이번 포스팅에서는 정규 표현식 패턴의 기본이라고 할 수 있는 메타 문자에 대해서 알아보려고 한다.
- 목차 -
1. 메타 문자란?
메타 문자는 단순 문자가 아닌 다른 용도로 사용되는 문자를 말하며 단일 문자 또는 백 슬래쉬 '\' + 단일 문자의 형태로 사용된다.
메타 문자는 검사 범위를 지정(자동 또는 수동)하거나 수량 그리고 검사 위치를 나타내는 등 그 기능에 따라 세부적인 분류를 할 수 있다.

이제 이러한 메타 문자들의 기능을 파이썬 코드와 함께 알아보자.
2. 검사 범위가 자동 지정 메타 문자
메타 문자 중에는 검사 범위가 자동으로 지정된 것들이 있는데 아래 표는 이러한 메타 문자를 나타낸 것이다.
re 모듈을 이용하여 해당 메타 문자의 기능을 실제로 확인해보자.
import re string = ''' Hi? 12790 !@#$&*()_+-=[/?><,. ''' pattern_list = ['.', '\s', '\S', '\d', '\D', '\w', '\W'] for pattern in pattern_list: match_string_list = re.findall(pattern, string) if len(match_string_list) > 0: ## print('패턴 :', pattern, '매칭 문자열 리스트 :', set(match_string_list)) ## 매칭되는 문자열 출력 else: print('No Matched')
메타 문자 콤마 '.'는 줄 바꿈 문자(\n)를 매칭하지 못하는 것을 알 수 있고 \W는 \w가 검사할 수 있는 언더바 '_'를 검사하지 못하는 것도 확인할 수 있다.
3. 수량 지정 메타 문자
앞에서 살펴본 검사 범위가 자동으로 지정된 메타 문자는 범위가 어찌 되었던 문자 한 개의 매칭 결과를 보여준다. 따라서 두 개 이상의 단어를 찾고 싶을 때에는 앞에서 살펴본 메타 문자만으로는 해결할 수 없다. 하지만 수량 메타 문자를 이용하면 해결할 수 있다. 수량 메타 문자는 특정 패턴의 수량을 결정할 수 있게 해 주며 패턴 뒤에 수량자를 나타낸다.
수량 메타 문자는 다음과 같다.
예를 들어 다음과 같은 패턴과 그 의미를 살펴보면 다음과 같다.
이때 문자 0개라는 말은 특정 패턴이 없어도 된다는 뜻이다. 여기서 문제가 되는건 '몇 개 이상'이라는 말인데 '이상'의 뜻은 상한선이 없다는 뜻이며 이는 패턴을 무한정 찾겠다는 뜻이다. 사실 메모리 제한으로 인해서 2억 번 정도만 찾는다고 한다. 또한 메타 문자에 포함되지 않는 문자를 만나게 되면 패턴 찾기를 종료할 수도 있다. 예를 들어 '.*'은 메타 문자 '.'이 줄 바꿈 문자(\n)를 포함하지 않으므로 줄 바꿈 문자를 만나면 패턴 찾기를 종료하는 것이다.
re 모듈을 이용하여 해당 메타 문자의 기능을 실제로 확인해보자.
string = '''xy x\ny xay xaby xaaay xaaaay xaabbbbs''' pattern_list = ['x.y', 'x.*', 'x.+', 'x.?y', 'x.{3}y', 'x.{3,}y', 'x.{,2}y' , 'x.{3,4}y'] for pattern in pattern_list: match_string_list = re.findall(pattern, string) if len(match_string_list) > 0: ## print('패턴 :', pattern, '매칭 문자열 리스트 :', set(match_string_list)) ## 매칭되는 문자열 출력 else: print('패턴 :', pattern,'No Matched')
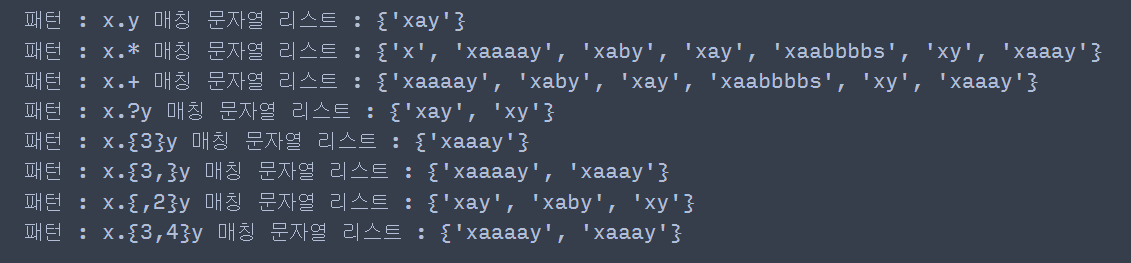
이때 x.?y에서 xy는 매칭이 되지만 줄 바꿈 문자가 포함된 x\ny는 매칭되지 않는 것을 주목하자. 메타 문자 '.'은 줄 바꿈 문자를 포함하지 않으므로 패턴 찾기가 종료되어 x\ny를 매칭하지 못하는 것이다.
4. 검사 범위 수동 지정 메타 문자
각 괄호 '[ ]'나 둥근 괄호 '()' 그리고 '|'를 이용하여 검사 범위를 수동으로 지정할 수 있다. 아래표는 이러한 메타 문자들의 사용 예시를 나타낸 것이다. 특히 둥근 괄호 '()'로 이루어진 패턴을 패턴 그룹이라 한다. 개별 문자에 대하여 검사하는 것이 아닌 괄호 안에 있는 문자들을 그룹별로 검사하기 때문이다.

