Scikit-Learn에서 AdaBoostClassifier, AdaBoostRegressor 클래스 사용 시 기본 학습기를 트리 모형으로 적용한 경우에 shap.TreeExplainer 사용을 생각해볼 수 있다. 하지만 당연히 될 줄 알았는데 아래와 같은 오류가 났었다.

따라서 이번 포스팅에서는 이에 대한 해결 방법을 알아보고자 한다.
오류 현상 확인
먼저 위 스샷의 오류가 어떻게 발생되었느지 살펴보자. 붓꽃 데이터를 이용하여 AdaBoost 분류 모형을 학습했다.
import shap
from sklearn.ensemble import AdaBoostClassifier, AdaBoostRegressor
from sklearn.datasets import load_iris, load_boston
iris = load_iris()
X = iris.data
y = iris.target
clf = AdaBoostClassifier().fit(X, y)
그러고 나서 아래와 같이 TreeExplainer를 사용하려고 했다.
tree_explainer = shap.TreeExplainer(clf)
하지만 아래와 같이 에러가 발생한 것이었다.
해결 방법
1. shap 모듈이 설치된 경로 확인
다음과 같이 print를 사용해서 shap 모듈이 설치된 경로를 확인한다.
print(shap)

2. _tree.py 파일 찾기
위에서 찾은 경로로 들어가서 shap 폴더를 찾은 뒤 explainer 폴더에서 _tree.py 파일을 찾고 열어준다.
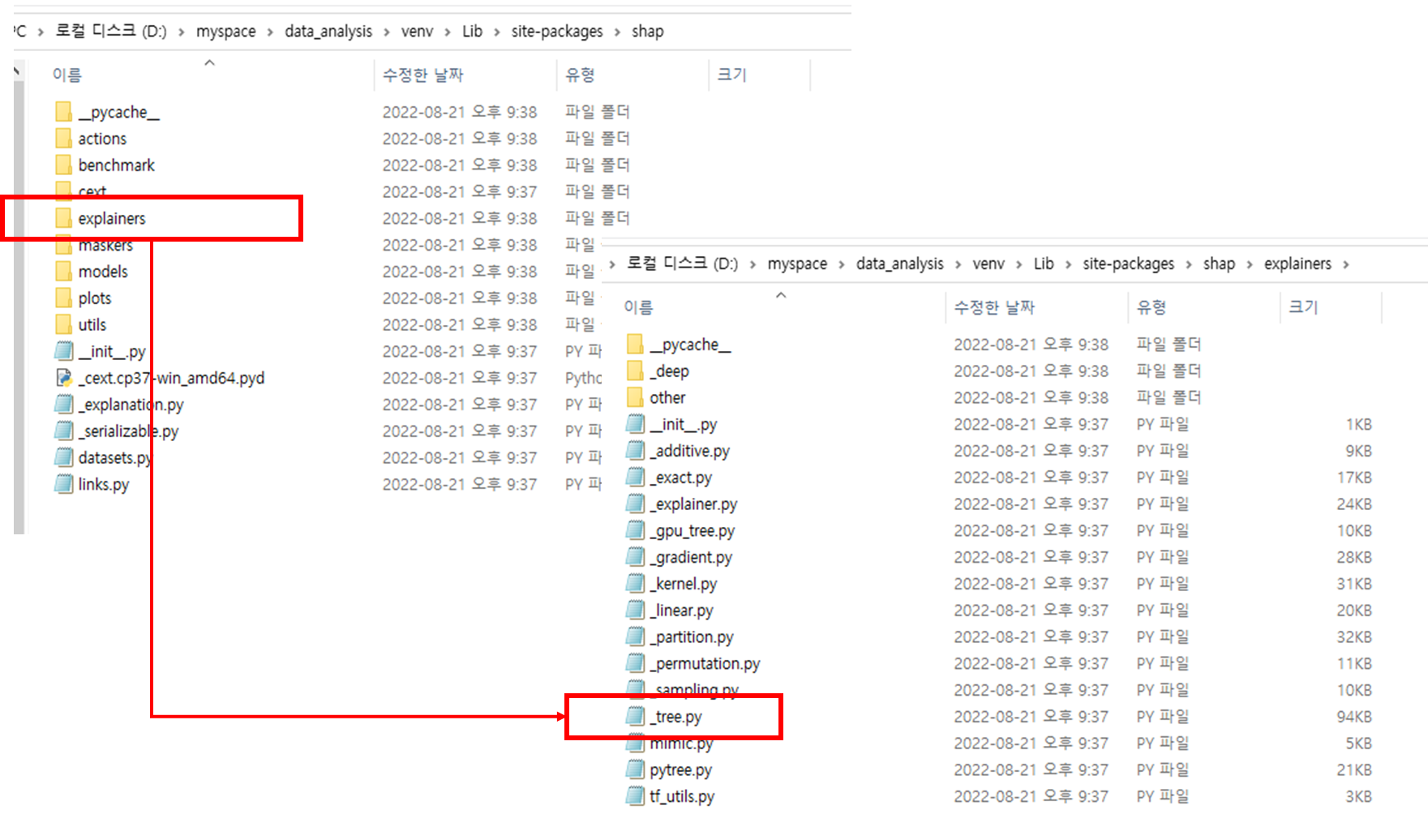
3. _tree.py 파일 수정 및 재실행
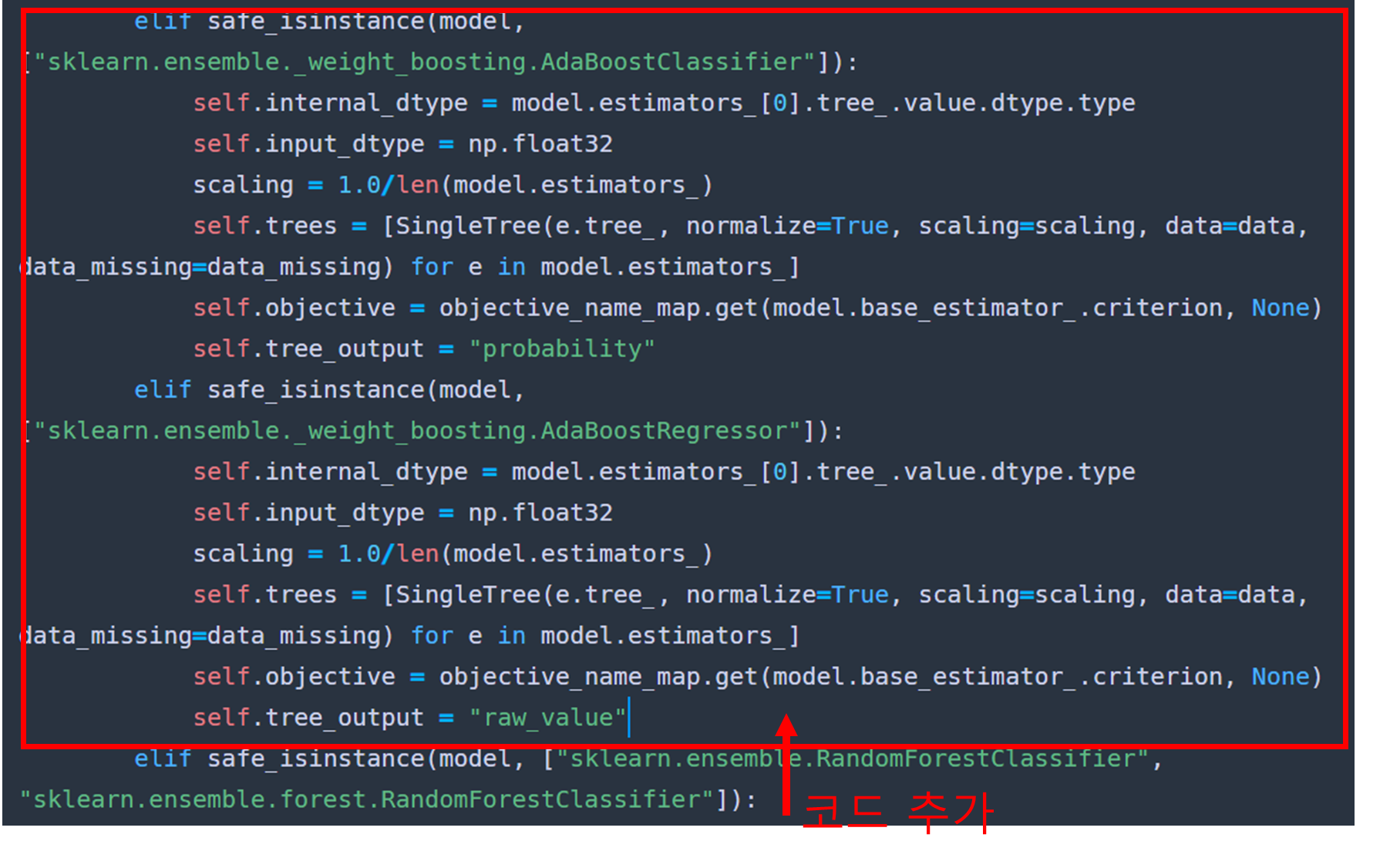
먼저 아래 코드를 복사 한 다음
elif safe_isinstance(model, ["sklearn.ensemble._weight_boosting.AdaBoostClassifier"]):
self.internal_dtype = model.estimators_[0].tree_.value.dtype.type
self.input_dtype = np.float32
scaling = 1.0/len(model.estimators_)
self.trees = [SingleTree(e.tree_, normalize=True, scaling=scaling, data=data, data_missing=data_missing) for e in model.estimators_]
self.objective = objective_name_map.get(model.base_estimator_.criterion, None)
