안녕하세요~~ 꽁냥이에요.
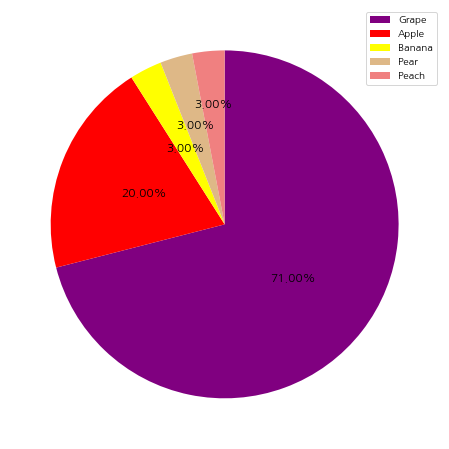
파이 차트를 그리다 보면 비율이 작은 데이터가 여러 개 있는 경우에, 다시 말하면 파이의 간격이 좁은 경우에 텍스트를 표시하게 되면 아래와 같이 글자가 겹쳐서 알아보기 힘들어집니다.

위에서 보시는 바와 같이 Banan, Pear, Peach에 대응하는 비율이 작을 때(여기서는 3%) 파이 차트를 그리게 되면 텍스트가 겹치게 되는 문제가 발생합니다.
따라서 이번 포스팅에서는 파이 차트를 그릴 때 텍스트를 겹치지 않게 그리는 방법에 대해서 알아보려고 합니다. 여기서는 두 가지 방법을 소개합니다.
계단형으로 텍스트를 배치시키기
Annotation을 이용하기
자!! 그럼 하나씩 살펴볼까요??
계단형으로 텍스트를 배치시키기
첫 번째 방법은 계단형으로 텍스트를 배치시키는 방법입니다.

즉, 왼쪽과 같이 겹쳐있는 텍스트를 계단 형태로 벌려서 겹치지 않게 만들려고 합니다.
전략은 다음과 같아요.
1. 빈도수를 기준으로 정렬합니다.
이렇게 정렬하는 이유는 비율이 작은 데이터들을 한 군데에 모으려고 하기 위함입니다. 이렇게 해야 텍스트를 계단처럼 배치할 수 있어요. 꽁냥이는 내림차순으로 정렬했어요.
2. 계단형으로 텍스트를 배치하게 되는 비율(%)의 상한선을 정합니다.
이렇게 정해진 비율보다 작거나 같으면 그에 대한 텍스트를 계단형으로 배치할 거예요. 예를 들어 계단형으로 배치하고 싶은 비율의 상한선을 5%라고 한다면 5%보다 작거나 같은 파이의 텍스트들을 계단형으로 배치하게 된다는 것입니다(아래 코드와 결과를 보면 금방 이해될 테니 지금은 이해가 안돼도 걱정 안 하셔도 됩니다).
3. 위아래 간격과 텍스트를 배치할 좌표를 계산합니다.

