안녕하세요~ 꽁냥이에요. 데이터를 전처리할 때 기존 데이터를 다른 데이터로 업데이트해야 할 때가 있지요. 예를 들면 두 데이터가 있다고 했을 때 둘 중 작은 값으로 업데이트하는 것처럼요. Pandas에서는 combine을 사용하여 데이터를 업데이트할 수 있어요.
이번 포스팅에서는 combine 함수 사용법에 대해서 알아보려고 합니다.
Combine 함수 사용법
1. 데이터 업데이트
먼저 Pandas를 임포트하고 데이터프레임 두 개를 만들어줍시다~
import pandas as pd
df1 = pd.DataFrame({'A': [5, 0], 'B': [2, 4]})
df2 = pd.DataFrame({'A': [1, 1], 'B': [3, 3]})

이제 combine 함수의 사용법은 다음과 같이 업데이트할 데이터와 두 데이터의 칼럼 시리즈를 인자로 받는 함수(func)를 넣어줍니다.
df1.combine( df2, func)
이제 실제로 사용법을 알아볼까요? 아래 코드는 두데이터 중에서 각 칼럼의 합이 작은 쪽으로 업데이트합니다. 이때 take_smaller 함수는 두 데이터의 같은 이름을 가진 칼럼을 인자로 받아서 칼럼의 합이 작은 쪽의 칼럼을 리턴합니다.
take_smaller = lambda s1, s2: s1 if s1.sum() < s2.sum() else s2
df1.combine(df2, take_smaller)

만약 칼럼의 합이 아닌 셀별로 작은 값을 업데이트 하고 싶다면 다음과 같이 해주세요.
df1.combine(df2, np.minimum)
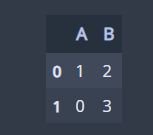
combine 함수는 두 데이터에 있는 모든 칼럼을 포함시킨다는 것을 주목하세요. 이때 두 데이터에서 칼럼이 일치하지 않는 것이 있다면 이를 NaN으로 채워놓고 처리합니다.
df1 = pd.DataFrame({'A': [5, 0], 'B': [2, 4]})
df2 = pd.DataFrame({'A': [1, 1], 'C': [3, 3]})
df1.combine(df2, take_smaller)

위 결과는 아래의 결과와 동일합니다.
df1 = pd.DataFrame({'A': [5, 0], 'B': [2, 4], 'C':[np.nan, np.nan]})
df2 = pd.DataFrame({'A': [1, 1], 'B':[np.nan,np.nan], 'C': [3, 3]})
df1.combine(df2, take_smaller)

fill_value인자를 사용하면 NaN을 10으로 채운 상태로 두 데이터를 업데이트 합니다. 중요한 것은 위의 NaN을 10으로 대체하는 것이 아니라 일치하지 않는 칼럼에 대해서 10으로 채워놓고 업데이트를 한다는 것입니다.
df1.combine(df2, take_smaller, fill_value=10)

위 결과는 df2에 실제로 B 칼럼은 없지만 10, 10을 채워놓고 df1에는 실제로 C 칼럼은 없지만 10, 10을 채워 넣어서 비교한 것입니다. 즉, 위 결과는 아래 코드를 실행한 것과 동일합니다.
df1 = pd.DataFrame({'A': [5, 0], 'B': [2, 4], 'C': [10, 10]})
df2 = pd.DataFrame({'A': [1, 1], 'B': [10, 10], 'C': [3, 3]})
df1.combine(df2, take_smaller)2. 데이터 덮어쓰기
사실 앞에선 combine을 데이터 업데이트용이라고 했지만 사실 덮어쓰는 기능이라고 생각하시면 됩니다. 아래의 두 데이터프레임이 있다고 해볼게요.
df1 = pd.DataFrame({'A': [0, 0], 'B': [4, 4]})
df2 = pd.DataFrame({'B': [3, 3], 'C': [-10, 1], }, index=[1, 2])
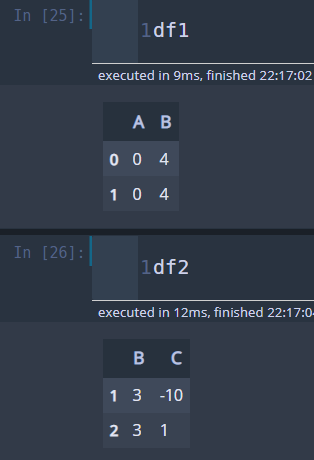
위의 두 데이터프레임은 일치하지 않는 칼럼뿐만 아니라 일치하지 않는 인덱스도 있습니다. 이 경우에는 모든 칼럼과 모든 인덱스가 합쳐지며 각 데이터에서 일치하지 않는 칼럼과 인덱스는 NaN으로 채워진 상태에서 take_smaller 함수가 적용됩니다.
df1.combine(df2, take_smaller)

이 결과가 좀 이상하게 보일 수 있는데요. 위 결과는 아래의 결과와 동일합니다.
df1 = pd.DataFrame({'A': [0, 0, np.nan], 'B': [4, 4, np.nan], 'C' : [np.nan,np.nan,np.nan]})
df2 = pd.DataFrame({'A' : [np.nan,np.nan,np.nan], 'B': [np.nan, 3, 3], 'C': [np.nan, -10, 1]})
df1.combine(df2, take_smaller)
NaN은 Series에서 sum함수를 사용할 때 0으로 처리하기 때문에 두 번째 데이터프레임의 'C' 칼럼의 합이 -9가 되어 더 작으므로 이 칼럼이 덮어씌워 지게 됩니다.

만약 두 데이터프레임의 비교가 아니라 그냥 첫 번째 데이터프레임을 두번째 데이터프레임으로 덮어 쓰고 싶다면 combine_first 함수를 사용하면 됩니다. 아래 코드는 첫 번째 데이터프레임에서 'A', 'B' 열을 두 번재 데이터프레임으로 덮어씁니다.
df1 = pd.DataFrame({'A': [5, 0], 'B': [2, 4], 'C':[1,1]})
df2 = pd.DataFrame({'A': [4, 1], 'B': [3, 3]})
df2.combine_first(df1)

이번 포스팅에서는 combine 함수를 이용하여 데이터를 업데이트하고 덮어쓰는 방법에 대해서 알아보았습니다. 사실 꽁냥이는 combine 함수를 잘 쓰지 않는데 최근에 한번 쓸 일이 있어서 포스팅하게 되었습니다. 부디 도움이 되시는 분이 있길 바라며 이상 포스팅 마치겠습니다. 지금까지 꽁냥이의 글 읽어주셔서 감사합니다.
참고자료
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.combine.html
https://stackoverflow.com/questions/9787853/join-or-merge-with-overwrite-in-pandas

'데이터 분석 > 데이터 전처리' 카테고리의 다른 글
| [Numpy] 1. Numpy 배열 생성하기 (814) | 2021.09.20 |
|---|---|
| [Pandas] 21. 칼럼에 특정 값을 채워 넣기(칼럼 수정하기) (1043) | 2021.07.03 |
| [Pandas Tip] 1. Pandas Tip (1135) | 2021.05.27 |
| [Pandas] 19. concat vs append 성능 차이 알아보기 (1476) | 2021.05.20 |
| [Pandas] 18. 두 날짜 사이의 날짜 생성하기. (0) | 2021.02.22 |





댓글