self.tree_output = "probability"
elif safe_isinstance(model, ["sklearn.ensemble._weight_boosting.AdaBoostRegressor"]):
self.internal_dtype = model.estimators_[0].tree_.value.dtype.type
self.input_dtype = np.float32
scaling = 1.0/len(model.estimators_)
self.trees = [SingleTree(e.tree_, normalize=True, scaling=scaling, data=data, data_missing=data_missing) for e in model.estimators_]
self.objective = objective_name_map.get(model.base_estimator_.criterion, None)
self.tree_output = "raw_value"
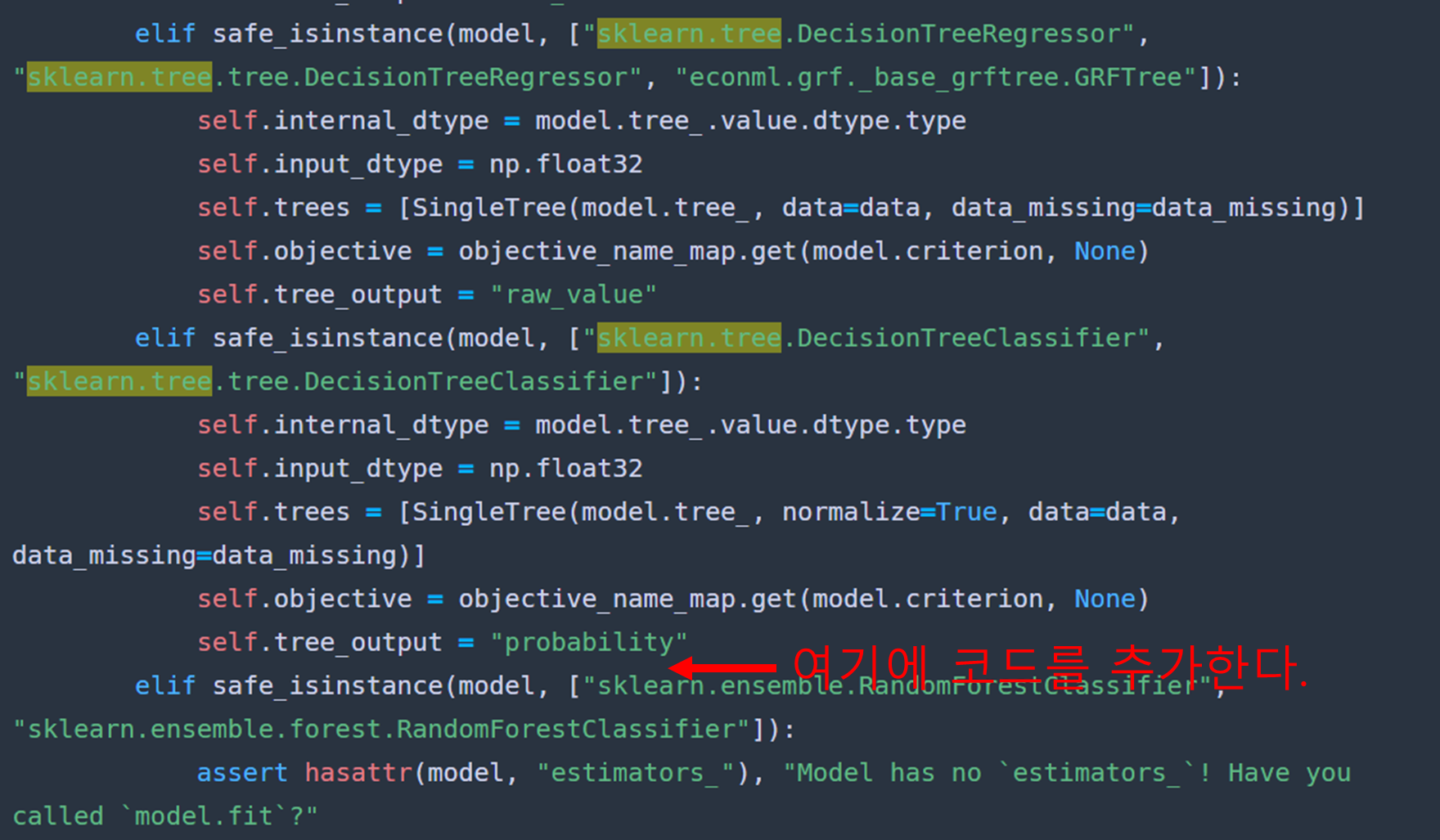
ctrl+F를 실행하여 sklearn.tree를 검색해서 나온 아래 스샷 부분에 해당 코드를 붙여 넣기 한다.
