안녕하십니까?! 꽁냥이입니다. 이번 포스팅에서는 Pandas에서 데이터 칼럼(열)을 변환하는 방법에 대해서 알아보려고 합니다.
데이터 분석을 하는 경우 문자형 숫자(예 '1', '1.1' 등)를 숫자로 바꿔주는 데이터 타입(Type) 변환이 필요합니다. 또한 예측 모델링을 하는 경우 주어진 학습 데이터를 그대로 이용하기보다는 원(Raw) 데이터를 변환(로그 변환, 절대값 변환 등)하여 학습을 진행하기도 합니다.
따라서 이번 포스팅에서는 Pandas에서 이러한 데이터 칼럼(열)을 변환하는 방법을 소개합니다. 여기서 다루는 내용은 다음과 깉습니다.
1. 데이터 타입(Type) 변환
Pandas에서는 astype를 이용하면 칼럼(열) 데이터 타입 변환을 할 수 있습니다.
먼저 예제용 데이터를 만들어줍니다. 그리고 각 칼럼의 데이터 타입을 확인해봅니다.
import pandas as pd import numpy as np df_dict = { 'STRING' : ['1', '2', '3', '5', '6'], 'FLOAT_NUM' : [1.0, 2.0, 3.0, 4.0, 5.0], } df = pd.DataFrame(df_dict) # 데이터 타입 확인 for col in df.columns: data_type = str(df[col].dtype) print(f'{col} : {data_type}')

