안녕하세요~ 꽁냥이에요. 지난 포스팅에서는 Pandas의 melt 메서드를 이용하여 데이터를 재구조화하는 방법을 알아보았습니다. 이번 포스팅에서는 pivot과 pivot_table 메서드를 이용한 데이터 재구조화 방법에 대해서 알아보겠습니다.
[Pandas] 30. 데이터 재구조화(Reshape) 하기 (feat. melt)
[Pandas] 32. 데이터 재구조화(Reshape)하기 (feat. stack, unstack)
[Pandas] 33. 데이터 재구조화(Reshape)하기 (feat. wide_to_long)
[Pandas] 34. 데이터 재구조화(Reshape)하기 (feat. crosstab)
pivot, pivot_table을 이용한 데이터 재구조화(Reshape)
아래 그림은 pivot 또는 pivot_table 메서드를 이용한 데이터 재구조화 결과를 나타낸 것입니다. pivot 또는 pivot_table 메서드는 기본적으로 index, columns, values 3개의 인자를 가지며 각 인자에는 칼럼명을 전달합니다. index로 지정된 칼럼은 해당 칼럼에 대응하는 유니크한 값(조합)들이 인덱스로 바뀝니다(빨간색 선, 박스). columns로 지정된 칼럼은 해당 칼럼에 대응하는 유니크한 값(조합)의 개수만큼 새로운 칼럼들이 만들어집니다(연두색 선, 박스). values로 지정된 칼럼은 앞서 만들어진 index와 columns에 대응하는 값으로 셀에 채워지게 됩니다(주황색 선, 박스). 이때 대응되는 값이 없으면 NaN으로 채워집니다.
아래 그림에서 4개의 코드는 모두 같은 결과를 반환합니다.
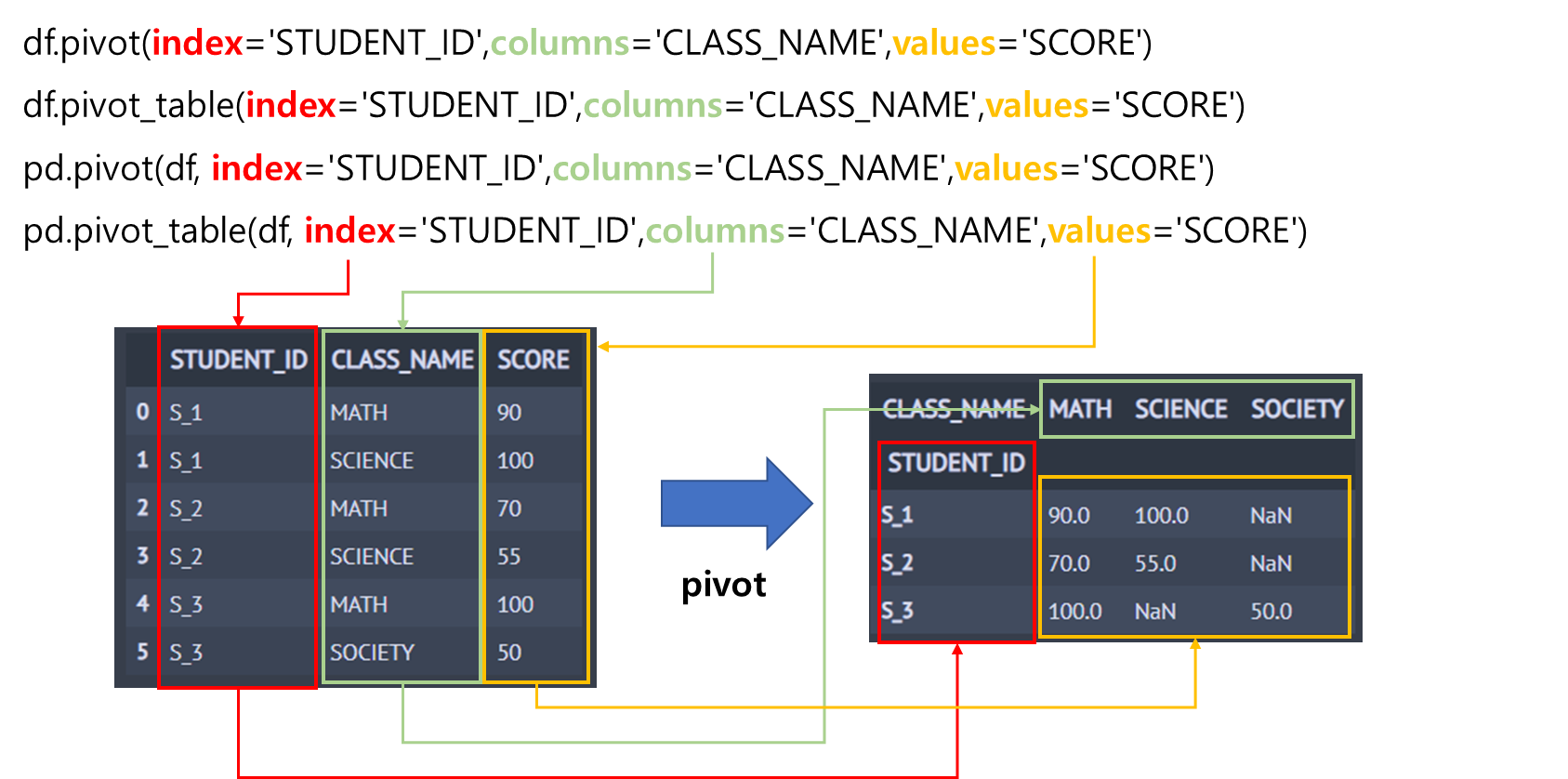
pivot을 통한 재구조화된 데이터의 차원(Dimension, Shape)은 다음과 같음을 알 수 있습니다.
index 칼럼의 유니크 값(조합) 개수 X columns 칼럼의 유니크 값(조합) 개수
이제 개념을 알았으니 코드를 통해 pivot 사용법을 알아볼게요. 먼저 pivot할 데이터를 만들어 줍니다.
import pandas as pd
data = {
'STUDNET_ID':['S_1', 'S_1', 'S_2', 'S_2'],
'TEACHER_ID':['T_1', 'T_2', 'T_1', 'T_2'],
'CLASS_ROOM':[101, 102, 201, 203],
'TIME':[1, 2, 3, 4]
}
df = pd.DataFrame(data)
df
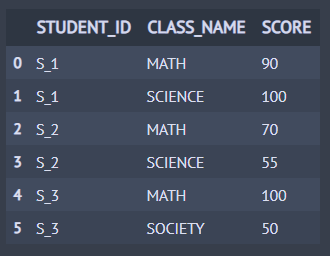
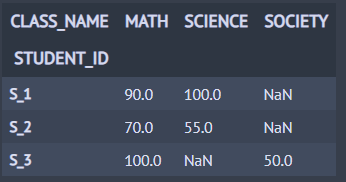
이제 pivot을 통해 데이터를 재구조화해보겠습니다. 아래 주석 처리된 코드는 모두 동일한 결과를 반환합니다.
df.pivot(index='STUDENT_ID',columns='CLASS_NAME',values='SCORE')
# df.pivot_table(index='STUDENT_ID',columns='CLASS_NAME',values='SCORE')
# pd.pivot(df, index='STUDENT_ID',columns='CLASS_NAME',values='SCORE')
# pd.pivot_table(df, index='STUDENT_ID',columns='CLASS_NAME',values='SCORE')
코드를 실행하면 아래와 같이 재구조화가 잘된 것을 알 수 있습니다.
코드를 보면서 다음과 같은 질문을 할 수 있습니다.
pivot과 pivot_table의 차이는 뭘까?
pivot과 pivot_table의 차이는 pivot은 데이터 재구조화만 할 수 있고 pivot_table을 재구조화뿐만 아니라 결측치를 대체하거나 집계를 할 수 있습니다. pivot_table의 fill_value 인자를 통해 결측치 대체, agg_func 인자를 통해 집계 처리를 할 수 있습니다. 아래 코드를 통해 사용법을 알아보세요.
df.pivot_table(index='STUDENT_ID',columns='CLASS_NAME',values='SCORE',
fill_value=0, ## NaN을 0으로 대체
margins=True, ## marginal 집계 처리
aggfunc=['sum', 'mean'] ## 집계 함수
)