아래는 위 표에 있는 패턴을 이용하여 어떤 문자를 매칭하는지 확인하는 코드이다.
import re string = '''xyz x\ny a bb xyzxyz xz xaaaay xaabbbbs''' pattern_list = ['[xyz]', '[^xyz]', '(xyz)', '(?:xyz)', 'x|yz'] for pattern in pattern_list: match_string_list = re.findall(pattern, string) if len(match_string_list) > 0: ## print('패턴 :', pattern, '매칭 문자열 리스트 :', set(match_string_list)) ## 매칭되는 문자열 출력 else: print('패턴 :', pattern,'No Matched')

검사 범위 수동 지정 메타 문자는 서로 결합할 수 있으며 수량 메타 문자와도 결합하여 사용할 수 있다.
import re string = '''xyz xz xy yz''' pattern_list = ['[xyz]+', ## xyz로 이루어진 문자 한개 이상 '[^xyz]?', ## xyz가 아닌 모든 문자 0개 또는 1개 '(x|y)z', ## xz나 yz가 매칭된 경우 첫 번째 그룹 x, y 출력 '(?:x|y)z', ## xz 또는 yz '(?:[xy])z', ## xz 또는 yz ] for pattern in pattern_list: match_string_list = re.findall(pattern, string) if len(match_string_list) > 0: ## print('패턴 :', pattern, '매칭 문자열 리스트 :', set(match_string_list)) ## 매칭되는 문자열 출력 else: print('패턴 :', pattern,'No Matched')

5. 검사 위치 메타 문자
정규 표현식에는 패턴 검사 위치를 지정하는 메타 문자들이 있으며 다음과 같다.
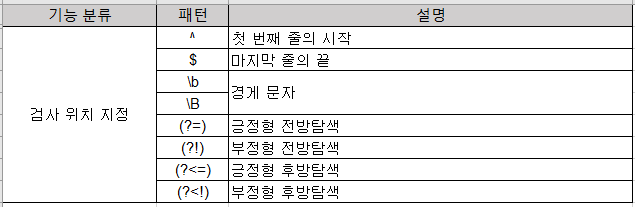
1) 문자열의 시작과 끝을 책임진다 : ^, *
먼저 아래 코드에서 ^(abc)는 문자열 첫 번째 줄이 abc로 시작되는지 검사한다. 그리고 (abc)$는 문자열 마지막 줄이 abc로 끝나는지 검사한다.
pattern_list = ['^(abc)', ## abc로 시작하는가 '(abc)$' ## abc로 끝나는가? ] string_list = ['abc', ' abc', 'ddabc '] for pattern in pattern_list: print('패턴 :', pattern) for string in string_list: match_string = re.search(pattern, string) if match_string is not None: ## 매칭이 됐다면 print('Matched', '매칭 문자열 :', string) else: print('No Matched', '매칭 문자열 :', string) print()

