안녕하세요~ 꽁냥이에요. 데이터 분석을 하다 보면 특정 칼럼에 어떤 값을 기준으로 순위(Rank)를 매겨야 할 때가 있는데요. Pandas에서는 rank라는 함수를 이용하여 데이터프레임(DataFrame)의 특정 칼럼으로 데이터의 순위를 매길 수 있습니다. 이번 포스팅에서는 데이터 rank를 이용한 순위를 구하는 방법에 대해서 알아보겠습니다.
데이터프레임(DataFrame)의 특정 칼럼으로 데이터 순위 매기기
1) 데이터프레임(DataFrame)의 특정 칼럼을 기준으로 순위 매기기
먼저 숫자 값을 갖고있는 배열의 순위(Rank)를 매기는 방식을 알아보겠습니다. 먼저 배열을 오름차순(또는 내림차순)으로 정렬한 뒤 맨 첫 원소의 1을 부여하고 다음 원소로 갈수록 1씩 증가시켜 순위(Rank)를 부여합니다.

여기서 동일값(Tie, 동점)에 대한 순위(Rank)를 어떤 방법으로 매기는지에 대한 문제가 생깁니다. Pandas에서는 동일값(Tie, 동점)에 대한 순위를 매기는 방법으로 아래와 같이 5가지 방법을 제공하고 있습니다.
'average', 'min', 'max', 'first', 'dense'
각 방법에 대해서 알아보겠습니다.
a. average : 동일값(Tie, 동점)에 매겨진 1차 순위의 평균으로 최종 순위 부여
b. min : 동일값(Tie, 동점)에 매겨진 1차 순위의 최소값으로 최종 순위 부여
c. max : 동일값(Tie, 동점)에 매겨진 1차 순위의 최대값으로 최종 순위 부여
d. first : 앞에 있는 동일값(Tie, 동점)에 우선적으로 최종 순위 부여
e. dense : min과 동일하나 다음 순위가 1씩 늘어남
(1) 오름차순 순위 부여 : asceding = True
이제 파이썬을 사용하여 rank의 사용법을 알아봅시다. 먼저 데이터를 생성하고 B 칼럼의 값을 오름차순 기준으로 하고 그리고 average 동점 처리 방식으로 순위(Rank)를 매겨보았습니다. 이때 오름차순으로 순위를 매기려면 ascending=True로 합니다. rank는 디폴트(기본값)로 오름차순으로 순위를 매깁니다.
import pandas as pd ## 데이터 생성 df = pd.DataFrame() df['A'] = ['a', 'a', 'a', 'b', 'b', 'b'] df['B'] = [1, 2, 2, 3, 4, 10] ## average 방식으로 동점 처리 df['rank'] = df['B'].rank(method='average') ## 또는 df['B'].rank(method='average', ascending=True) df
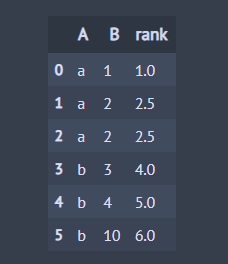
이번엔 동점 처리 방식별로 순위(Rank)가 어떻게 부여되는지 살펴보겠습니다.
## 데이터 생성 df = pd.DataFrame() df['A'] = ['a', 'a', 'a', 'b', 'b', 'b'] df['B'] = [1, 2, 2, 3, 4, 10] method_list = ['average', 'min', 'max', 'first', 'dense'] for method in method_list: df[f'rank_by_{method}'] = df['B'].rank(method=method) df
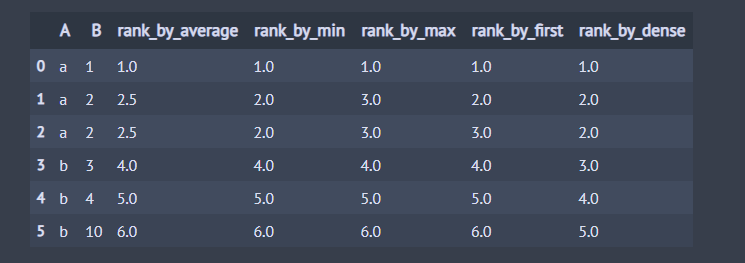
(2) 오름차순 순위 부여 : asceding = False
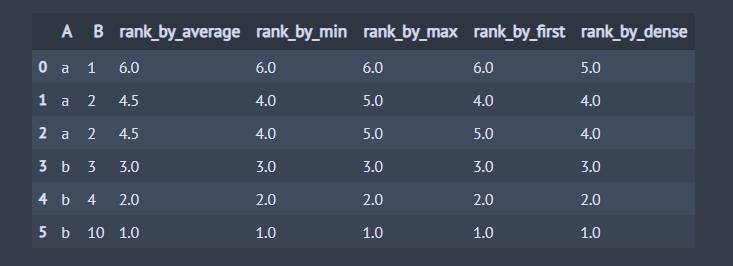
지금까지는 특정 칼럼의 값을 오름차순을 기준으로 랭크가 1부터 부여되었는데요. ascending=False 내림차순을 기준으로 랭크가 1부터 매겨지도록 할 수도 있습니다.
