안녕하세요~ 꽁냥이에요. 데이터 전처리를 하다 보면 특정 열을 변환해야 할 때가 있지요. 예를 들어 회귀 모형을 구축할 때 설명 변수를 log 함수를 이용하여 변환하는 것처럼 말이죠. Pandas에서는 데이터 변환을 쉽게 해주는 강력한 기능을 제공하는데요. 그건 바로 이번 포스팅에서 다룰 apply 함수입니다. 여기서 다루는 내용은 다음과 같습니다.
1. apply 함수 기본 사용법
먼저 이번 포스팅에서 필요한 모듈을 임포트합니다.
import numpy as np import pandas as pd
다음으로 예제용 데이터를 만들어줍니다.
np.random.seed(10) n = 5 df = pd.DataFrame() df['A'] = np.random.rand(n) ## random sample from standard uniform distribution df['B'] = np.random.randn(n) ## random sample from standard normal distribution df['C'] = np.linspace(0,5,n)

A, B열에 있는 데이터는 꽁냥이와 다를 수 있어요.
apply함수 사용법은 다음과 같습니다.
apply( 함수, axis = 0 or 1 )
apply의 첫 번째인자는 적용하고자 할 함수 이름을 넣어주고요. axis 인자는 함수를 열로 적용할지 행으로 적용할지 정해주는 인자로 0은 열, 1은 행으로 적용됩니다. 기본값은 0입니다. 이제 코드를 통해 살펴볼까요?
먼저 제곱값을 구해주는 함수를 모든 열에 적용해보겠습니다.
## apply all columns df.apply(np.square)
이번엔 칼럼별 데이터의 합을 구해보겠습니다.
## apply all columns df.apply(np.sum)
칼럼별 데이터의 합을 구해보았으니 행별 데이터 합도 구해봐야겠죠?
## apply all rows df.apply(np.sum,axis=1)
2. apply 함수 응용
여기서는 실제 많이 써먹을 것 같은(?) apply 사용법을 살펴보겠습니다.
- 특정 열과 행에 함수 적용하기
지금까지는 전체 열, 행에 함수를 적용해보았는데요. 상황에 따라서 특정 열 또는 특정 행에 함수를 적용할 때가 있을 거예요. 이때에는 어떻게 하면 되는지 알아보겠습니다. 어렵지 않아요.
다음은 A, B열 데이터만 제곱값으로 변환하는 코드입니다.
## apply a specific column df.apply(lambda x:np.square(x) if x.name in ['A','B'] else x)
line 2
apply에서 적용할 함수는 기본적으로 Series 객체를 인자로 받습니다. 이 Series 객체에는 name이라는 필드가 있는데요. 이를 이용하여 특정 열에만 함수를 적용시킬 수 있습니다. 꽁냥이는 lambda를 이용하여 칼럼 이름이 A, B인 경우에만 함수를 적용하도록 했습니다. 그 외에 경우에는 반드시 else문을 써서 인자 x를 그대로 리턴하도록 해야 합니다.
보시는 바와 같이 A, B열에만 제곱값으로 변환되었습니다.
이를 응용하면 특정 행에도 함수를 적용할 수 있습니다. 이번엔 짝수번째 행만 제곱값으로 변환해보겠습니다.
# apply specific rows df.apply(lambda x:np.square(x) if (x.name+1)%2==0 else x,axis=1)
line 2
행 인덱스에 접근하면 특정 조건을 만족하는 행을 지정할 수 있습니다. 행 또한 Series 객체이며 행의 인덱스는 Series 객체의 name 필드를 이용하여 접근할 수 있습니다.
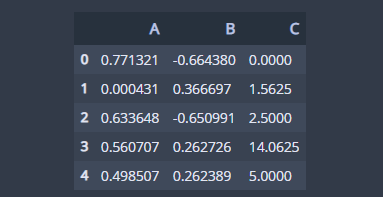
보시는 바와 같이 짝수번째 행에만 제곱값으로 변환된 것을 알 수 있습니다.
- 인자를 받는 함수 적용하기
지금까지 적용한 함수는 특별한 인자가 없었어요. 이번에는 인자를 포함하는 함수를 적용해볼 거예요.
다음은 모든 칼럼 데이터에 3을 곱하고 1을 더해주는 함수를 적용할 거예요.
## apply func need arguments def col_sum(x,a,b): return a*x+b df.apply(col_sum, args=(3,1))
line 2~3
먼저 x에 a를 곱하고 b를 더해주는 함수를 정의합니다. 여기서 x는 apply에서 Series 객체를 받게 됩니다.
line 4
apply의 args인자에 정의한 함수의 인자를 순서대로 넣어준 튜플을 넘겨줍니다.
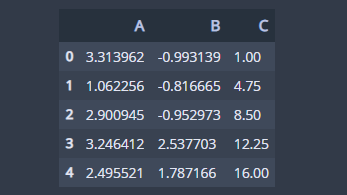
함수의 인자를 넣는 방법은 키워드 인자 또는 lambda를 사용할 수도 있습니다. 아래의 코드들은 위와 동일한 결과를 출력합니다.
arg_dict = {'a':3,'b':1} df.apply(col_sum, **arg_dict)
df.apply(lambda x: col_sum(x,3,1))- 특정 조건에 맞는 행에 함수 적용하기
이번엔 특정 조건에 맞는 행에 함수를 적용해볼거예요. 다음 코드는 B열 데이터가 양수일 때 A열에는 제곱값, B열에는 로그값을 취하는 코드입니다. B여려 데이터가 양수인 행은 4~5번째 행이므로 2개의 행만 함수가 적용될 것입니다.
## apply specific rows df.apply(lambda x:(np.square(x['A']),np.log(x['B']),x['C']) if x['B']>0 else x, axis=1)
line 2
행별로 적용할 것이기 때문에 axis=1로 설정하였습니다. 또한 각 행에 대하여 A열에는 제곱값을, B열에는 로그값을 구하는 함수를 적용했고요. C열은 그대로 가져왔습니다. lambda를 이용했을 때 리턴값은 열의 개수를 갖는 튜플 혹은 리스트로 반환되어야 합니다.
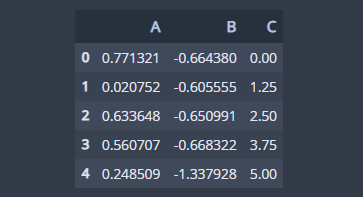
보시는 바와 같이 4~5번째 행에 함수가 적용되었습니다.
이번 포스팅에서는 데이터 변환하는데 유용한 apply 함수의 사용법을 알아보았습니다. 오늘 배운 정도만 알아도 웬만한 데이터 변환은 다할 수 있을 거예요.
지금까지 꽁냥이의 글 읽어주셔서 감사합니다. 다음 포스팅에서도 좋은 내용으로 찾아뵐게요~! 안녕히 계세요.

'데이터 분석 > 데이터 전처리' 카테고리의 다른 글
| [Pandas] 18. 두 날짜 사이의 날짜 생성하기. (0) | 2021.02.22 |
|---|---|
| [Pandas] 17. 범주형 데이터 가변수/더미 변수(dummy variable)로 바꾸기 (0) | 2021.01.19 |
| [Pandas] 15. 결측치(Missing Value) 처리하기 (0) | 2020.12.02 |
| [Pandas] 14. 데이터 그룹별로 집계하기 (5) | 2020.11.24 |
| [Pandas] 13. 날짜를 이용하여 데이터 조회하기 (0) | 2020.11.21 |





댓글