안녕하세요~ 꽁냥이에요. R을 이용하시는 분들은 데이터 테이블을 파이프라인 연산자 '%>%'을 이용하여 쉽게 전처리 코딩을 할 수 있습니다. 하지만 파이썬(Python)에서도 Pandas의 데이터프레임을 파이프라인 연산자 '>>' 또는 '>>='을 이용하여 전처리를 쉽게 할 수 있다는 것을 알고 계셨나요? 바로 오늘 소개할 dfply을 이용하면 이것이 가능합니다.
이번 포스팅에서는 dfply 사용법에 대해서 알아보겠습니다.
- 목차 -
1. dfply 기본
1) 설치
먼저 dfply를 pip 명령어를 통해 설치해 줍니다.
pip install dfply2) 파이프라인 연산자 '>>', '>>='
파이프라인 연산자는 왼쪽에 있는 입력데이터를 오른쪽에 전달해 주는 연산자라고 생각하면 됩니다. dfply에서 제공하는 파이프라인 연산자는 '>>', '>>='가 있으며 '>>'은 처리 결과를 사본으로 출력하고 '>>='은 처리 결과를 원본에 적용하는 차이가 있습니다. 예제를 통해서 알아보겠습니다.
a. '>>' : 처리 결과를 사본으로 출력
아래 코드는 dfply에서 제공하는 diamonds 데이터에 대해서 처음 3행을 출력합니다.
import dfply from dfply import diamonds ## 다이아몬드 데이터 diamonds >> dfply.head(3) ## 사본 출력 carat cut color clarity depth table price x y z 0 0.23 Ideal E SI2 61.5 55.0 326 3.95 3.98 2.43 1 0.21 Premium E SI1 59.8 61.0 326 3.89 3.84 2.31 2 0.23 Good E VS1 56.9 65.0 327 4.05 4.07 2.31
'>>'를 이용하여 처리 결과를 저장하려면 새로운 변수에 할당해줘야 합니다.
reduced_diamonds = diamonds >> dfply.head(2) ## 새로운 변수에 할당 reduced_diamonds carat cut color clarity depth table price x y z 0 0.23 Ideal E SI2 61.5 55.0 326 3.95 3.98 2.43 1 0.21 Premium E SI1 59.8 61.0 326 3.89 3.84 2.31
b. '>>=' : 처리 결과를 원본에 적용
'>>='은 사본을 출력하지 않고 처리 결과를 원본에 바로 적용됩니다. Pandas 데이터프레임 전처리시 inplace=True를 지정하는 것과 같은 효과입니다.
diamonds >>= dfply.head(3) ## 원본에 처리 결과를 적용하므로 아무것도 출력되지 않는다. diamonds carat cut color clarity depth table price x y z 0 0.23 Ideal E SI2 61.5 55.0 326 3.95 3.98 2.43 1 0.21 Premium E SI1 59.8 61.0 326 3.89 3.84 2.31 2 0.23 Good E VS1 56.9 65.0 327 4.05 4.07 2.31
3) X : 데이터프레임
dfply의 파이프라인 연산자는 기본적으로 데이터프레임을 입력 인자로 취급합니다. 하지만 데이터 전처리를 하다 보면 데이터프레임이 아닌 데이터프레임의 특정 칼럼을 처리해줘야 할 때가 있습니다. dfply의 X를 이용하면 입력 인자로 받는 데이터프레임을 임시로 표시할 수 있으며 이를 통해 칼럼에 접근할 수 있습니다.
아래 코드는 diamonds 데이터에서 carat과 cut 칼럼만을 추출한 뒤 처음 3행을 뽑아낸 것입니다. select 함수의 구체적인 내용은 아래에서 다루겠습니다.
from dfply import select, head, X, diamonds ## 다이아몬드 데이터 diamonds >> select(X.carat, X.cut) >> head(3) ## 또는 diamonds >> select(X['carat'], X['cut']) >> head(3) carat cut 0 0.23 Ideal 1 0.21 Premium 2 0.23 Good
2. 칼럼 선택 및 제외
1) 칼럼 선택(추출)하기 : select
select를 이용하면 필요한 칼럼만 포함하는 데이터프레임을 출력할 수 있습니다. 필요한 칼럼을 지정하는 방식은 칼럼 위치 인덱스, 칼럼 이름 문자열 또는 dfply의 X를 이용한 칼럼 접근법을 이용할 수 있습니다.
