures.ThreadPoolExecutor() as executor:
results = [executor.submit(do_something) for _ in range(10)]
for f in futures.as_completed(results):
print(f.result())
finish = time.perf_counter()
print(f'Finished in {round(finish-start, 2)} second(s)')
line 2
concurrent에서 futures를 임포트해준다.
line 7
함수의 리턴값을 모아둘 것이므로 print 대신 return으로 바꾸어 주었다.
line 12~13
with 문을 사용하여 futures.ThreadPoolExecutor 클래스의 인스턴스(executor)를 만들어준다. 이는 쓰레드 Pool을 만들어준 것이다. 다음으로 submit을 이용하여 쓰레드 Pool에 작업(함수)을 제출해야 한다. 여기서는 함수 do_something을 넣어준다. submit은 future라는 객체를 반환하는데 여기에는 작업이 제대로 됐는지에 대한 정보와 작업이 잘되었다면 그 결과를 반환할 수 있다.
line 15~16
result 메서드를 이용하여 결과를 반환한다.
위 코드를 실행해보자.
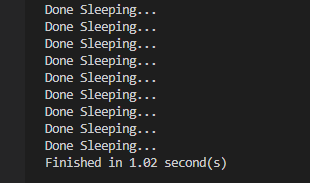
threading 모듈을 이용한 결과와 동일하다. 따라서 threading 모듈뿐 아니라 concurrent 모듈을 사용하는 것도 고려해보자.
4. 멀티 쓰레드는 언제 써야 할까?
이번엔 1부터 100,000,000까지의 합을 구하는 것을 생각해보자. 먼저 다이렉트로 계산해보자.
import time
from concurrent import futures
def cal_sum(input_list):
res = 0
for i in range(input_list[0], input_list[1]+1):
res += i
return res
if __name__ == '__main__':
start = time.perf_counter()
results = cal_sum([1,100000000])
print(results)
finish = time.perf_counter()
print(f'Finished in {round(finish-start, 2)} second(s)')

위에서 보는 바와 같이 4.4초가 걸린다. 이번엔 멀티 쓰레드를 이용해보자.
import time
from concurrent import futures
def cal_sum(input_list):
res = 0
for i in range(input_list[0], input_list[1]+1):
res += i
return res
if __name__ == '__main__':
start = time.perf_counter()
with futures.ThreadPoolExecutor() as executor:
sub_routine = [[1,100000000//2], [100000000//2+1,100000000]]
results = executor.map(cal_sum, sub_routine)
print(sum(results))
finish = time.perf_counter()
print(f'Finished in {round(finish-start, 2)} second(s)')
line 14~17
기존에 map 함수를 이용하여 리스트 연산이 가능했던 것처럼 ThreadPoolExecutor 클래스에 있는 map을 이용하여 일반적인 리스트 연산이 가능하다. 여기서는 2개 단위로 쪼개서 부분합을 구하고 이 부분합을 sum 함수를 이용하여 다시 합칠 것이다.
위 코드를 실행해보자.

오잉? 시간이 줄어들긴 했지만 작업 단위를 2개로 쪼갰으니 2배 줄어들 것 같았지만 실상은 그렇지 않았다.
아까는 작업 단위를 10개로 쪼개서 10배가 줄어들었는데 이번 예제에서는 왜 2배로 줄어들지 않을까? 그 이유는 파이썬 정책인 GIL(Global Interpreter Lock)으로 인하여 쓰레드 하나에 CPU 자원을 다 쓰기 때문이다. 따라서 작업 단위를 2개로 쪼개도 하나의 쓰레드가 합을 처리하는데 CPU를 자원을 다써서 이 쓰레드가 다끝나기 전에는 다른 쓰레드가 일을 할 수 없어서 시간 절감 효과가 크지 않았던 것이다.
그렇다면 do_something 예제에서는 왜 10배로 시간이 줄어들 수 있었을까? 이는 do_something 함수가 I/O(입출력) 작업이기 때문이다. 이는 I/O 작업은 CPU 작업이 아니라서 GIL의 영향을 받지 않는다. 따라서 멀티 쓰레드의 효과를 톡톡히 볼 수 있었다.
따라서 반복 작업이 I/O 작업(입 출력 또는 파일 쓰기, 파일 다운로드 등)으로 이루어져 있다면 멀티 쓰레드를 이용하여 성능을 개선할 수 있다. 파일 쓰기 같은 경우 I/O 작업이 아니라고 한다 ㅠ.ㅠ 그래서 용량이 큰 csv 파일을 멀티 쓰레드로 나눠서 저장하는 경우에는 멀티 쓰레드 효과를 볼 수 없다. 오히려 시간이 더 걸린다고 한다.
나도 병렬 프로그래밍에 대한 지식이 많이 없어서 틀린 내용이 있을 수 있다. 틀린 부분 있으면 알려주시면 정말 감사하겠다. 병렬 프로그래밍 마스터가 되고 싶다.
지금까지 꽁냥이의 글 읽어주셔서 감사합니다.

'프로그래밍 > Python' 카테고리의 다른 글
| [병렬 프로그래밍] 3. Multi-Process 사용하기 with Python (1481) | 2021.05.16 |
|---|---|
| [병렬 프로그래밍] 2. Multi-Thread 응용 with Python (1123) | 2021.05.15 |
| [Python] 텍스트 파일 내용 수정하기 (1659) | 2021.04.24 |
| folium - popup, tooltip 한글 깨짐 현상 - 임시 방편 해결법! (0) | 2020.09.16 |
| 파이썬 3에서 'Crypto' 모듈 설치하기 (2) | 2020.08.25 |





댓글