## 데이터 생성 df = pd.DataFrame() df['A'] = ['a', 'a', 'a', 'b', 'b', 'b'] df['B'] = [1, 2, 2, 3, 4, 10] method_list = ['average', 'min', 'max', 'first', 'dense'] for method in method_list: ## B 칼럼을 내림차순으로 순위 부여 df[f'rank_by_{method}'] = df['B'].rank(method=method, ascending=False) df
동점 처리 그림 그리기
2) 그룹별 순위 매기기
Padnas에서는 그룹별로 순위를 매길 수 있는 기능도 제공합니다. 똑같이 rank를 쓰면 되는데요. 그 방법을 알아봅시다.
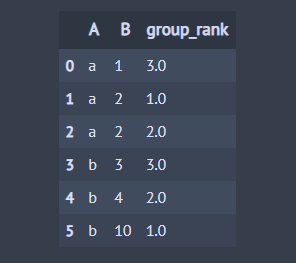
아래 코드는 A 칼럼을 기준으로 그룹을 나누고 각 그룹 내에서 B 칼럼의 값으로 내림차순, first 동점 처리 방식으로 순위를 매깁니다.
## 데이터 생성 df = pd.DataFrame() df['A'] = ['a', 'a', 'a', 'b', 'b', 'b'] df['B'] = [1, 2, 2, 3, 4, 10] ## 'B' 칼럼에 대하여 그룹별로 내림차순, first 동점 처리 방식으로 순위 부여 df['group_rank'] = df.groupby('A')['B'].rank(method='first', ascending=False) df
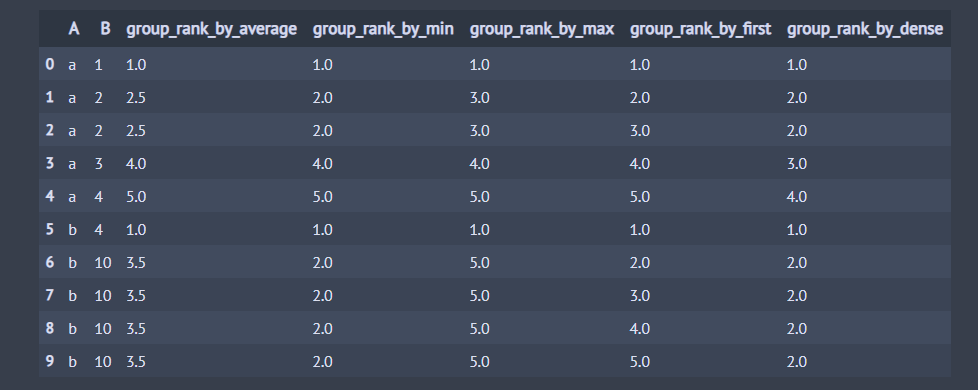
이번엔 모든 동점 처리 방식에 대하여 그룹 내 순위가 어떻게 변하는지 살펴봅시다.
## 데이터 생성 df = pd.DataFrame() df['A'] = ['a', 'a', 'a', 'a', 'a', 'b', 'b', 'b', 'b', 'b'] df['B'] = [1, 2, 2, 3, 4, 4, 10, 10, 10, 10] method_list = ['average', 'min', 'max', 'first', 'dense'] for method in method_list: ## B 칼럼을 오름차순으로 순위 부여 df[f'group_rank_by_{method}'] = df.groupby('A')['B'].rank(method=method, ascending=True) df
데이터의 순위(Rank)를 매기는 것은 원인 분석할 때 가장 높은 우선순위를 갖는 원인이 무엇인지 알아볼 때 많이 사용됩니다. 따라서 알아두시면 반드시 도움이 되실 겁니다. 지금까지 꽁냥이의 글 읽어주셔서 감사드리며 다음에 또 찾아뵙겠습니다.






댓글