아이디어를 알았으니 이제 코드로 구현해보겠습니다. 아래 코드를 살펴볼게요.
import matplotlib.pyplot as plt
import numpy as np
## 데이터 준비
colors = ['red','yellow','purple','burlywood','lightcoral'] ## 색상
labels = ['Apple','Banana','Grape','Pear','Peach'] ## 라벨
frequency = [20,3,71,3,3] ## 빈도
## 데이터 라벨, 빈도수, 색상을 빈도수를 기준으로 정렬해야한다.
labels_frequency = zip(labels,frequency,colors)
labels_frequency = sorted(labels_frequency,key=lambda x: x[1],reverse=True)
sorted_labels = [x[0] for x in labels_frequency] ## 정렬된 라벨
sorted_frequency = [x[1] for x in labels_frequency] ## 정렬된 빈도수
sorted_colors = [x[2] for x in labels_frequency] ## 정렬된 색상
fig = plt.figure(figsize=(8,8)) ## 캔버스 생성
fig.set_facecolor('white') ## 캔버스 배경색을 하얀색으로 설정
ax = fig.add_subplot() ## 프레임 생성
pie = ax.pie(sorted_frequency, ## 파이차트 출력
startangle=90, ## 시작점을 90도(degree)로 지정
counterclock=False, ## 시계방향으로 그려짐
colors = sorted_colors, ## 색상 지정
)
total = np.sum(frequency) ## 빈도수 합
threshold = 5
sum_pct = 0 ## 퍼센티지
count_less_5pct = 0 ## 5%보다 작은 라벨의 개수
spacing = 0.1
for i,l in enumerate(sorted_labels):
ang1, ang2 = ax.patches[i].theta1, ax.patches[i].theta2 ## 파이의 시작 각도와 끝 각도
center, r = ax.patches[i].center, ax.patches[i].r ## 파이의 중심 좌표
## 비율 상한선보다 작은 것들은 계단형태로 만든다.
if sorted_frequency[i]/total*100 < threshold:
x = (r/2+spacing*count_less_5pct)*np.cos(np.pi/180*((ang1+ang2)/2)) + center[0] ## 텍스트 x좌표
y = (r/2+spacing*count_less_5pct)*np.sin(np.pi/180*((ang1+ang2)/2)) + center[1] ## 텍스트 y좌표
count_less_5pct += 1
else:
x = (r/2)*np.cos(np.pi/180*((ang1+ang2)/2)) + center[0] ## 텍스트 x좌표
y = (r/2)*np.sin(np.pi/180*((ang1+ang2)/2)) + center[1] ## 텍스트 y좌표
## 퍼센티지 출력
if i < len(labels) - 1:
sum_pct += float(f'{sorted_frequency[i]/total*100:.2f}')
ax.text(x,y,f'{sorted_frequency[i]/total*100:.2f}%',ha='center',va='center',fontsize=12)
else: ## 마지막 파이 조각은 퍼센티지의 합이 100이 되도록 비율을 조절
ax.text(x,y,f'{100-sum_pct:.2f}%',ha='center',va='center',fontsize=12)
plt.legend(pie[0],sorted_labels) ## 범례
plt.show()
위 코드를 앞서 소개한 3단계로 나누어 설명하겠습니다. 여기서 설명하지 않는 부분은 주석을 참고하세요.
1. 빈도수를 기준으로 정렬합니다.
line 10~15
데이터를 빈도수 기준으로 정렬합니다. zip을 이용하여 라벨, 빈도수, 색상을 묶어주고(line 10) 빈도수를 기준으로 정렬합니다(line 11). 그리고 다시 정렬된 라벨과 빈도수, 색상 리스트를 뽑아냅니다(line 13~15)
2. 계단형으로 텍스트를 배치하게 되는 비율(%)의 상한선을 정합니다.
line 29
꽁냥이는 비율의 상한선을 5%로 정했습니다.
3. 위아래 간격과 텍스트를 배치할 좌표를 계산합니다.
line 32
꽁냥이는 spacing이라는 변수에 텍스트 간격을 정하는 값을 넣었어요. 저는 0.1로 지정했습니다. 꽁냥이는 0.1~0.2 사이의 값에서 각자 상황에 맞게 고르시는 것을 추천합니다.
line 34~44
이제 텍스트를 배치할 좌표를 계산합니다. 좌표를 알기 위해선 파이 양쪽 사이드의 각과 원의 반지름, 원의 중심 좌표가 필요합니다(사실 원의 중심 좌표는 항상 (0,0)이기 때문에 여기에서는 생략해도 무방합니다).

여기서 파이의 왼쪽 사이드 각은 theta1, 오른쪽 사이드 각은 theta2를 이용하여 가져옵니다(line 34).
그리고 원의 중심 좌표와 반지름을 center와 r을 이용하여 가져옵니다(line 35).
그리고 텍스트가 표시될 곳의 좌표값은 아래와 같이 계산합니다(line 38~44).
1) 비율이 상한선보다 작거나 같은 경우
텍스트 x좌표 = (반지름/2 + 텍스트 간격 X 순서) X cos{(오른쪽 사이드각+왼쪽 사이드 각)/2} + 중심 x좌표
텍스트 y좌표 = (반지름/2 + 텍스트 간격 X 순서) X sin{(오른쪽 사이드각+왼쪽 사이드 각)/2} + 중심 y좌표
2) 비율이 상한선보다 큰 경우
텍스트 x좌표 = (반지름/2) X cos{(오른쪽 사이드각+왼쪽 사이드 각)/2} + 중심 x좌표
텍스트 y좌표 = (반지름/2) X sin{(오른쪽 사이드각+왼쪽 사이드 각)/2} + 중심 y좌표
이제 코드를 실행해 볼까요?
보시는 바와 같이 텍스트가 겹치지 않게 잘 나온 것을 확인할 수 있습니다. 이 방법은 데이터가 정렬되어 있을 때 사용하면 좋습니다.
Annotation을 이용하기
다음 방법은 Matplotlib에서 제공하는 annotation함수를 이용하여 텍스트를 겹치지 않게 만들어보겠습니다. 이 방법은 위에서 소개한 계단형으로 배치하는 방법과는 달리 데이터가 정렬되어 있지 않아도 쓸 수 있는 방법입니다.
꽁냥이의 전략은 다음과 같아요.
1. Annotation으로 표시할 텍스트의 비율 상한선을 정합니다.
2. Annotation의 시작점과 텍스트가 표시될 위치의 좌표를 정해줍니다(아래 그림 참고).