아래 코드는 두 번째 위치의 칼럼, color, x, y의 칼럼을 선택한 뒤 처음 2개 행을 출력합니다.
from dfply import select, head, X, diamonds ## 다이아몬드 데이터 diamonds >> select(1, X['carat'], ['x', 'y']) >> head(2) cut carat x y 0 Ideal 0.23 3.95 3.98 1 Premium 0.21 3.89 3.84
2) 칼럼 제외(삭제)하기 : drop
drop을 이용하면 필요 없는 칼럼을 제외하여 데이터프레임을 출력할 수 있습니다. drop에서 제외할 칼럼을 지정하는 방식은 select와 동일합니다.
아래 코드는 첫 번째 위치의 칼럼, price, x, y 칼럼을 제외하고 처음 2개 행을 출력합니다.
from dfply import drop, head, X, diamonds ## 다이아몬드 데이터 diamonds >> drop(0, X['price'], ['x', 'y']) >> head(2)

참고로 select를 이용해서도 칼럼을 제외할 수 있는데 이때 제외할 칼럼 앞에 '~'을 붙여줘야 합니다. 다만 이 기호는 dfply의 X 앞에만 사용할 수 있습니다.
from dfply import select, head, X, diamonds ## 다이아몬드 데이터 diamonds >> select(~X['price'], ~X.x, ~X.y) >> head(2)
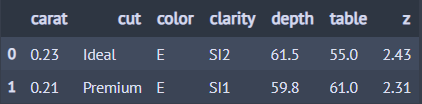
3) 칼럼 선택 함수
dfply 모듈은 다음과 같이 칼럼을 선택하기 위한 유용한 함수를 제공합니다.
starts_with('문자열') : 특정 문자열로 시작하는 칼럼 선택
ends_with('문자열') : 특정 문자열로 끝나는 칼럼 선택
contains('문자열') : 특정 문자열을 포함하는 칼럼 선택
everything() : 모든 칼럼을 선택(앞에 선택된 칼럼이 있다면 나머지 칼럼을 선택)
columns_between(칼럼1, 칼럼2, inclusive=True) : 칼럼1과 칼럼 2 사이의 모든 칼럼을 선택, inclusive가 True이면 칼럼2를 포함하고 False이면 포함하지 않음
columns_to(칼럼1, inclusive=True) : 첫 칼럼부터 칼럼1까지의 모든 칼럼을 선택
columns_from(칼럼1, inclusive=True) : 칼럼 1부터 마지막 칼럼까지의 모든 칼럼을 선택
아래 코드는 'c'로 시작하는 모든 칼럼을 선택합니다.
from dfply import select, starts_with, X, diamonds ## 다이아몬드 데이터 diamonds >> select(starts_with('c')) >> head(2) ## 'c'로 시작하는 모든 칼럼
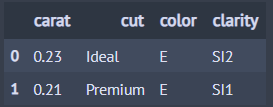
아래 코드는 반대로 'c'로 시작하는 칼럼을 제외합니다.
from dfply import select, starts_with, X, diamonds ## 다이아몬드 데이터 diamonds >> select(~starts_with('c')) >> head(2) ## 'c'로 시작하는 칼럼 제외
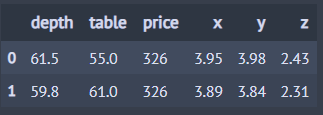
아래 코드는 처음부터 두 번째 칼럼, 중간에 depth 칼럼 그리고 마지막 2개의 칼럼을 선택합니다.
from dfply import select, columns_to, columns_from, X, diamonds ## 다이아몬드 데이터 diamonds >> select(columns_to(1, inclusive=True), 'depth', columns_from(-2)) >> head(2)
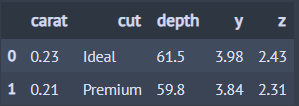
3. 행 필터링
1) 조건을 통한 필터링 : filter_by
filter_by에 원하는 조건식을 넣어주면 조건에 맞는 행을 필터링합니다. 이때 조건식에서 사용되는 칼럼은 X 기호를 사용하여 표현해야 합니다. 아래 코드는 filter_by를 사용하는 예제입니다. 설명은 주석을 참고하세요.