이번 포스팅에서는 pivot을 이용한 데이터 재구조화 방법을 알아보았습니다. 데이터 재구조화는 은근 많이 활용되므로 알아두시면 반드시 도움이 되실 거예요. pivot 또는 pivot_table 메서드에 대한 더 자세한 내용은 여기를 참고해주세요.
부디 이번 포스팅이 많은 분들께 도움이 되셨으면 좋겠습니다. 다음에도 좋은 주제로 찾아뵐 것을 약속드리며 이상 포스팅 마치겠습니다. 안녕히 계세요~

'데이터 분석 > 데이터 전처리' 카테고리의 다른 글
| [Pandas] 33. 데이터 재구조화(Reshape)하기 (feat. wide_to_long) (2) | 2022.11.21 |
|---|---|
| [Pandas] 32. 데이터 재구조화(Reshape)하기 (feat. stack, unstack) (2) | 2022.11.19 |
| [Pandas] 30. 데이터 재구조화(Reshape) 하기 (feat. melt) (4) | 2022.11.18 |
| [Pandas] 29. 데이터 프레임을 칼럼 폭 조절, 첫 행 고정, 필터 추가하여 엑셀 저장하기 (feat. ExcelWriter) (0) | 2022.11.16 |
| [Pandas] 28. 데이터 필터링 하기 (feat. filter) (2) | 2022.11.15 |





댓글