자 이제 전략을 알았으니 코드로 구현해볼까요?
import matplotlib.pyplot as plt
import numpy as np
## 데이터 준비
colors = ['red','yellow','purple','burlywood','lightcoral'] ## 색상
labels = ['Apple','Banana','Grape','Pear','Peach'] ## 라벨
frequency = [20,3,71,3,3] ## 빈도
fig = plt.figure(figsize=(8,8)) ## 캔버스 생성
fig.set_facecolor('white') ## 캔버스 배경색을 하얀색으로 설정
ax = fig.add_subplot() ## 프레임 생성
pie = ax.pie(frequency, ## 파이차트 출력
startangle=90, ## 시작점을 90도(degree)로 지정
counterclock=False, ## 시계방향으로 그려짐
colors = colors, ## 색상 지정
)
total = np.sum(frequency) ## 빈도수 합
threshold = 5 ## 상한선 비율
sum_pct = 0 ## 퍼센티지
bbox_props = dict(boxstyle='square',fc='w',ec='w',alpha=0) ## annotation 박스 스타일
## annotation 설정
config = dict(arrowprops=dict(arrowstyle='-'),bbox=bbox_props,va='center')
for i,l in enumerate(labels):
ang1, ang2 = ax.patches[i].theta1, ax.patches[i].theta2 ## 파이의 시작 각도와 끝 각도
center, r = ax.patches[i].center, ax.patches[i].r ## 원의 중심 좌표와 반지름길이
if i < len(labels) - 1:
sum_pct += float(f'{frequency[i]/total*100:.2f}')
text = f'{frequency[i]/total*100:.2f}%'
else: ## 마지막 파이 조각은 퍼센티지의 합이 100이 되도록 비율을 조절
text = f'{100-sum_pct:.2f}%'
## 비율 상한선보다 작은 것들은 Annotation으로 만든다.
if frequency[i]/total*100 < threshold:
ang = (ang1+ang2)/2 ## 중심각
x = np.cos(np.deg2rad(ang)) ## Annotation의 끝점에 해당하는 x좌표
y = np.sin(np.deg2rad(ang)) ## Annotation의 끝점에 해당하는 y좌표
## x좌표가 양수이면 즉 y축을 중심으로 오른쪽에 있으면 왼쪽 정렬
## x좌표가 음수이면 즉 y축을 중심으로 왼쪽에 있으면 오른쪽 정렬
horizontalalignment = {-1: "right", 1: "left"}[int(np.sign(x))]
connectionstyle = "angle,angleA=0,angleB={}".format(ang) ## 시작점과 끝점 연결 스타일
config["arrowprops"].update({"connectionstyle": connectionstyle}) ##
ax.annotate(text, xy=(x, y), xytext=(1.5*x, 1.2*y),
horizontalalignment=horizontalalignment, **config)
else:
x = (r/2)*np.cos(np.pi/180*((ang1+ang2)/2)) + center[0] ## 텍스트 x좌표
y = (r/2)*np.sin(np.pi/180*((ang1+ang2)/2)) + center[1] ## 텍스트 y좌표
ax.text(x,y,text,ha='center',va='center',fontsize=12)
plt.legend(pie[0],labels,loc='upper right') ## 범례
plt.show()
위 코드를 앞서 소개한 2단계로 나누어 설명하겠습니다. 여기서 설명하지 않는 부분은 주석을 참고하시길 바랍니다. 또한 annotation함수의 사용법이 궁금하신 분들은 여기를 참고하세요.
1. Annotation으로 표시할 텍스트의 비율 상한선을 정합니다.
line 21
꽁냥이는 5%로 정했습니다.
2. Annotation의 시작점과 텍스트가 표시될 위치의 좌표를 정해줍니다
line 42~43
Annotation의 시작점 좌표를 구해줍니다.
line 50
annotation함수의 xytext 인자를 이용하여 텍스트가 표시될 위치의 좌표를 정해줍니다.
이제 위 코드를 실행해보겠습니다.

텍스트가 잘 표시되는 것을 확인할 수 있습니다.
이번 포스팅에서는 파이의 간격이 좁을 때 텍스트 또는 라벨이 겹치게 되는 것을 방지하는 법에 대해서 알아보았습니다. 사실 이러한 텍스트 겹침의 상황은 여러 가지 경우가 있을 수 있는데요. 그렇기 때문에 하나의 방법이 모든 상황에 적절하지 않을 수 있어요. 즉, 상황마다 다른 방법을 적용하는 것이 좋습니다.
궁금하신 점, 잘못된 점, 하고 싶은 말은 댓글로 남겨주세요.
지금까지 꽁냥이의 글을 읽어주셔서 감사합니다.
'데이터 분석 > 시각화' 카테고리의 다른 글
| [도넛 차트(Donut chart)] 2. Matplotlib을 이용하여 하위 그룹을 포함하는 도넛 차트(Nested donut chart) 그리기 (2) | 2020.09.12 |
|---|---|
| [도넛 차트(Donut chart)] 1. Matplotlib을 이용한 도넛 차트 그리기 (0) | 2020.09.06 |
| [파이 차트(Pie chart)] 7. Matplotlib을 이용하여 파이 차트 꾸미기 - 파이 차트에 테두리 추가하기 (0) | 2020.08.04 |
| [파이 차트(Pie chart)] 6. Matplotlib을 이용하여 파이 차트 꾸미기 - 색상 바꾸기 (0) | 2020.07.31 |
| [파이 차트(Pie chart)] 5. Matplotlib을 이용하여 파이차트 꾸미기 - 범례 표시하기 (2) | 2020.07.28 |





댓글