import pandas as pd from dfply import filter_by, X df = pd.DataFrame() df['A'] = ['a', 'a' , 'b', 'c'] df['B'] = [1,2,3,4] df >> filter_by((X.A=='b') | (X.B==1)) ## A == 'b' or B==1 df >> filter_by(X.A=='b', X.B==1) ## A == 'b' and B==1 df >> filter_by(X.A.isin(['a', 'b'])) ## A in ['a', 'b']
2) 행 필터링
a. 인덱스를 이용한 행 필터링 : row_slice
row_slice는 Pandas 데이터프레임에서 데이터를 슬라이싱할 때 사용하는 iloc와 같은 역할을 합니다.
from dfply import row_slice, head, diamonds diamonds >> row_slice([10, 15]) ## 인덱스가 10과 15인 행 추출

b. 행 랜덤 샘플링 : sample
Pandas 데이터프레임에서 sample 메서드를 이용한 행 샘플링을 dfply의 sample을 통해서도 할 수 있습니다.
아래 코드는 sample의 사용법을 나타낸 것입니다.
from dfply import sample, diamonds diamonds >> sample(frac=0.0001, replace=False) ## 전체 데이터에서 비율 0.0001 만큼 비복원 추출 diamonds >> sample(n=4, replace=True) ## 전체 데이터에서 4개 복원 추출
c. 유니크 행 추출 : distinct
중복이 없는 유니크한 행을 추출하기 위해선 distinct를 이용할 수 있습니다. Pandas 데이터프레임의 drop_duplicates 사용법과 유사합니다.
from dfply import distinct, diamonds diamonds >> distinct(X.color, keep='last') ## X.color에 대해서 유니크한 행을 추출 이때 마지막 데이터를 keep
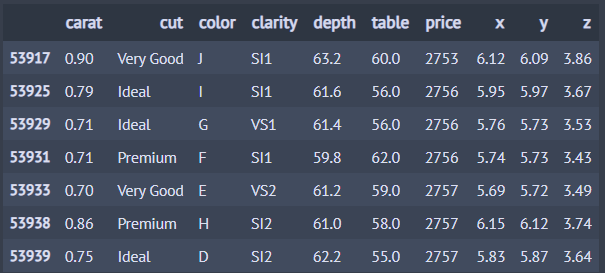
4. 데이터 변환(칼럼 생성)
1) 칼럼 생성과 칼럼 변환 : mutate
mutate를 이용하면 새로운 칼럼을 만들 수 있고 기존 칼럼을 변환할 수도 있습니다.
아래 코드는 빈 데이터프레임에서 A, B 칼럼을 만들고 B 칼럼을 2배로 변환합니다.
import pandas as pd from dfply import mutate, X df = pd.DataFrame() df >>= mutate(A=[1,2,3,4], B=[4, 1, 3, 2]) >> mutate(B=2*X.B) ## 새로운 칼럼 생성과 기존 칼럼 변환 df

2) mutate+select : transmute
mutate를 이용하여 칼럼을 변환한 뒤 해당 칼럼만 선택하고 싶을 수 있습니다. 이때에는 mutate와 select를 이용할 수도 있겠지만 transmute를 사용하면 한 방에 해결할 수 있습니다.
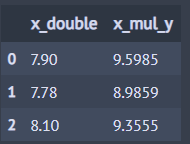
아래 코드는 diamonds 데이터에서 기존 칼럼을 이용하여 만들어진 2개의 칼럼을 출력(처음 행 3개만)합니다.
from dfply import mutate, select, transmute, head, X, diamonds diamonds >> transmute(x_double = 2*X.x, x_mul_y = X.x*X.z) >> head(3)
mutate와 select를 이용해도 위와 동일한 결과를 얻을 수 있습니다.
diamonds >> mutate(x_double = 2*X.x, x_mul_y = X.x*X.z) >> select(X.x_double, X.x_mul_y) >> head(3)5. 윈도우 함수와 요약 함수
1) 윈도우 함수
윈도우 함수는 어떤 벡터를 입력하면 그 벡터와 같은 길이를 반환하는 함수를 칭한다고 보면 됩니다. 여기서는 자주 사용되는 lead와 lag 그리고 between 함수를 소개하겠습니다. dfply에서는 이외에도 여러 윈도우 함수를 제공하는데 자세한 내용은 dfply 윈도우 함수 섹션을 참고하시기 바랍니다.
a. 이전 시점과 이후 시점 : lag, lead
lag는 기존 벡터의 이전 시점의 값으로 이루어진 벡터, lead는 이후 시점의 값으로 이루어진 벡터를 반환합니다.