그러고 나서 _tree.py을 저장하고 재실행하게 되면 문제 없이 실행된다.
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(8, 5))
fig.set_facecolor('white')
tree_explainer = shap.TreeExplainer(clf)
shap_values = tree_explainer.shap_values(X)
shap.summary_plot(shap_values, feature_names=iris.feature_names)
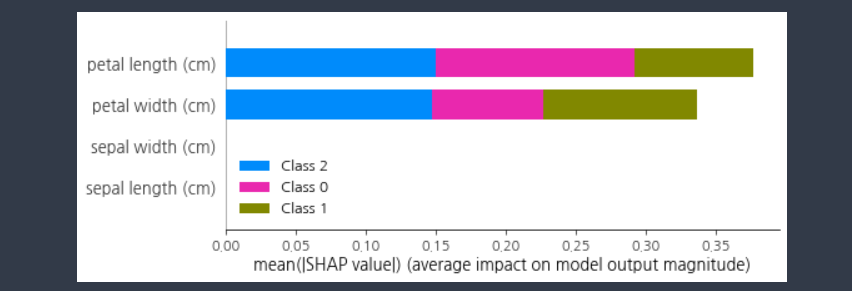
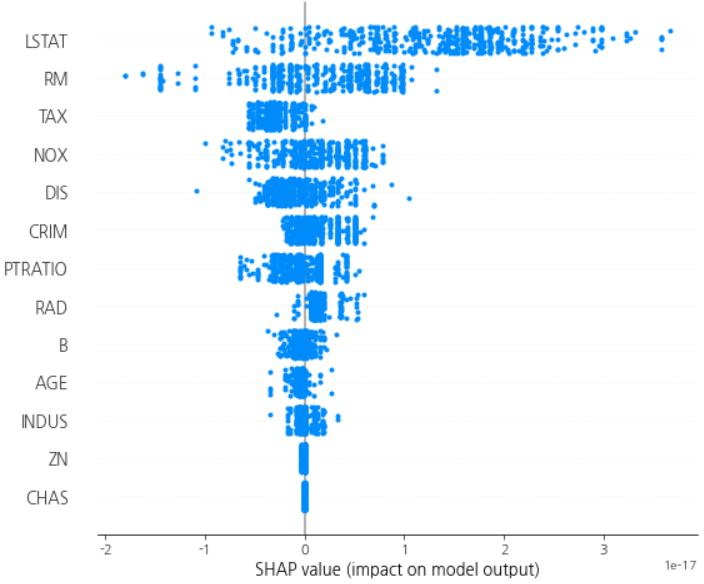
AdaBoostRegressor에 대해서도 잘 작동한다.
import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus'] = False
boston = load_boston()
X = boston.data
y = boston.target
reg = AdaBoostRegressor().fit(X, y)
fig = plt.figure(figsize=(8, 5))
fig.set_facecolor('white')
tree_explainer = shap.TreeExplainer(reg)
shap_values = tree_explainer.shap_values(X)
shap.summary_plot(shap_values, feature_names=boston.feature_names)
'프로그래밍 > 기타 Python 모듈' 카테고리의 다른 글
| [Jupyter Notebook] 주피터 노트북 크롬(Chrome)으로 바로 실행하기 (2) | 2022.10.21 |
|---|---|
| 주피터 노트북( Jupyter Notebook ) 배경 테마, 폰트, 셀 폭( Cell Width ) 설정하기 (2) | 2022.09.21 |
| [Jupyter Notebook] 주피터 노트북 커널(Kernel) 파이썬 경로 확인, 변경 방법 알아보기 (419) | 2022.06.11 |
| [Jupyter Notebook] 주피터 노트북 셀 편집창 폭 조절하기(넓게 하기) (403) | 2022.04.25 |
| [Modin] Pandas 보다 빠른 Modin 소개 (387) | 2022.04.15 |





댓글