안녕하세요~ 꽁냥이에요.
이번 포스팅에서는 Pandas에서 제공하는 여러 가지 통계량(평균, 분산, 중앙값, 분위수 등)을 정리해 보았어요. 테이블에 통계량의 의미와 함수를 정리했고요. 테이블에서 data는 숫자형 데이터를 담고있는 1차원 배열을 의미합니다. 또한 사용법도 있으니 같이 참고하시면 좋습니다.
여러가지 통계량
1) 대표값
| 평균 | pd.Series(data).mean() |
| 중앙값 | pd.Series(data).median() |
| 최빈값 | pd.Series(data).mode() |
| 제1 사분위수 | pd.Series(data).quantile(0.25) |
| 제2 사분위수(중앙값) | pd.Series(data).quantile(0.5) |
| 제3 사분위수 | pd.Series(data).quantile(0.75) |
- 파이썬 예제 -
data = [1,2,3,4,4,11,27,34,55,67,91,92]
print('평균 : ', pd.Series(data).mean())
print('중앙값 : ', pd.Series(data).median())
print('최빈값 : ', pd.Series(data).mode())
print('제 1 사분위수 : ', pd.Series(data).quantile(0.25))
print('제 2 사분위수 : ', pd.Series(data).quantile(0.5))
print('제 3 사분위수 : ', pd.Series(data).quantile(0.75))

2) 최대, 최소
| 최대값 | pd.Series(data).max() |
| 최소값 | pd.Series(data).min() |
- 파이썬 예제 -
data = [1,2,3,4,4,11,27,34,55,67,91,92]
print('최대값 : ', pd.Series(data).max())
print('최소값 : ', pd.Series(data).min())

3) 산포 통계량
| 표본 표준편차(분모 $n-1$) | pd.Series(data).std() 또는 pd.Series(data).std(ddof=1) |
| 표본 표준편차(분모 $n$) | pd.Series(data).std(ddof=0) |
| 표본 분산(분모 $n-1$) | pd.Series(data).var() 또는 pd.Series(data).var(ddof=1) |
| 표본 분산(분모 $n$) | pd.Series(data).var(ddof=0) |
| IQR(Interquartile Range : 사분위 범위) | pd.Series(data).quantile(0.75)-pd.Series(data).quantile(0.25) |
| 범위 | pd.Series(data).max() - pd.Series(data).min() |
여기서 분모 $n-1$은 편차 제곱합을 $n-1$로 나누어 준다는 뜻.
- 파이썬 예제 -
data = [1,2,3,4,4,11,27,34,55,67,91,92]
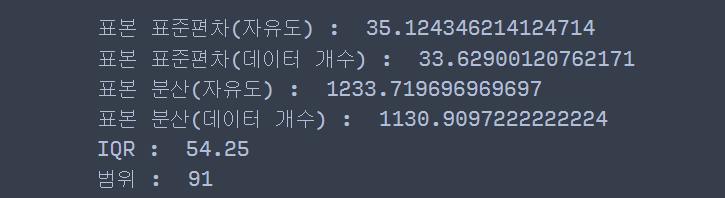
print('표본 표준편차(자유도) : ', pd.Series(data).std())
print('표본 표준편차(데이터 개수) : ', pd.Series(data).std(ddof=0))
print('표본 분산(자유도) : ', pd.Series(data).var())
print('표본 분산(데이터 개수) : ', pd.Series(data).var(ddof=0))
print('IQR : ', pd.Series(data).quantile(0.75)-pd.Series(data).quantile(0.25))
print('범위 : ', pd.Series(data).max() - pd.Series(data).min())
4) 기타
| 첨도(Kurtosis) | pd.Series(data).kurtosis() |
| 왜도(Skewness) | pd.Series(data).skew() |
- 파이썬 예제 -
data = [1,2,3,4,4,11,27,34,55,67,91,92]
print('첨도 : ', pd.Series(data).kurtosis())
print('왜도 : ', pd.Series(data).skew())

이번 포스팅에서는 Pandas에서 제공하는 통계량들을 살펴보았습니다. 자주 활용되는 통계량이므로 알아두시면 분명 도움이 될 거예요. 지금까지 꽁냥이의 글 읽어주셔서 감사합니다.






댓글