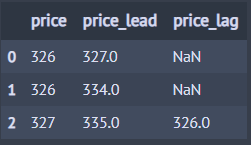
아래 코드는 diamonds의 price 칼럼에서 2 시점 이전(price_lag)과 2 시점 이후(price_lead)의 값을 칼럼으로 만들어 출력합니다. 이때 둥근 괄호를 치는 이유는 코드 줄 바꿈을 하기 위함입니다. 괄호가 없으면 에러가 납니다.
from dfply import mutate, select, lead, lag, head, X, diamonds (diamonds >> mutate(price_lead=lead(X.price, 2), price_lag=lag(X.price, 2)) >> select(X.price, X.price_lead, X.price_lag) >> head(3))
b. 구간 포함 여부 : between
between은 해당 칼럼 값들이 구간에 포함되는지 여부를 알 수 있습니다.
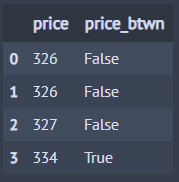
아래 코드는 price 칼럼이 330과 340 사이에 있는지 여부를 알려주는 칼럼(price_btwn)을 생성합니다.
from dfply import mutate, select, between, head, X, diamonds diamonds >> select(X.price) >> mutate(price_btwn=between(X.price, 330, 340)) >> head(4)
2) 요약 함수
요약 함수는 집계를 할 때 사용되는 함수입니다. 요약 함수는 그 자체로는 쓰이지 않고 group_by로 그룹핑을 한 다음 집계 처리를 하는 summarize 함수 내부에서 사용됩니다. dfply에서는 평균, 표준편차를 포함한 여러 요약 함수는 제공합니다. 여기에서는 자주 사용되는 함수를 소개하며 그 이외의 함수는 dfply 요약 함수 섹션을 참고하세요.
mean : 평균
median : 중앙값
colmin : 최소값
colmax : 최대값
sd : 표준편차
first : 첫 번째 값
last : 마지막 값
n : 그룹 내 데이터 개수
n_distinct : 그룹 내 유니크 원소 개수
요약 함수의 구체적인 사용법은 아래에서 다루겠습니다.
6. 그룹별 집계
dfply에서는 group_by를 통해 그룹 변수를 지정하여 그룹핑한 뒤 summarize를 통해 집계를 합니다.
from dfply import group_by, mean, sd, first, last, n, n_distinct, colmax, colmin, summarize (diamonds >> group_by(X.cut) >> summarize( price_mean = mean(X.price), price_sd = sd(X.price), price_first = first(X.price), price_last = last(X.price), price_n = n(X.price), price_n_distinct = n_distinct(X.price), price_max = colmax(X.price), price_min = colmin(X.price) ))
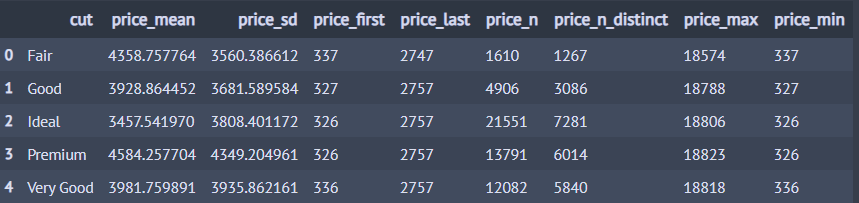
7. 재구조화
dfply에서는 재구조화를 위한 함수를 제공하는데요. 여기서는 내림차순 또는 오름차순 정렬과 칼럼 이름 변경에 대한 부분만 알아보겠습니다. 자세한 내용은 dfply 재구조화 섹션을 참고해 주세요.
