안녕하세요~ 꽁냥이에요.
데이터를 분석하다 보면 그룹별로 집계하여 데이터를 요약해야 할 일이 많이 있지요. 예를 들면 성별 평균 키를 계산하는 것처럼요.
이번 포스팅에서는 Pandas를 이용하여 그룹별로 각종 통계값을 계산하는 방법에 대해서 소개하려고 합니다. 여기서 다루는 내용은 다음과 같습니다.
3. 데이터 그룹별 두개 이상의 칼럼에 대하여 집계하기
1. 데이터 그룹별 집계하기
먼저 이번 포스팅에서 사용할 샘플 데이터를 다운받아주세요.
다운받으셨다면 필요한 모듈을 임포트하고 데이터를 불러와주세요.
import pandas as pd
df = pd.read_csv('sample.csv', encoding='cp949') ## 한글이 포함되어 있어 ecoding 방식을 'cp949'로 지정

그룹별로 집계하기 위해서는 Pandas의 groupby와 agg를 사용해야 합니다. 아래 코드는 성별 평균 키를 계산하는 코드입니다.
df.groupby('gender')['height'].agg(**{'mean_height':'mean'}).reset_index() ## 성별 평균키
line 1
먼저 데이터를 그룹별로 묶어주기 위하여 groupby를 사용합니다. 이때 성별로 묶어줘야 하므로 groupby 인자에 성별을 뜻하는 'gender' 칼럼을 넣어줍니다.
그리고 각괄호를 이용하여 집계하려고 하는 칼럼 이름을 지정해줍니다. 여기서는 평균 키를 구하려고 하므로 이에 해당하는 칼럼인 'height'를 지정합니다.
다음으로 실질적으로 집계를 해주는 agg를 이용할 겁니다. agg에 대한 사용방법은 여러 가지가 있으나 꽁냥이가 자주 사용하는 방법을 소개합니다. agg에 'Key'는 집계 칼럼 이름 그리고 'Value'는 적용 함수로 하는 딕셔너리를 agg에 keyword 인자로 넣어주어야 합니다. 꽁냥이는 평균 키를 의미하는 'mean_height'를 집계 칼럼 이름으로 정했으며 적용 함수는 평균을 뜻하는 문자열인 'mean'을 넣어주었습니다. 참고로 적용 함수에는 lambda를 이용할 수 있습니다. 적용함수에 사용 가능한 함수 문자열이 궁금하신 분들은 여기를 참고해주세요.
추가적으로 reset_index를 이용하여 헤더 부분을 정렬시켜주었습니다(선택사항).
위 코드를 실행시키면 아래와 같이 성별 평균 키가 계산된 것을 확인할 수 있습니다.

만약 성별 키의 최대값과 성별 연령 중간값을 알고 싶다면 아래 코드와 같이 하면 됩니다.
df.groupby('gender')['height'].agg(**{'max_height':'max'}).reset_index() ## 성별 키 최대값
df.groupby('gender')['age'].agg(**{'median_age':'median'}).reset_index() ## 성별 연령 중간값
만약 데이터가 명목형(또는 범주형)인 경우 그룹별 최빈값을 계산해야 할 필요가 있을 것입니다. 이번에는 성별 거주지역의 최빈값을 구해보도록 하겠습니다. 아래 코드를 살펴보겠습니다.
## 성별 거주지역 최빈값
df.groupby('gender')['region'].agg(**{
'most_common_value':lambda x:x.mode()
}).reset_index()
line 2~4
평균('mean')과 최대값('max')과는 달리 최빈값에 대응하는 함수 문자열이 없습니다. 따라서 이때에는 lambda를 이용하여 최빈값을 구해주는 함수를 넣어주어야 합니다.
agg 내에서 lambda 인자는 하나의 칼럼이 됩니다(여기서는 성별로 그룹화된 거주지역 칼럼). 그리고 최빈값을 구하기 위해 먼저 각 칼럼 내에서 최빈값을 계산해주는 mode함수를 이용했습니다.
위 코드를 실행하면 다음과 같은 결과를 얻게 됩니다.

만약 2개의 변수를 기준으로 그룹을 묶어서 집계를 해보겠습니다. 아래 코드는 성별과 지역 두 가지 변수를 기준으로 그룹화한 뒤에 그룹별 평균 키를 계산하는 코드입니다.
df.groupby(['gender','region'])['height'].agg(**{'mean_height':'mean'}).reset_index() ## 성별 & 지역별 키 최대값
line 1
성별과 지역을 기준으로 그룹화해야 하기 때문에 groupby에 'gender'와 'region'을 리스트로 담아 인자로 넘겨주었습니다. 다른 부분은 앞서 살펴본 것과 동일합니다.

