안녕하세요~ 꽁냥이에요.
데이터 분석을 하다 보면 그룹별로 집계를 해야 할 때가 있는데 Pandas에서는 뭔가 정해진 집계 함수만 사용하다 보니 좀 더 복잡한 집계를 어떻게 해야 하는지 모르는 분들이 계시더라고요.
그래서 이번엔 꽁냥이가 생각하는 판다스 집계 고급(?) 팁을 알려드리고자 합니다. 그전에 groupby에 대한 기본적인 내용을 먼저 보고 오시면 좋습니다.
https://zephyrus1111.tistory.com/70
[Pandas] 14. 데이터 그룹별로 집계하기
안녕하세요~ 꽁냥이에요. 데이터를 분석하다 보면 그룹별로 집계하여 데이터를 요약해야 할 일이 많이 있지요. 예를 들면 성별 평균 키를 계산하는 것처럼요. 이번 포스팅에서는 Pandas를 이용하
zephyrus1111.tistory.com
오늘 다룰 내용은 다음과 같아요.
1. groupby 동작 원리
먼저 groupby에 동작 원리에 대하여 설명하겠습니다~
아래와 같이 어떤 사람들의 성별과 키 정보가 포함된 데이터가 있다고 해볼게요. 이때 성별로 그룹화한 다음 각 성별의 평균으로 집계하는 경우의 과정은 아래 그림과 같습니다.

groupby를 통한 집계 과정은 다음과 같습니다.
1. 그룹화 변수에 대하여 각 카테고리별로 집계할 칼럼의 값을 Series 객체로 모아줍니다.
여기서 그룹화 변수는 '성별'이 되고 집계할 칼럼은 '키'가 됩니다. 위 그림에서 성별 중 여자의 집합에서 키에 대한 정보를 모아 하나의 Series 객체에 담습니다. 남자도 마찬가지입니다.
2. 각 Series 객체에 집계함수를 적용하여 하나의 데이터 프레임(DataFrame) 객체로 모아줍니다.
앞에서 카테고리별로 Series 객체가 완성되면 이를 인자로하여 집계 함수가 적용됩니다. 여기서는 남자 키 정보를 모은 Series, 여자 키 정보를 모은 Series에 평균 함수가 적용되지요. 그러고나서 각 성별에 대응하여 평균이 적용된 결과가 하나의 DataFrame으로 모아지게 됩니다.
Point!!
여기서 포인트는 Pandas에서 집계함수는 Series 객체를 인자로 받는다는 것입니다. 이를 잘 활용하면 복잡한 집계 처리도 가능합니다.
2. 함수를 적용하여 복잡한 집계 처리하기
이번엔 샘플 데이터를 이용하여 복잡한(?) 집계를 해보도록 하겠습니다.
먼저 데이터를 만들어 주세요.
import pandas as pd
df_dict = {
'성별':['남자', '여자', '남자', '여자', '여자', '남자', '남자', '여자'],
'이름':['박영진', '김지혜', '김철수', '박유니', '김민혜', '김민철', '구태원', '김민주'],
'키':[170, 150, 188, 160, 160, 176, 181, 155]
}
df = pd.DataFrame(df_dict)
이제 몇가지 미션을 수행해봅시다.
미션 1. 성별로 '김'씨가 몇 명인지 집계해보세요~
앞에서 배운 내용의 핵심은 집계함수는 그룹 카테고리별로 Series 객체를 인자로 받는다는 것입니다. 이때 집계 대상이 되는 칼럼은 이름일 테고 각 이름별로 '김'씨인 사람의 수를 세면 됩니다. 아래 코드는 '김'씨 성을 가진 사람의 수를 세는 함수입니다. 여기서 언더바(_)는 명시적으로 뭔가를 받아야 하지만 그 값이 필요 없을 때 임시로 사용하는 것입니다.
def get_lastname_count(series):
res = len([ _ for x in series if x[0]=='김'])
return res
이제 이 함수를 이용하여 미션을 수행해봅시다.
df.groupby('성별').agg({'이름':get_lastname_count}).reset_index()

예상대로 김씨는 남자 2명, 여자 3명이 나왔네요~
미션 2. groupby를 이용하여 남자는 키가 180 이상인 사람, 여자는 키 160 이상인 사람의 수를 계산해보세요.
이번엔 난이도가 있는 미션입니다. groupby를 안 쓰고 다른 방법으로 쉽게 할 수 있지만 groupby을 써서 미션을 수행하라고 하니 어려운 거예요. ㅠㅠ
먼저 집계함수는 Series 객체를 인자로 받는다고 했습니다. 이때 Series 객체의 인덱스 중 아무값과 원 데이터를 이용하여 성별 정보를 가져올 수 있습니다. 그리고 남자인 경우와 여자인 경우로 나누어 조건을 따로 적용하고 카운트를 세면 되지요. 이러한 원리를 이용하여 아래와 같이 집계 함수를 만들 수 있습니다.
def get_count_by_height(series):
if df.iloc[series.index[0], :]['성별'] == '남자':
res = len([_ for x in series if x>=180])
else:
res = len([_ for x in series if x>=160])
return res
df.groupby('성별').agg({'키':get_count_by_height}).reset_index()
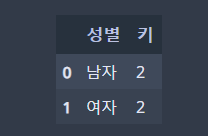
결과가 예상한 대로 잘 나온 것을 알 수 있습니다.
오늘 소개한 내용은 지인께서 꽁냥이에게 물어보신 내용이었는데 꽤나 유용해 보여서 포스팅으로 작성하게 되었습니다. 주제가 너무 지엽적일 수 있지만 알아두면 생각지도 못한 때에 유용하게 써먹을 수 있을 거예요.

'데이터 분석 > 데이터 전처리' 카테고리의 다른 글
| [Pandas] 26. 단순 이동 평균 계산하기 feat. rolling.mean() (410) | 2022.05.11 |
|---|---|
| [Pandas] pandas-datareader를 이용하여 주식(주가) 데이터 가져오기! (398) | 2022.05.11 |
| [Pandas] 25. 데이터(칼럼, 열) 변환 하기 (feat. columns, dtype, map, apply) (423) | 2022.04.16 |
| [Pandas] 24. 데이터프레임(Dataframe) 순회(loop)하기 - 행 방향 순회, 열 방향 순회 (411) | 2022.04.15 |
| [Pandas] 23. 데이터 유일(유니크, unique)값과 개수 구하기 (399) | 2022.04.07 |





댓글