1) 정렬 : arrange
arrange 함수는 Pandas 데이터프레임의 sort_values와 사용법이 같습니다.
from dfply import arrange, X, diamonds diamonds >> arrange(X.price, ascending=False) >> head(3) ## price 기준 내림차순 정렬. 오름 차순은 ascending=True
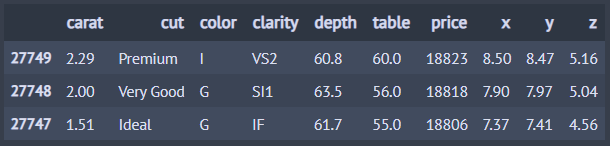
2) 칼럼 이름 변경 : rename
rename을 이용하면 칼럼 변경이 가능합니다. rename에 '새로운 칼럼 이름 = 바꿀 칼럼 이름' 형식을 입력하며 바꿀 칼럼 이름은 X 기호를 사용하거나 문자열을 이용할 수도 있습니다.
from dfply import rename, head, X, diamonds diamonds >> rename(CUT=X.cut, COLOR='color') >> head(2)

8. 결합
dfply에서도 데이터 결합(join)을 할 수 있는 함수를 제공합니다. 자주 사용되는 함수는 inner_join, outer_join, left_join, right_join이 있습니다. 결합과 관련된 dfply 함수는 dfply 결합 함수 섹션을 참고해 주세요.
예제를 위해 두 개의 데이터프레임을 만들어보겠습니다.
import pandas as pd from dfply import outer_join, inner_join, left_join, right_join A = pd.DataFrame({ 'x1':['A','B','C'], 'x2':[1,2,3] }) B = pd.DataFrame({ 'x1':['A','B','D'], 'x3':[True,False,True] })
이제 아래 코드를 통해 함수 사용법을 확인해 보세요.
A >> outer_join(B, by='x1') ## Outer 조인
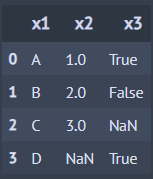
A >> inner_join(B, by='x1') ## Inner 조인

A >> left_join(B, by='x1') ## Left 조인
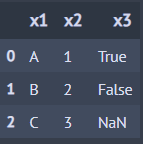
A >> right_join(B, by='x1') ## Right 조인
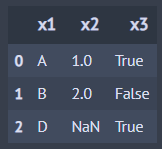
9. 집합 연산과 바인딩
1) 집합 연산
dfply는 데이터의 행을 원소로 하는 집합에 대해서 집합 연산을 할 수 있습니다. 집합 연산자는 union(합집합), intersect(교집합), set_diff(차집합)이 있습니다.
예제를 위해 2개의 데이터프레임을 만들어보겠습니다.
import pandas as pd from dfply import union, intersect, set_diff A = pd.DataFrame({ 'x1':['A','B','C'], 'x2':[1,2,3] }) B = pd.DataFrame({ 'x1':['B','C','D'], 'x2':[2,3,4] })
아래 코드를 통해 집합 연산자 사용법을 확인해 보세요.
A >> union(B) ## 합집합
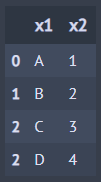
A >> intersect(B) ## 교집합

A >> set_diff(B) ## A - B
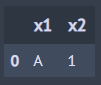
2) 바인딩
r에서는 rbind, cbind를 이용하여 데이터를 바인딩하고 Pandas에서는 concat을 이용하여 데이터를 바인딩할 수 있습니다. dfply에서도 바인딩할 수 있는 함수를 제공합니다. 행 바인딩은 bind_rows, 열 바인딩은 bind_cols를 이용하면 됩니다. 여기서는 기본적인 사용방법만 살펴보겠습니다. 자세한 내용은 dfply 바인딩 함수 섹션을 참고해 주세요.
먼저 예제용 데이터프레임을 만들어 줍니다.
import pandas as pd from dfply import bind_rows, bind_cols A = pd.DataFrame({ 'x1':['A','B','C'], 'x2':[1,2,3] }) B = pd.DataFrame({ 'x1':['B','C','D'], 'x2':[2,3,4] })
A >> bind_rows(B) ## 행 바인딩
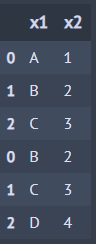
A >> bind_cols(B) ## 열 바인딩

이번 포스팅에서는 Pandas 데이터프레임을 파이프라인 연산자로 쉽게 코딩하게 해주는 dfply에 대해서 알아보았습니다. dfply가 Pandas가 업데이트되면서 일부 기능이 안 되는 것도 있어서 사용할 때 주의를 필요로 합니다. 잘만 쓰면 좀 더 생산성 있는 데이터 전처리 코드를 만들어 볼 수 있을 것 같습니다.
이번 포스팅이 도움이 되시길 바라며 다음에도 좋은 내용으로 찾아뵙겠습니다. 안녕히 계세요~~






댓글