2) 경계는 우리가 맡는다! : \b, \B
경계를 나타내는 메타 문자 \b, \B는 \bz(또는 z\b)나 \B\w(또는 \w\B)처럼 그 옆에 문자나 메타 문자 하나를 추가하여 사용한다.
\b(문자)(예 : \bz)의 의미는 문자가 \w에 속하면 그 왼쪽에 \W(\w가 아닌 모든 문자)이 있는 문자열을 검색하고 반대로 \W에 속하면 그 왼쪽에 \w(\W가 아닌 모든 문자)가 있는 문자열을 검색한다.
다음은 \bz와 z\b 패턴을 검사한 것이다.
pattern_list = [r'\bz', r'\s\b' ] string_list = ['!! z', 'aa\tzz', 'xz', 'zy', 'z '] for pattern in pattern_list: print('패턴 :', pattern) for string in string_list: match_string = re.search(pattern, string) if match_string is not None: ## 매칭이 됐다면 print('Matched', '매칭 문자열 :', string) else: print('No Matched', '매칭 문자열 :', string) print()
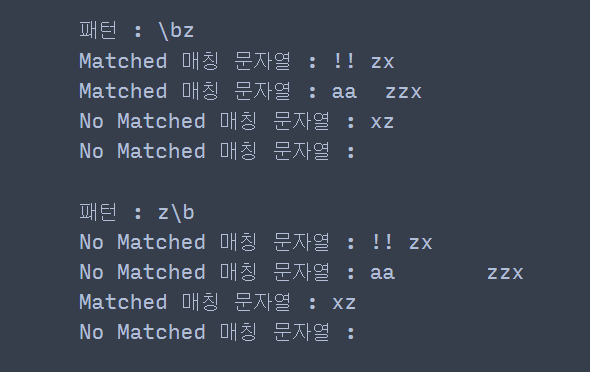
패턴 \bz에서 z는 \w의 검사 범위에 포함된다. 따라서 \b는 \w에 포함되지 않는 즉, \W가 z 왼쪽에 있는지 검사하게 된다. 이때 !! zx에서 z 왼쪽에 공백이 있고 공백은 \W에 포함되므로 패턴 매칭이 이루어진 것이다. aa\tzzx도 z 왼쪽에 공백 문자 \t이 있는데 \t 또한 \W에 포함되므로 패턴 매칭이 이루어졌다.
z\b에서 z는 \w의 검사 범위에 포함된다. 따라서 \b는 \w에 포함되지 않는 즉, \W가 z 오른쪽에 있는지 검사하게 된다. 따라서 z오른쪽에 공백 문자가 포함된 'xz '를 매칭하게 된다.
이제 \B를 알아보자. \B(문자)(예 : \Bz)의 의미는 문자가 \w에 속하면 그 왼쪽에 \w에 포함되는 문자가 존재하면 매칭하고 반대로 \W에 속하면 그 왼쪽에 \W가 있는 문자열을 매칭한다.
\b(문자)는 문자의 반대 속성이 왼쪽에 있는지를 검사하고 \B(문자)는 문자와 같은 속성이 왼쪽에 있는지를 검사한다고 이해하면 된다.
다음은 \Bz, \s\B 패턴으로 문자열을 검사한 것이다.
pattern_list = [r'\Bz', r'\s\B' ] string_list = ['aa\tzzx', 'az !!', ' a'] for pattern in pattern_list: print('패턴 :', pattern) for string in string_list: match_string = re.search(pattern, string) if match_string is not None: ## 매칭이 됐다면 print('Matched', '매칭 문자열 :', string) else: print('No Matched', '매칭 문자열 :', string) print()
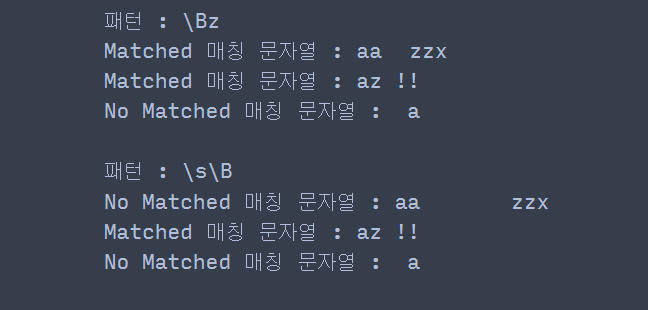
\Bz에서 z는 \w에 포함되므로 왼쪽에도 \w에 포함되는 문자열이 있는지 본 것이다. aa\tzzx는 두 번째 z 왼쪽에 (\w에 포함되는) z가 있으므로 매칭됐고, az !!는 z왼쪽에 (\w에 포함되는) a가 있으므로 이 역시 매칭되었다.
\s\B에서 \s(공백 문자)는 \W에 포함되므로 오른쪽에도 \W에 포함되는 문자가 있는지 본 것이다. az !!는 \s 오른쪽에 (\W에 포함되는) !가 있으므로 매칭된 것이다.
3) 전방은 우리에게 맡겨라! 전방 탐색 : (?=), (?!)
정규 표현식에서 패턴 검사는 왼쪽에서 오른쪽으로 진행한다. 따라서 문자열의 오른쪽이 전방이 되고 왼쪽이 후방이 된다.