STRING 칼럼은 object(보통 문자형이라고 생각하면 됨), FLOAT_NUM 칼럼은 float64라는 데이터 타입을 갖고 있습니다. 이때 STRING 칼럼은 float으로 FLOAT_NUM 칼럼은 int형으로 바꿔볼게요.
# 타입 변환 df['STRING'] = df['STRING'].astype(float) # string to float, float 대신 int도 가능 df['FLOAT_NUM'] = df['FLOAT_NUM'].astype(int) # float to int for col in df.columns: data_type = str(df[col].dtype) print(f'{col} : {data_type}')
코드를 실행하면 데이터 타입이 변환된 것을 확인할 수 있습니다.
2. 데이터 칼럼에 수치 함수 적용
데이터 칼럼에 수치 함수(로그, 절대값)를 적용시켜보겠습니다. 여기서 말하는 수치 함수란 Python의 내장 함수 또는 여러 모듈의 함수를 의미한다고 생각하면 됩니다(사실 수치 함수라고 제한시킬 필요는 없습니다).
Pandas에서는 map 또는 apply를 이용하여 칼럼에 함수를 적용할 수 있습니다. map 함수는 Pandas Series 객체가 갖고 있는 메서드이며 함수를 인자로 받습니다. map의 동작 원리는 시리즈 객체가 갖고 있는 원소에 접근하여 각 원소에 함수를 적용시킨다는 것입니다. 아래 그림을 보면 이해가 쉽습니다.
이제 코드를 통해 확인해보겠습니다.
먼저 샘플 데이터를 만들고 NUM1 칼럼에는 로그함수를, NUM2에는 절대값 함수를 적용시켰습니다.
df_dict = { 'NUM1' : [1.0, 2.0, 3.0, 4.0, 5.0], 'NUM2' : [2.3, -3.3, 1.1, 2, -3], } df = pd.DataFrame(df_dict) # 수치 함수 변환 # 로그 변환 df['LOG_NUM1'] = df['NUM1'].map(np.log) # 또는 np.log(df['NUM1']) # 절대값 변환 df['ABS_NUM1'] = df['NUM2'].map(np.abs) # 또는 np.abs(df['NUM2'])
코드를 실행하면 아래와 같이 함수들이 잘 적용된 것을 알 수 있습니다.
3. 데이터 칼럼에 내가 만든 함수 적용
Pandas 데이터프레임의 칼럼에는 이미 만들어진 함수뿐만 아니라 내가 만든 함수를 적용할 수 있습니다. map을 이용할 수도 있지만 여기서는 apply를 적용해보겠습니다. 그 이유는 apply는 함수의 추가적인 인자를 지정할 수 있기 때문입니다(map은 안됩니다).
아래 그림은 apply 동작 원리입니다. map과 비슷하지만 apply는 함수의 부가적인 인자도 넣어서 적용시킬 수 있습니다. 부가적인 인자는 튜플을 써서 지정합니다.
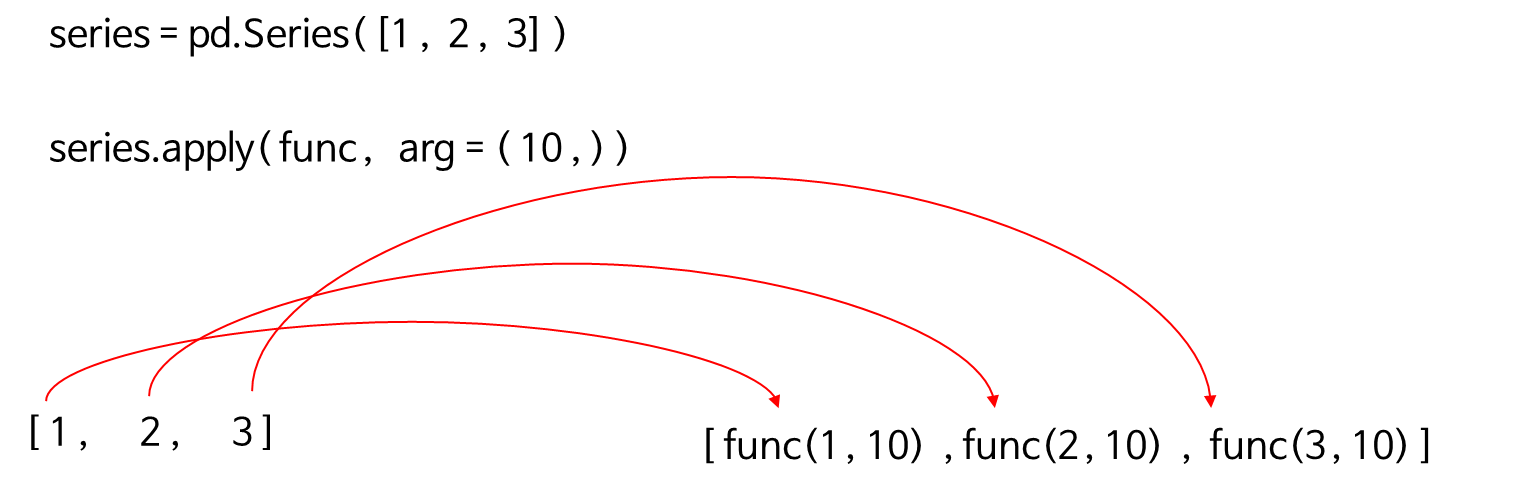
코드를 통해 알아보겠습니다. 여기서는 표준화(Standardization)과 정규화(Normalization)을 적용하는 함수를 만들어 적용시킬 것입니다. 각 함수는 pd.Series 객체를 추가적인 인자로 받습니다.
def do_standardize(x, series): mean = series.mean() std = series.std() return (x-mean)/std def do_normalize(x, series): max_val = series.max() min_val = series.min() return (x-min_val)/(max_val-min_val)
이제 만들어진 함수를 칼럼에 적용시켜 보겠습니다.
df_dict = { 'NUM1' : [1.0, 2.0, 3.0, 4.0, 5.0], 'NUM2' : [2.3, -3.3, 1.1, 2, -3], } df = pd.DataFrame(df_dict) # 표준화 df['STAND_NUM1'] = df['NUM1'].apply(do_standardize, args=(df['NUM1'],)) # 정규화 df['NORM_NUM2'] = df['NUM2'].apply(do_normalize, args=(df['NUM2'],))
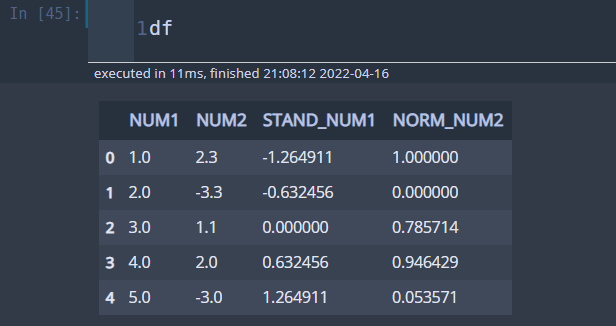
표준화와 정규화가 잘 적용된 것을 알 수 있습니다.
오늘은 데이터 전처리나 예측 모델링에서 많이 쓰일 법한 칼럼 변환 방법에 대해서 알아보았습니다. 알아두시면 굉장히 유용합니다. 이번 포스팅이 부디 도움이 되시길 바라며 이상 포스팅 마치겠습니다.
다음에도 좋은 내용으로 찾아뵙겠습니다. 감사합니다.

'데이터 분석 > 데이터 전처리' 카테고리의 다른 글
| [Pandas] pandas-datareader를 이용하여 주식(주가) 데이터 가져오기! (398) | 2022.05.11 |
|---|---|
| [pandas] 판다스 고급 Tip! Groupby에 복잡한 집계(조건부 집계 등) 함수 적용하기 (397) | 2022.04.27 |
| [Pandas] 24. 데이터프레임(Dataframe) 순회(loop)하기 - 행 방향 순회, 열 방향 순회 (411) | 2022.04.15 |
| [Pandas] 23. 데이터 유일(유니크, unique)값과 개수 구하기 (399) | 2022.04.07 |
| [Pandas] 22. Transform을 이용하여 그룹별 통계값으로 결측치 대체하기 (387) | 2022.04.03 |





댓글