이런 식으로 2개 이상의 칼럼을 이용하여 그룹화하여 집계할 수 있습니다.
2. 데이터 그룹별 각종 통계값 동시에 계산하기
지금까지는 그룹별로 집계 항목이 하나뿐이었는데요. 그룹별로 최대값, 최소값, 평균 등 여러 가지 통계치를 동시에 구하고 싶을 때가 있지요.
이번에는 성별 키의 최소값과 최대값을 동시에 구해보겠습니다. 아래 코드를 살펴보겠습니다.
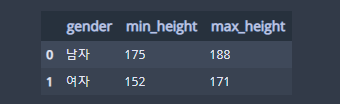
df.groupby('gender')['height'].agg(**{
'min_height':'min',
'max_height':'max'
}).reset_index() ## 성별 키 최소값, 최대값
line 1~4
이미 눈치채신 분들도 있을 거예요. 성별 최소값과 최대값에 대응하는 keyword 인자 딕셔너리에 추가해주시기만 하면 됩니다.
위의 결과는 아래의 코드로도 동작합니다('height'를 담고 있는 각괄호가 1겹이 아닌 2겹임을 주목하세요).
df.groupby('gender')[['height']].agg(['min','max'])
대신 출력 결과가 조금 다릅니다.
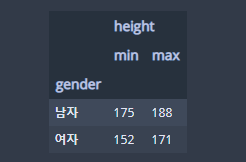
출력 결과가 조금 다르더라도 전달하는 정보에는 차이가 없습니다. 다만 keyword를 이용한 방법은 집계 결과에 대한 칼럼명을 사용자가 원하는 대로 바꿀 수 있다는 장점이 있습니다.
3. 데이터 그룹별 두 개 이상의 칼럼에 대하여 집계하기
지금까지는 그룹별로 한 개 칼럼에 대한 통계치를 구해보았는데요. 상황에 따라서 그룹별로 여러 칼럼에 대한 통계치를 구하고 싶을 때가 있지요. 이번에는 성별 평균 키와 평균 연령을 계산해보도록 하겠습니다.
df.groupby('gender')[['age','height']].agg(['mean']) ## 여러 칼럼에 대한 집계
line 1
groupby에 인자를 'gender'로 넣어주어 성별로 그룹화시킨 뒤, 'age'와 'height'를 리스트로 담아 통계치를 계산할 칼럼을 지정합니다. 그리고 평균값을 구해야 하므로 agg인자에 'mean'을 담은 리스트를 넣어줍니다.
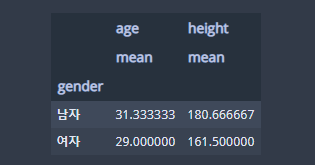
위에서 살펴본 것은 여러 개 칼럼에 대한 같은 통계치(평균)를 계산한 것인데요. 각 칼럼 별로 다른 통계치를 구하고 싶다면 어떻게 해야 할까요? 예를 들면 연령 칼럼에 대해서는 최소, 최고 연령을 구하고 키에 대해서는 평균값을 구하는 것처럼 말이죠. 다른 여러 가지 방법이 있을 수 있지만 꽁냥이는 pd.NamedAgg를 이용해서 보여드리려고 해요.
다음은 성별 최소 연령, 최고 연령, 키의 평균, 키의 중간값을 구하는 코드입니다.
df.groupby('gender').agg(**{
'min_age':pd.NamedAgg(column='age', aggfunc='min'),
'max_age':pd.NamedAgg(column='age', aggfunc='max'),
'mean_height':pd.NamedAgg(column='height', aggfunc='mean'),
'median_height':pd.NamedAgg(column='height', aggfunc='median')
}).reset_index() ## 집계 결과에 대한 칼럼 설정
line 1~6
pd.NamedAgg의 기본 사용법은 집계 함수를 적용할 칼럼과 집계함수를 인자로 넣어주는 것입니다.
먼저 groupby에 'gender'를 인자로 주어 성별로 그룹화하는 것은 기존과 동일합니다. 하지만 pd.NamedAgg에 집계함수를 적용할 칼럼을 지정하기 때문에 앞서 살펴보았던 것처럼 각괄호를 이용하여 따로 칼럼을 지정하지 않습니다.
성별 최소 연령을 구해야 하므로 pd.NamedAgg의 column 인자에 'age'를 aggfunc 인자에 'min'을 넣어주면 됩니다. 그리고 이러한 집계 결과를 출력하는 열의 이름을 'min_age'로 지정하였습니다.
위 코드를 실행해보세요.

성별로 연령과 키에 대한 통계치가 잘 나온 것을 확인할 수 있습니다.
이번 포스팅에서는 Pandas를 이용하여 그룹별로 집계해보는 법에 대하여 알아보았습니다. 여기서 소개한 방법 이외에도 다른 방법이 많이 있습니다. 궁금하신 분들은 여기를 참고하셔서 자신에게 익숙한 방법을 찾으시길 바랍니다.
또한 groupby에 대한 고급 스킬도 정리해놓았으니 관심있는 분들은 여기를 참고해보세요.
질문은 댓글로 남겨주시면 성실하게 답변드리겠습니다. 지금까지 꽁냥이의 글 읽어주셔서 감사합니다.
안녕히 계세요~
'데이터 분석 > 데이터 전처리' 카테고리의 다른 글
| [Pandas] 16. apply 함수 사용법 알아보기. (0) | 2021.01.19 |
|---|---|
| [Pandas] 15. 결측치(Missing Value) 처리하기 (0) | 2020.12.02 |
| [Pandas] 13. 날짜를 이용하여 데이터 조회하기 (0) | 2020.11.21 |
| [Pandas] 12. 행 추가/삭제하기 (0) | 2020.09.30 |
| [Pandas] 11. 데이터프레임 셀 스타일 변경하기 (7) | 2020.09.27 |





댓글