전방 탐색에는 긍정형과 부정형이 있다.
a. 긍정형 전방 탐색
긍정형 전방 탐색은 '패턴1(?=패턴2)'와 같은 형태를 말하며 '패턴2'로 끝나는 패턴1을 매칭한다.
pattern = r'x(?=!)'## 느낌표로 끝나는 x찾기 string_list = ['xx', 'x!'] print('패턴 :', pattern) for string in string_list: match_string = re.search(pattern, string) if match_string is not None: ## 매칭이 됐다면 print('Matched', '매칭 문자열 :', string) else: print('No Matched', '매칭 문자열 :', string)

b. 부정형 전방 탐색
부정형 전방 탐색은 '패턴1(?!패턴2)'와 같은 형태를 말하며 '패턴2'로 끝나는 않는 패턴1을 매칭한다. 이제 부정형과 긍정형이 왜 붙었는지 알았을 것이다. 해당 패턴으로 끝나지 않는 것을 찾는 것은 부정적이라 부정형이고 해당 패턴으로 끝나는 것을 찾는 것은 긍정적이라 긍정형인 것이다.
pattern = r'x(?!!)'## 느낌표로 끝나지 않는 x찾기 string_list = ['xx', 'x!'] print('패턴 :', pattern) for string in string_list: match_string = re.search(pattern, string) if match_string is not None: ## 매칭이 됐다면 print('Matched', '매칭 문자열 :', string) else: print('No Matched', '매칭 문자열 :', string)

4) 후방을 주의하라! 후방 탐색 : (?<=), (?<!)
후방 탐색에도 긍정형 후방 탐색과 부정형 후방 탐색이 있다.
a. 긍정형 후방 탐색
긍정형 후방 탐색은 '(?<=패턴1)패턴2'와 같은 형태를 말하며 '패턴1'로 시작하는 패턴2를 매칭한다.
pattern = r'(?<=x)!'## x로 시작하는 느낌표 찾기 string_list = ['z!', 'x!'] print('패턴 :', pattern) for string in string_list: match_string = re.search(pattern, string) if match_string is not None: ## 매칭이 됐다면 print('Matched', '매칭 문자열 :', string) else: print('No Matched', '매칭 문자열 :', string)

b. 부정형 후방 탐색
부정형 후방 탐색은 '(?<!패턴1)패턴2'와 같은 형태를 말하며 '패턴1'로 시작하지 않는 패턴2를 매칭한다.
pattern = r'(?<!x)!'## x로 시작하지 않는 느낌표 찾기 string_list = ['z!', 'x!'] print('패턴 :', pattern) for string in string_list: match_string = re.search(pattern, string) if match_string is not None: ## 매칭이 됐다면 print('Matched', '매칭 문자열 :', string) else: print('No Matched', '매칭 문자열 :', string)

※ 참고 ※
전방 탐색과 후방 탐색은 계산량에서 차이가 있다. 전방 탐색은 왼쪽에서 오른쪽 방향으로 자연스럽게 패턴 검사를 하지만 후방 탐색은 오른쪽 왼쪽 왕복하여 패턴을 검사하므로 후방 탐색이 계산량이 더 많다. 따라서 실시간으로 처리해야 하는 시스템에서는 후방 탐색이 좋지 않다고 한다.
- 참고자료 -
강명훈 - "데이터 분석이 쉬워지는 정규 표현식"
점프 투 파이썬 - "07-2 정규 표현식 시작하기"
'프로그래밍 > 정규표현식' 카테고리의 다른 글
| [정규 표현식] re 모듈 알아보기 (3) finditer 사용법과 findall과의 차이 (0) | 2022.10.01 |
|---|---|
| [정규 표현식] 역 참조(Back reference) 알아보기 (0) | 2022.10.01 |
| [정규 표현식] re 모듈 알아보기 (2) 대체하기 (feat. re.sub) (0) | 2022.09.30 |
| [정규 표현식] 알파벳 패턴 대소문자 상관없이 매칭하기 (feat. (?i), re.IGNORECASE) (0) | 2022.09.18 |
| [정규 표현식] re 모듈 알아보기 (1) 패턴 찾기 (feat. re.match, re.search, re.findall) (0) | 2022.09.18 |





댓글